The kernel code presented in this article comes from Linux5.4.28. If you are interested, readers can read this article with the code.
1. What is load balancing
1. What is CPU load (load)
CPU load is a concept that is easily confused with CPU utilization (utility). CPU utilization is the ratio of CPU busy to idle. For example, observe the CPU in a window with a period of 1000ms. If 500ms is executing tasks and 500ms is idle, then the CPU utilization in this window is 50. %.
When the CPU utilization rate does not reach 100%, the utilization rate is basically equal to the load. Once the CPU utilization rate reaches 100%, the utilization rate cannot actually give the status of the CPU load, because everyone's utilization rate is 100%. %, the utilization rate is equal, but it does not mean that the load of the CPUs is also equal, because the number of tasks waiting to be executed in the runqueue on different CPUs is different at this time. The CPU load of the task is heavier. Therefore, early CPU load is described using runqueue depth.
Obviously, only using runqueue depth to represent CPU load is a very rough concept. We can give a simple example: currently one task is hung on CPU A and CPU B, but the task hung on A is a heavy-duty task , and B hangs a light-load task that often sleeps, then it is biased to describe the CPU load only from the depth of the runqueue. Therefore, modern schedulers often use the sum of the task load on the CPU runqueue to represent the CPU load. In this way, tracking of CPU load becomes tracking of task load.
The 3.8 version of the Linux kernel introduces the PELT algorithm to track the load of each sched entity, and evolves the load tracking algorithm from per-CPU to per-entity. The PELT algorithm can not only know the CPU load, but also know which scheduling entity the load comes from, so that load balancing can be performed more accurately.
2. What is balance
For load balancing, the load of the entire system is not evenly distributed to each CPU in the system. In fact, we still have to consider the computing power of each CPU in the system, so that the CPU can get a load that matches its computing power. For example, in a system with 6 small cores + 2 large cores, if the entire system has a load of 800, then the load of 100 allocated to each CPU is actually unbalanced, because the large core CPU can provide stronger computing power .
What is CPU computing power (capacity), the so-called computing power is to describe the computing power that the CPU can provide. At the same frequency, a CPU whose microarchitecture is A77 is obviously more powerful than an A57 CPU. If the microarchitecture of the CPUs is the same, then a CPU with a maximum frequency of 2.2GHz must have greater computing power than a CPU with a maximum frequency of 1.1GHz. Therefore, once the microarchitecture and maximum frequency are determined, the computing power of a CPU is basically determined. The Cpufreq system will adjust the current operating frequency of the CPU according to the current CPU util, but this does not change the CPU computing power. Only when the maximum operating frequency of the CPU changes (such as triggering temperature control to limit the maximum frequency of the CPU), the computing power of the CPU will change accordingly.
In addition, this article mainly describes the balance of CFS tasks (the balance of RT does not consider the load, it is in another dimension), so when considering the CPU computing power, it is necessary to remove the computing power of the CPU for executing rt and irq, and use this CPU Computing power available for CFS. Therefore, the CPU computing power used in CFS task balancing is actually a constantly changing value that needs to be updated frequently. In order to make the CPU computing power and task load comparable, we actually adopted a normalized method, that is, the computing power of the most powerful CPU running at the highest frequency in the system is 1024, and the computing power of other CPUs is based on the microarchitecture and Adjust its computing power by operating frequency response.
With the task load, you can get the CPU load. With the computing power of each CPU in the system, it seems that we can complete the load balancing work. However, things are not that simple. When the load is unbalanced, tasks need to be migrated between CPUs. , different forms of migration will have different costs. For example, the performance overhead caused by the migration of a task between CPUs in a small-core cluster must be less than the overhead of migrating a task from a CPU in a small-core cluster to a large-core cluster. Therefore, in order to better perform load balancing, we need to build a data structure related to the CPU topology, that is, the concept of scheduling domain and scheduling group.
3. Sched domain (sched domain) and scheduling group (sched group)
The complexity of load balancing is mainly related to the complex system topology. Since the current CPU is very busy, when we migrate a task previously running on this CPU to a new CPU, if the migrated CPU is in a different cluster from the original CPU, the performance will be affected (because it will cache flush).
But for the hyperthreading architecture, the cpu shares the cache, and the task migration between hyperthreads will not have a particularly obvious performance impact. The impact of task migration on NUMA is different. We should try to avoid task migration between different NUMA nodes unless the balance between NUMA nodes reaches a very serious level.
In short, a good load balancing algorithm must adapt to various cpu topologies. In order to solve these problems, the linux kernel introduces the concept of sched_domain.
The struct sched_domain in the kernel describes the scheduling domain, and its main members are as follows:

Once a scheduling domain is formed, load balancing is limited to this scheduling domain. When balancing in this scheduling domain, the CPU load of other scheduling domains in the system is not considered, and only the load between sched groups in this scheduling domain is considered. Is it balanced. For the base domain, there is only one cpu in the sched group to which it belongs, and for a higher level sched domain, there may be multiple cpu cores in the sched group to which it belongs. The struct sched_group in the kernel describes the scheduling group, and its main members are as follows:

The above description is too boring. We will use a specific example later to describe how the load is balanced on each level of sched domain. But before that, let's take a look at the overall software architecture of load balancing.
2. Software architecture of load balancing
The overall software structure diagram of load balancing is as follows:

The load balancing module is mainly divided into two software levels: the core load balancing module and the class-specific balancing module. The kernel has different balancing strategies for different types of tasks. Common CFS (complete fair schedule) tasks are handled differently from RT and Deadline tasks. Due to space limitations, this article mainly discusses the load balancing of CFS tasks.
In order to better balance CFS tasks, the system needs to track task load and CPU load. Tracking task load is important for two main reasons:
(1) Determine whether the task is suitable for the current CPU computing power.
(2) If it is determined that balance is required, how many tasks need to be migrated between CPUs to achieve balance? With the task load tracking module, this question is easier to answer.
The tracking of CPU load should not only consider the load of each CPU, but also aggregate all loads on the cluster to facilitate the calculation of load imbalance between clusters.
In order to perform better and efficient balancing, we also need to build a hierarchical structure of the scheduling domain (sched domain hierarchy). The figure shows the secondary structure. Most mobile phone scenarios have a secondary structure, and server scenarios that support NUMA may form a more complex structure. Through the DTS and CPU topo subsystems, we can build a sched domain hierarchy for specific equalization algorithms.
With the infrastructure described above, when should load balancing be done? This is mainly related to scheduling events. When scheduling events such as task wake-up, task creation, and tick arrival occur, we can check the imbalance of the current system and perform task migration as appropriate to keep the system load in a balanced state.
Information through train: Linux kernel source code technology learning route + video tutorial kernel source code
Learning through train: Linux kernel source code memory tuning file system process management device driver/network protocol stack
3. How to do load balancing
1. A CPU topology example
We use a processor with 4 small cores + 4 large cores to describe the domain and group of the CPU:

In the above structure, the sched domain is divided into two levels, the base domain is called MC domain (multi core domain), and the top-level domain is called DIE domain. The top-level DIE domain covers all CPUs in the system. The MC domain of the small-core cluster includes all CPUs in the small-core cluster. Similarly, the MC domain of the large-core cluster includes all CPUs in the large-core cluster.
For the small core MC domain, there are four sched groups to which it belongs, and cpu0, 1, 2, and 3 form a sched group respectively, forming a sched group ring list of the MC domain.
The first element of the circular linked list of the MC domain of different CPUs (that is, the sched group pointed to by the groups member in the sched domain) is different. For the MC domain of cpu0, the order of the groups circular linked list is 0-1-2-3. For For the MC domain of cpu1, the order of its groups ring list is 1-2-3-0, and so on. The large-core MC domain is also similar, so I won't repeat it here.
For non-base domains, its sched group has multiple cpus, covering all cpus of its child domain. For example, the DIE domain in the above illustration has two child domains, namely the large core domain and the small core domain. Therefore, the groups ring list of the DIE domain has two elements, namely the small core group and the large core group.
The first element of the circular linked list (that is, the head of the linked list) of the DIE domain of different CPUs is different. For the DIE domain of cpu0, the order of the groups circular linked list is (0,1,2,3)--(4,5,6, 7), for the MC domain of cpu6, the order of its groups ring list is (4,5,6,7)--(0,1,2,3), and so on.
In order to reduce lock competition, each CPU has its own MC domain, DIE domain, and sched group, and forms a hierarchical structure between sched domains and a ring list structure of sched groups.
2. The basic process of load balancing
Load balancing is not a global balance between CPUs. In fact, it is unrealistic to do so. When the number of CPUs in the system is large, it is difficult to complete the balance between all CPUs at one time. This is one of the reasons for proposing sched domain one.
When performing load balancing on a CPU, we always start from the base domain (for the above example, the base domain is the MC domain), and check the load balancing between the sched groups to which it belongs (that is, between each CPU), if If there is an unbalanced situation, the migration will be performed between the clusters to which the CPU belongs, so as to maintain the task load balance of each CPU core in the cluster. With the load statistics on each CPU and the computing power information of the CPU, we can easily know the imbalance on the MC domain.
In order to make the algorithm simpler, the load balancing algorithm of the Linux kernel only allows the CPU to pull tasks. In this way, the balancing of the MC domain generally requires the following steps:
(1) Find the busiest sched group in the MC domain;
(2) Find the busiest CPU in the busiest sched group (for MC domain, this step does not exist, after all, its sched group has only one cpu);
(3) Pull tasks from the selected busy CPU. The specific number of tasks pulled to the CPU runqueue is related to the degree of imbalance. The more unbalanced, the more tasks pulled.
After the MC domain balance is completed, continue to check upwards along the sched domain hierarchy and enter the DIE domain. On this level of domain, we still check the load balance between the sched groups to which it belongs (that is, between each cluster). If there is If it is unbalanced, then inter-cluster task migration will be performed. The basic method is similar to that of MC domain, except that when calculating balance, DIE domain no longer considers the load and computing power of a single CPU, it considers:
(1) The load of the sched group, that is, the sum of all CPU loads in the sched group;
(2) The computing power of the sched group, that is, the sum of computing power of all CPUs in the sched group;
2. Other things to consider
The reason for load balancing is mainly for the overall throughput of the system, to avoid the situation where one core is in trouble and seven cores are onlookers. However, load balancing itself requires additional computing power overhead. In order to reduce the overhead, we define time intervals for different levels of sched domains, and load balancing cannot be performed too intensively. In addition, we have also defined the threshold value of imbalance, that is to say, if there is a small imbalance between domain groups, we can also allow it, and the load balancing operation will not be initiated until the threshold value is exceeded. Obviously, the higher the level of the sched domain, the higher the unbalanced threathold, and the higher the level of equalization, the greater the performance overhead.
After the introduction of heterogeneous computing systems, tasks can be selected during placement. If the load is relatively light, or the task does not require high latency, we can place it on a small-core CPU for execution. If the load is relatively heavy or the task is related to user experience, then we tend to let it be executed on a CPU with higher computing power implement. In order to deal with this situation, the kernel introduces the concept of misfit task. Once a task is marked as a misfit task, the load balancing algorithm should consider timely upmigration of the task, so that the overloaded task can be completed as soon as possible, or the execution speed of the task can be improved, thereby improving the user experience.
In addition to performance, load balancing also brings benefits in power consumption. For example, the system has 4 CPUs, and a total of 8 tasks enter the execution state. There are two options for the arrangement of these tasks on the 4 CPUs:
(1) Put all on one CPU;
(2) Each CPU runqueue hangs 2 tasks.
The load balancing algorithm will distribute tasks evenly, thereby bringing power consumption benefits. Although there are three CPUs in the idle state in solution 1, the busy CPU runs at a higher frequency. In Solution 2, due to the uniform distribution of tasks, the CPU runs at a lower frequency, and the power consumption will be lower than that of Solution 1.
4. Analysis of Load Balancing Scenarios
1. Overall scene description
In the Linux kernel, in order to distribute tasks evenly across all CPUs in the system, we mainly consider the following three scenarios:
(1) Load balance (load balance). By moving the tasks on the cpu runqueue, the load on each CPU can match the CPU computing power.
(2) Task placement. When the blocked task is woken up, determine which CPU the task should be placed on.
(3) Active upmigration. When a misfit task appears in the runqueue of a CPU with low computing power, if the task continues to execute, then load balancing is powerless because it is only responsible for migrating tasks in the runnable state. In this scenario, active upmigration can migrate the currently running misfit task upwards to a CPU with higher computing power.
2、Task placement
Task placement mainly occurs in:
(1) Wake up a new fork thread;
(2) When Exec a thread;
(3) Wake up a blocked process.
In the above three scenarios, select_task_rq will be called to select a suitable CPU core for the task.
3、Load balance
There are three main types of load balance:
(1) Trigger load balance in tick. We call it tick load balance or periodic load balance. The specific code execution path is:
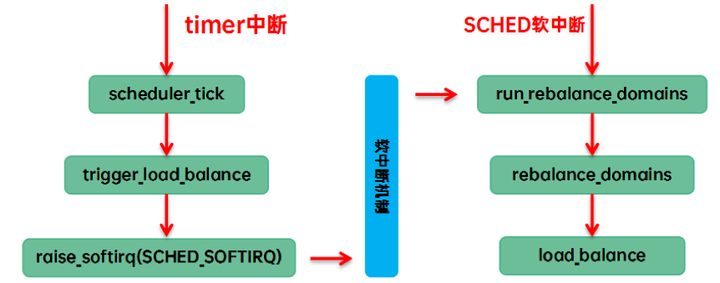
(2) When the scheduler is picking next, there is no runnable in the current cfs runque, and only idle threads can be executed to let the CPU enter the idle state. We call it new idle load balance. The specific code execution path is:

(3) Other cpus have entered idle, and this CPU has too heavy a task, so it needs to wake up its idle cpu through ipi to perform load balancing. We call it idle load banlance, and the specific code execution path is:

If there is no dynamic tick feature, then there is no need to perform idle load balance, because the tick will wake up the idle CPU, so that the periodic tick can cover this scene.
4、Active upmigration
Active migration is a special case of load balance. In load balancing, as long as the appropriate synchronization mechanism is used (holding one or more rq locks), runnable tasks can move between CPU runqueues, but the running task is an exception, it is not hung in the CPU runqueue, load balance cannot be overwritten. In order to be able to migrate tasks in the running state, the kernel provides the Active upmigration method (using the stop machine scheduling class).
