
Table of contents
Implementation of the five categories
When we stored beans before, we added bean registration content in the spring-config.xml file to achieve

Through "annotation" we can replace this work
A simpler storage method:
Use class annotations
Five categories of annotations:
@Controller (controller): used to control the request submitted by the front end, and verify the correctness of the data requested by the user (security system)
@Service (service): arranges and schedules specific execution methods
@Repository: Persistence layer, interacting with database = DAO (Data Access Object) data access layer
@Component: component, storage tool class
@Configuration: configuration item, configuration in the project
Pre-work
After creating the Spring project, do the pre-work: configure the scan path
To store objects in Spring, you need to configure the scanning path for storing objects. Only all classes under the configured package will be correctly recognized and saved to Spring if annotations are added.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:content="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<content:component-scan base-package="com.aaa.service"></content:component-scan>
</beans> Create a .xml configuration file and paste the above code here

<content:component-scan base-package="com.java.demo"></content:component-scan>
Only the classes under this package will scan whether there are five types of annotations. If this class is not annotated, it will not be added to Spring
However, if the five major categories of annotations are added, the classes that are not under this package will not be stored in Spring
Bean Naming Rules
Create a new class, and then add the class to Spring using annotations
package com.java.demo;
import org.springframework.stereotype.Controller;
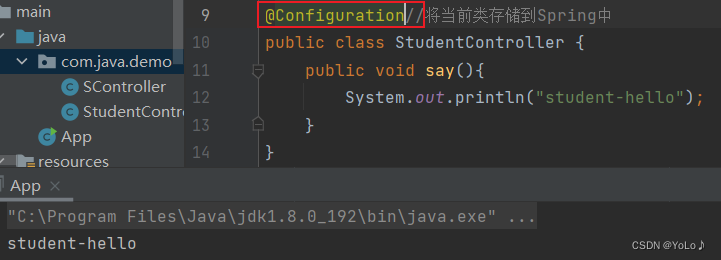
@Controller//将当前类存储到Spring中
public class StudentController {
public void say(){
System.out.println("student-hello");
}
}
import com.java.demo.StudentController;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class App {
public static void main(String[] args) {
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
StudentController studentController =
context.getBean("StudentController",StudentController.class);
studentController.say();
}
}
We use the third type + name mentioned above to get Bean
Try using the class name first, and report an error

Try using the lowercase initials of the original class name and it works.

Then the name needs to use the lowercase form of the original class name, which is a spring convention
What if it is a class name of this form?
package com.java.demo;
public class SController {
public void say(){
System.out.println("SController-hello");
}
}

The bean cannot be obtained by lowercase the first letter of the original class name

rule:
If the first letter of the class name is uppercase and the second letter is lowercase, you can access the original class name in lowercase
If the first letter of the class name is capitalized and the second letter is also capitalized, it can only be accessed in the form of the original class name
We analyze from the perspective of source code, why is such a rule
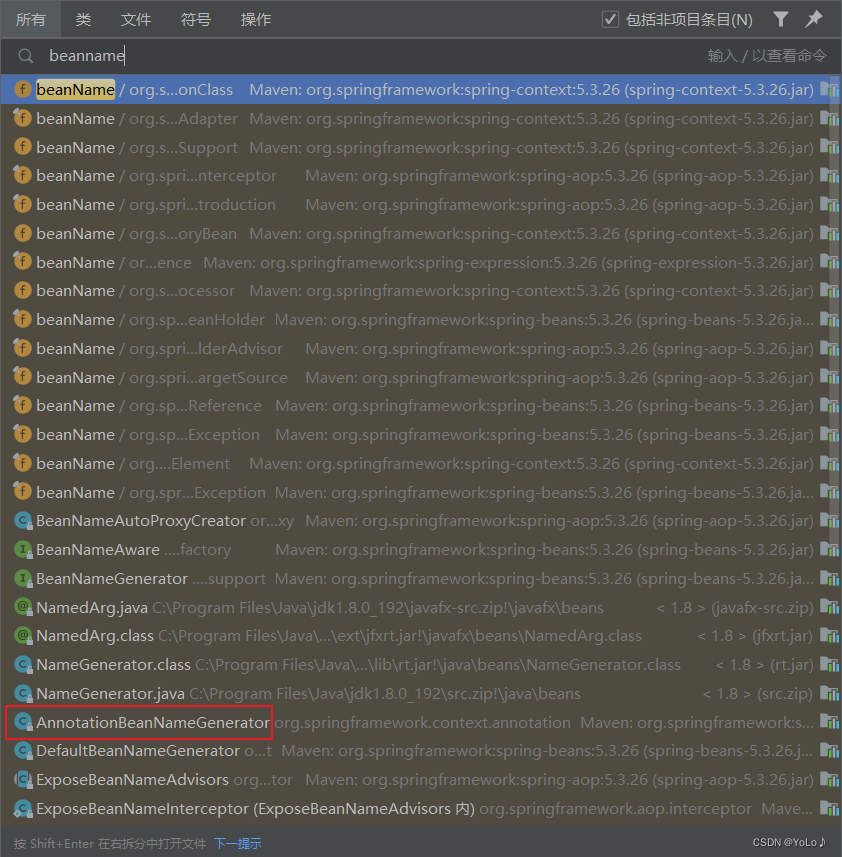



look at this code
If name.length() is greater than 1 and the character with subscript 1 is uppercase and the 0th character is also uppercase, then return name
Corresponding to the second rule
Otherwise, convert the 0th character to lowercase and return
corresponds to the first rule
Bean, naming rules: By default, the first letter is lowercase. If the first letter and the second letter of the class name are both uppercase, the Bean name is the original class name
Let's use this method to test different names
import java.beans.Introspector;
public class BeanNameTest {
public static void main(String[] args) {
String name1 = "USer";
String name2 = "User";
System.out.println("name1 => "+Introspector.decapitalize(name1));
System.out.println("name2 => "+Introspector.decapitalize(name2));
}
}
same as our analysis

Implementation of the five categories
@Controller implements access to Bean

Replace the annotation with @Service
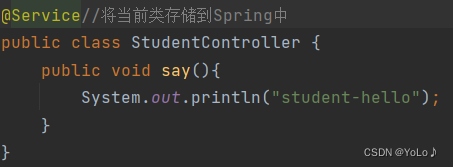
Effect: Bean can also be obtained and used
Changing to @Repository can also succeed

Changing to @Component can also succeed
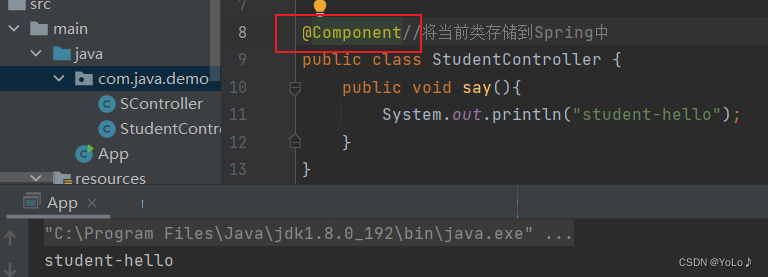
It can also be replaced by @Configuration
These five types of annotations are all easier to store and get Bean
Can the <bean> tag be used with content-scan? Create a new package creation class to try

use bean tag
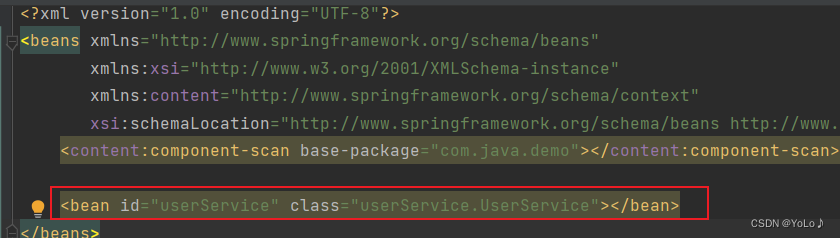 It is successfully executed, indicating that the <bean> tag and content-scan can be used together.
It is successfully executed, indicating that the <bean> tag and content-scan can be used together.
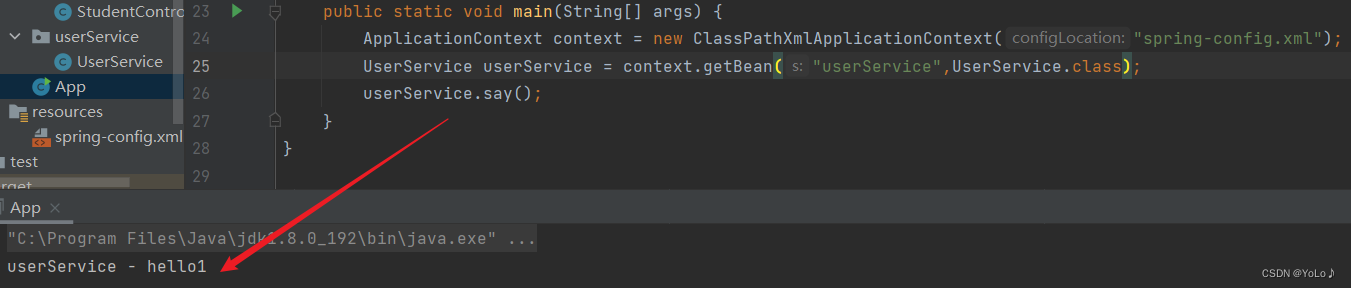
This kind of scenario is that this class is not suitable to be placed under the content-scan scanning package, but if this class is needed, it is configured with a bean tag, which is equivalent to a supplement to content-scan
If you remove the bean tag and add annotations, can you get userService?
That is, if there is no class under the content-scan scanning path, can the Bean be accessed by adding five major categories of annotations?
Look at the result: Although the code does not report an error, the result is that the bean userService cannot be found

So the answer is no!
If it is no longer under the scanning path, it will not be scanned
What if the five categories of annotations are not added under the scanning path?

It is also not possible, even under the scanning path, there are no five types of annotations, and they cannot be stored in Spring
There is another conclusion: If the classes under all subpackages under content-scan can be stored in Spring as long as the five major categories of annotations are added
Suggestion: Do not have classes with the same name, the import package may lead to errors, if an error is reported, you can add an alias to distinguish it
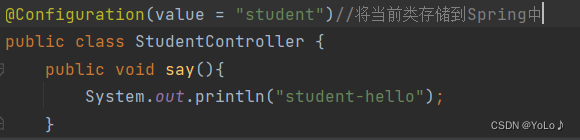
Since the five major types of annotations can store Bean objects, why set five class annotations?
First look at the implementation of each annotation


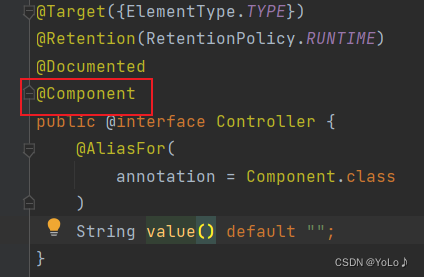
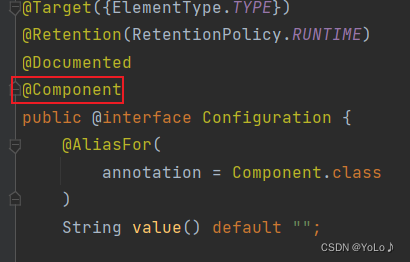
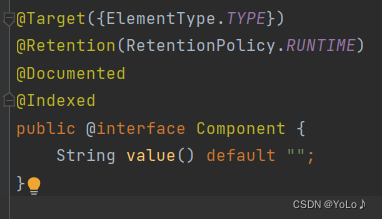
It can be seen that these four annotations are all implemented based on Component, all of which are a subclass of it, and are aimed at the extension of its functions
Back to the question, why do we need five categories of annotations?
JavaEE standard layering
Need to learn JavaEE standard layering first
Why layering?
High cohesion: layered design can simplify system design, allowing different layers to focus on a certain module
Low coupling: Layers interact through interfaces or APIs, and the relying party does not need to know the details of the dependent party
Reuse: High reusability can be achieved after layering
Scalability: layered architecture can make it easier for us to do horizontal expansion
If the system is not layered, we can only expand the overall system when the business scale increases or the traffic increases. After layering, some modules can be easily extracted and become an independent system
JavaEE standard layered at least three layers (back-end three-tier architecture)
1. Request processing layer (verification parameters): business logic layer
2. Business logic layer (service scheduling)
3. Data persistence layer (direct operation database) DAO layer
This layering is the basis of our project
This is Ali's hierarchical standard

Refined the original three-tier architecture and added the Manager general business processing layer
The role of the mannger layer
First, some common capabilities of the original Service layer can be lowered to this layer, such as interaction strategies with cache and storage, and middleware access; Second, calls to third-party interfaces can also be encapsulated at this layer, such as calling RPC interfaces such as payment service and calling audit service.
Advantages: Compared with the three-layer method, a general-purpose processing layer is added to connect to the external platform. The division of upstream and downstream docking is relatively clear
Disadvantages: The core business logic layer is not divided
Adapt to the scene: common business with uncomplicated business logic
Back to the question, why should we set up five categories of annotations?
The role of setting five types of annotations is very clear. For the convenience of programmers, when you see a certain annotation, you will know what level of code is. The bottom layer of these annotations is Component, and the functions are the same. The purpose is to make the program The administrator can know the function of the current class when he sees the annotation!
Method annotations can also store beans: @Bean
I will introduce it later