From: Heart of the Machine
Typesetting: Deep Learning Natural Language Processing Official Account
GPT is so simple?
We know that OpenAI's GPT series has opened up a new era of artificial intelligence through large-scale and pre-training methods. However, for most researchers, the language large model (LLM) is unattainable due to its size and computing power requirements. . While technology is developing upwards, people have been exploring the "simplest" GPT model.
Recently, Andrej Karpathy , the former AI director of Tesla, who just returned to OpenAI, introduced the simplest GPT gameplay, which may help more people understand the technology behind this popular AI model.
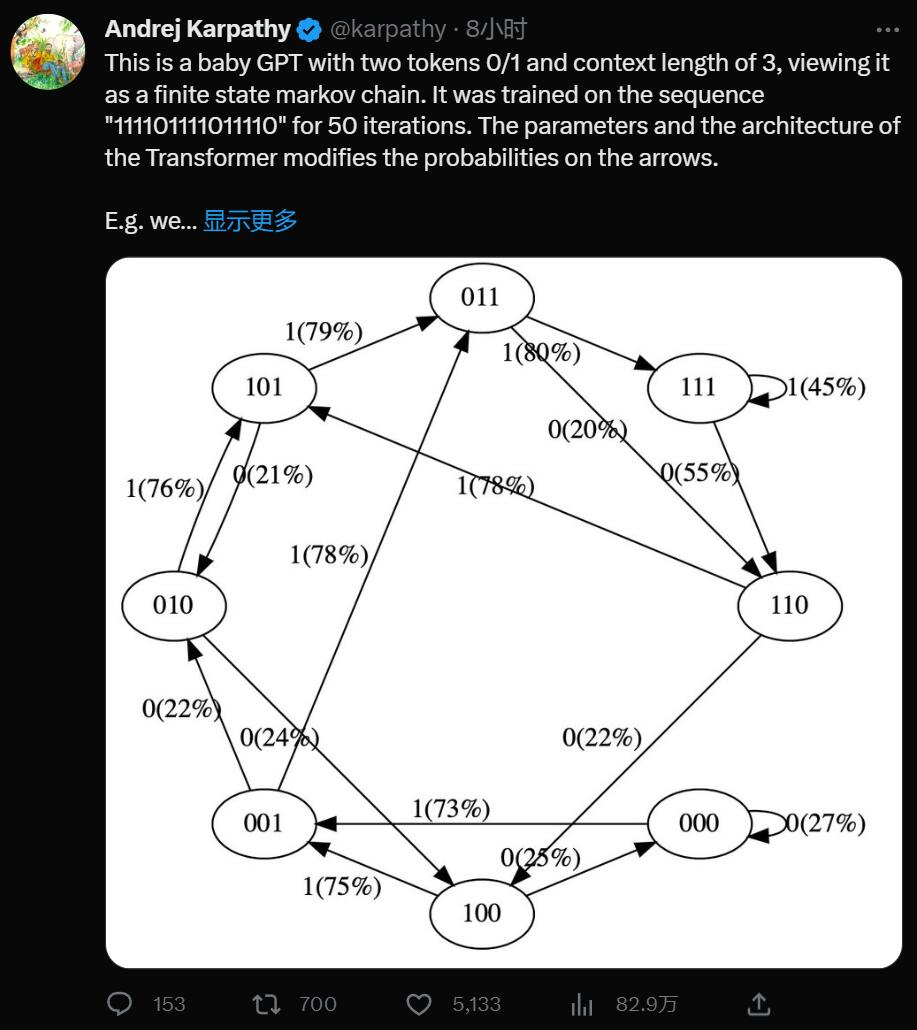
Yes, this is a minimalist GPT with two tokens 0/1 and context length 3, think of it as a finite-state Markov chain . It was trained for 50 iterations on the sequence "111101111011110", with Transformer's parameters and architecture modifying the probabilities on the arrows.
For example we can see:
In the training data, state 101 transitions to 011 deterministically, so the probability of this transition becomes higher (79%). But not close to 100%, because only 50 steps of optimization are done here. State 111 goes to 111 and 110 respectively with 50% probability, which the model has almost learned (45%, 55%).
A state like 000 is never encountered during training, but has relatively sharp transition probabilities, e.g. 73% go to 001. This is a result of Transformer's inductive bias. You might think it's 50%, except that in real deployments almost every input sequence is unique, rather than appearing verbatim in the training data.
Through simplification, Karpathy has made GPT models easy to visualize, allowing you to intuitively understand the entire system.
You can try it here: https://colab.research.google.com/drive/1SiF0KZJp75rUeetKOWqpsA8clmHP6jMg?usp=sharing
In fact, even the original version of GPT, the size of the model is quite considerable: in 2018, OpenAI released the first generation of GPT model, from the paper "Improving Language Understanding by Generative Pre-Training", it can be learned that it uses The 12-layer Transformer Decoder structure uses about 5GB of unsupervised text data for training.
But if you simplify its concept, GPT is a neural network that takes some sequence of discrete tokens and predicts the probability of the next token in the sequence. For example, if there are only two tokens 0 and 1, a tiny binary GPT can for example tell us:
[0,1,0] ---> GPT ---> [P (0) = 20%, P (1) = 80%]Here, GPT takes the bit sequence [0,1,0] and, given the current parameter settings, predicts that the next one will be 1 with an 80% chance. Importantly, GPT's context length is limited by default. If the context length is 3, then they can only use at most 3 tokens on input. In the above example, if we toss a biased coin and sample that 1 should indeed be next, we will transition from the original state [0,1,0] to the new state [1,0,1]. We add new bits on the right (1) and truncate the sequence to context length 3 by discarding the leftmost bit (0), which can then be repeated over and over to transition between states.
It is clear that GPT is a finite-state Markov chain: there is a finite set of states and probabilistic transition arrows between them . Each state is defined by a specific set of tokens at the GPT input (eg [0,1,0]). We can transition it to a new state like [1,0,1] with a certain probability. Let's see how it works in detail:
# hyperparameters for our GPT
# vocab size is 2, so we only have two possible tokens: 0,1
vocab_size = 2
# context length is 3, so we take 3 bits to predict the next bit probability
context_length = 3The input of the GPT neural network is a token sequence with a length of context_length. The tokens are discrete, so the state space is simple:
print ('state space (for this exercise) = ', vocab_size ** context_length)
# state space (for this exercise) = 8Details: To be precise, GPT can take any number of tokens from 1 to context_length. So if the context length is 3, in principle we could input 1, 2 or 3 tokens when trying to predict the next token. We ignore this here and assume the context length is "maximized" just to simplify some of the code below, but it's worth keeping in mind.
print ('actual state space (in reality) = ', sum (vocab_size ** i for i in range (1, context_length+1)))
# actual state space (in reality) = 14We are now going to define a GPT in PyTorch . For the purposes of this notebook, you don't need to understand any of this code.
Now let's build GPT:
config = GPTConfig (
block_size = context_length,
vocab_size = vocab_size,
n_layer = 4,
n_head = 4,
n_embd = 16,
bias = False,
)
gpt = GPT (config)For this notebook you don't have to worry about n_layer, n_head, n_embd, bias, these are just some hyperparameters of the Transformer neural network that implements GPT.
The parameters of GPT (12656) are randomly initialized, and they parameterize the transition probabilities between states. If you change these parameters smoothly, it smoothly affects the transition probabilities between states.
Now let's try a randomly initialized GPT. Let's get all possible inputs to a small binary GPT with context length 3:
def all_possible (n, k):
# return all possible lists of k elements, each in range of [0,n)
if k == 0:
yield []
else:
for i in range (n):
for c in all_possible (n, k - 1):
yield [i] + c
list (all_possible (vocab_size, context_length))[[0, 0, 0],
[0, 0, 1],
[0, 1, 0],
[0, 1, 1],
[1, 0, 0],
[1, 0, 1],
[1, 1, 0],
[1, 1, 1]]These are the 8 possible states that GPT can be in. Let's run GPT on each of these possible token sequences, and get the probability of the next token in the sequence, plotted as a fairly visual graph:
# we'll use graphviz for pretty plotting the current state of the GPT
from graphviz import Digraph
def plot_model ():
dot = Digraph (comment='Baby GPT', engine='circo')
for xi in all_possible (gpt.config.vocab_size, gpt.config.block_size):
# forward the GPT and get probabilities for next token
x = torch.tensor (xi, dtype=torch.long)[None, ...] # turn the list into a torch tensor and add a batch dimension
logits = gpt (x) # forward the gpt neural net
probs = nn.functional.softmax (logits, dim=-1) # get the probabilities
y = probs [0].tolist () # remove the batch dimension and unpack the tensor into simple list
print (f"input {xi} ---> {y}")
# also build up the transition graph for plotting later
current_node_signature = "".join (str (d) for d in xi)
dot.node (current_node_signature)
for t in range (gpt.config.vocab_size):
next_node = xi [1:] + [t] # crop the context and append the next character
next_node_signature = "".join (str (d) for d in next_node)
p = y [t]
label=f"{t}({p*100:.0f}%)"
dot.edge (current_node_signature, next_node_signature, label=label)
return dot
plot_model ()input [0, 0, 0] ---> [0.4963349997997284, 0.5036649107933044]
input [0, 0, 1] ---> [0.4515703618526459, 0.5484296679496765]
input [0, 1, 0] ---> [0.49648362398147583, 0.5035163760185242]
input [0, 1, 1] ---> [0.45181113481521606, 0.5481888651847839]
input [1, 0, 0] ---> [0.4961162209510803, 0.5038837194442749]
input [1, 0, 1] ---> [0.4517717957496643, 0.5482282042503357]
input [1, 1, 0] ---> [0.4962802827358246, 0.5037197470664978]
input [1, 1, 1] ---> [0.4520467519760132, 0.5479532480239868]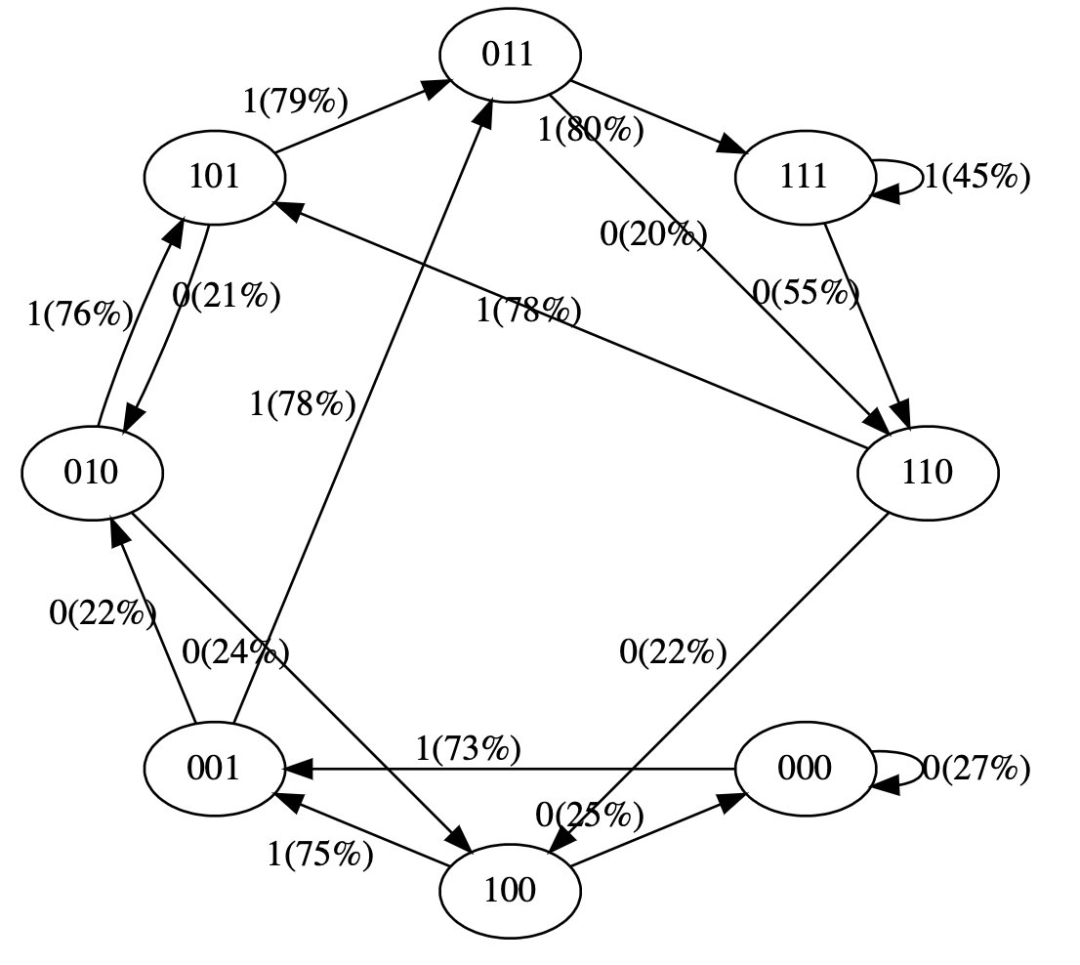
We see 8 states, and the probability arrows connecting them. Since there are 2 possible labels, there are 2 possible arrows for each node. Note that at initialization, most of these probabilities are uniform (50% in this case), which is fine and ideal since we didn't even train the model at all.
Start training below:
# let's train our baby GPT on this sequence
seq = list (map (int, "111101111011110"))
seq[1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0]# convert the sequence to a tensor holding all the individual examples in that sequence
X, Y = [], []
# iterate over the sequence and grab every consecutive 3 bits
# the correct label for what's next is the next bit at each position
for i in range (len (seq) - context_length):
X.append (seq [i:i+context_length])
Y.append (seq [i+context_length])
print (f"example {i+1:2d}: {X [-1]} --> {Y [-1]}")
X = torch.tensor (X, dtype=torch.long)
Y = torch.tensor (Y, dtype=torch.long)
print (X.shape, Y.shape)We can see that there are 12 examples in that sequence. Now let's train it:
# init a GPT and the optimizer
torch.manual_seed (1337)
gpt = GPT (config)
optimizer = torch.optim.AdamW (gpt.parameters (), lr=1e-3, weight_decay=1e-1)# train the GPT for some number of iterations
for i in range (50):
logits = gpt (X)
loss = F.cross_entropy (logits, Y)
loss.backward ()
optimizer.step ()
optimizer.zero_grad ()
print (i, loss.item ())print ("Training data sequence, as a reminder:", seq)
plot_model ()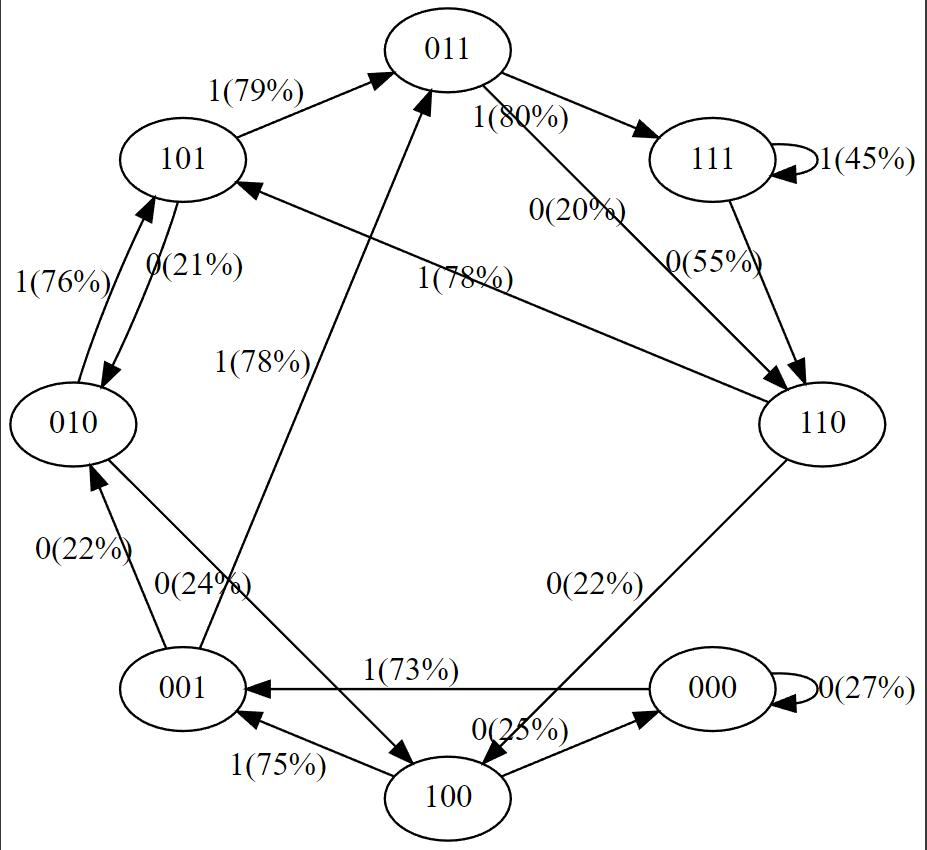
We don't get an exact 100% or 50% probability for these arrows because the network isn't fully trained, but if you keep training, you'd expect to get close.
Note something else interesting : some states that never appear in the training data (such as 000 or 100) have a high probability for the token that should appear next. If these states were never encountered during training, shouldn't their outbound arrows be around 50%? This may seem like a mistake, but it is actually desirable because in a real-world application during deployment, almost every test input to GPT is an input never seen during training. We rely on the internal structure of GPT (and its "inductive bias") to perform generalization appropriately.
Size comparison :
GPT-2 has 50257 tokens and a context length of 2048 tokens. So `log2 (50,257) * 2048 = 31,984 bits per state = 3,998 kB. This is enough to achieve quantitative change.
GPT-3 has a context length of 4096, so requires 8kB of memory; roughly equivalent to an Atari 800.
GPT-4 has a maximum of 32K tokens, so about 64kB, which is Commodore64.
I/O Devices: Once you start including input devices connected to the outside world, all finite state machine analysis breaks down. In the world of GPT, this would be the use of any kind of external tool, such as Bing Search being able to run search queries to obtain external information and incorporate it as input.
Andrej Karpathy is a founding member and research scientist at OpenAI. But more than a year after OpenAI was founded, Karpathy accepted Musk's invitation to join Tesla. During his five years at Tesla, he single-handedly contributed to the development of Autopilot. This technology is crucial to Tesla's fully autonomous driving system FSD, and it is also one of Musk's selling points for Model S, Cybertruck and other models.
In February of this year, under the background of ChatGPT, Karpathy returned to OpenAI, determined to build a real-world JARVIS system.

Recently, Karpathy has contributed a lot of learning materials to everyone, including a detailed course on backpropagation, a rewritten minGPT library, and a complete tutorial on building a GPT model from scratch.
Reference content
https://twitter.com/karpathy/status/1645115622517542913
https://news.ycombinator.com/item?id=35506069
https://twitter.com/DrJimFan/status/1645121358471495680
--
Enter the NLP group —> join the NLP exchange group (remark nips/emnlp/nlpcc enters the corresponding contribution group)
Continue to release the latest information such as interpretation of natural language processing NLP daily high-quality papers, relevant first-hand information, AI algorithm positions, etc.
Join the planet, you will get:
1. Update 3-5 latest and highest-quality paper speed readings every day . In a few seconds , you can grasp the general content of the paper, including a one-sentence summary of the paper, general content, research direction, and pdf download.
2. The latest introductory and advanced learning materials . Including machine learning, deep learning, NLP and other fields.
3. Specific subdivision of NLP directions includes but is not limited to : sentiment analysis, relationship extraction, knowledge graph, syntax analysis, semantic analysis, machine translation, human-computer dialogue, text generation, named entity recognition, reference resolution, large language model, zero sample Learning, small sample learning, code generation, multimodality, knowledge distillation, model compression, AIGC, PyTorch, TensorFlow, etc.
4. Daily 1-3 recruitment information for AI positions such as NLP, search, promotion and promotion, and CV . Mock interviews can be arranged.
