Recently, ChatGPT has become popular! After its launch, ChatGPT accumulated 100 million users in only two months . As more and more people began to use ChatGPT, they found that he could do more and more things, such as writing papers, homework, copywriting, writing Code is out of the question.
As a result, all kinds of weird questions and requests were pushed in front of it by human beings who had a whim...
Xiaoyi found that it is possible to ask ChatGPT for the promotion outline of the book "Artificial Intelligence: Modern Methods (4th Edition)", and it can provide multiple entry points and case suggestions, which is really smart and convenient!

It is precisely because of the all-encompassing and capable nature of ChatGPT that many bigwigs in the field of artificial intelligence are amazed by it.
However, such praises all mention a common feature of ChatGPT, that is, ChatGPT has the same mind as a "child" .
In other words, although ChatGPT is very powerful, it is like a growing child. How much it can play depends on your cultivation and training.
The clearer the input prompt words are, and the more and clearer the needs are, the closer the ChatGPT answer is to the answer people want.
However, here comes the question: Humans have not tried the way of training AI like training ChatGPT before. Why can ChatGPT make such a breakthrough today?
In fact, there has already been an authoritative book that has analyzed and predicted the various advantages of ChatGPT. It is "Artificial Intelligence: Modern Methods (4th Edition)", which can be called the "Encyclopedia" in the field of artificial intelligence .

△ Click on the cover to buy, 50% discount for a limited time
Today, Xiaoyi will take everyone to take a look at the wonderful features of this great book!
— 01 —
timeless wisdom
The author of this book, Stuart Russell, is not only a professor in the Department of Computer Science at the University of California, Berkeley, but also the director of the Center for Human Compatible Artificial Intelligence, and one of the winners of the Computer and Thought Award.
In the more than 40 years of teaching, he has published more than 300 papers in the field of artificial intelligence, and he is a well-known leader in the field.

Up to now, "Artificial Intelligence: Modern Approaches" has been published in its fourth edition. The English version of this book will be published in 2021, while the third edition of the previous edition was in 2010.
And this edition is also the most important update of this book. Because in the past ten years, too many major events have happened in the field of artificial intelligence. Whether it is the duel between AlphaGo and Li Shishi, or AlphaFold has completed the prediction of protein structure, and now the advent of ChatGPT marks a major progress in the field of artificial intelligence. .
And this book just makes an important analysis of the theory and technology behind these key developments.
For example, it mentioned why ChatGPT is so good.
— 02 —
The source of ChatGPT's power
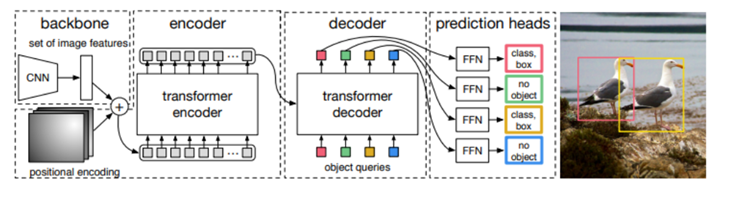
In the second chapter of this book, the author mentioned that the reason why ChatGPT is so outstanding is that it uses a structure called Transformer, which is also the core technology of ChatGPT .
The full name of Transformer is Generative Pre-trained Transformer (which is also the origin of the name of GPT). The series is a pre-trained language model released by OpenAI. The biggest feature of this model is that it can reduce or even eliminate manual supervision and labeling .
So how does this model do this?
First of all, massive data training always improves the ability of the model immediately.
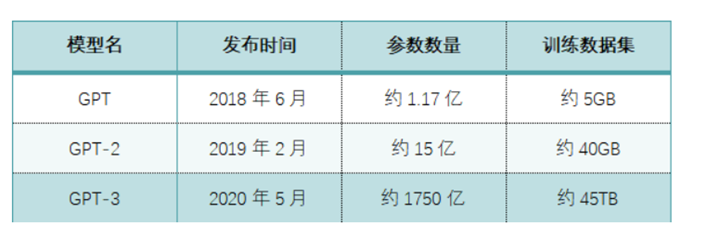
But if it only stops here, it will not be much different from the previous cyclic neural network. What really makes Transformer widen the gap is its ability to perform data calculation and model training in parallel at the same time .
Although the previous cyclic neural network can better deal with sequential data (such as language), it often pulls the hips when dealing with longer sequences of data, such as long articles and books.
Because the data must be processed in order, it is impossible to train in parallel at the same time, so the training time is very long. Over time, the model will be unstable, and the gradient will disappear .
The so-called gradient disappearance means that in the neural network, the learning rate of the current hidden layer is lower than that of the subsequent hidden layer, that is, as the number of hidden layers increases, the classification accuracy decreases instead.
In contrast, Transformer can not only perform data calculation and model training in parallel at the same time, but also overcome the shortcomings of traditional neural network technology that uses a shallow pre-trained network to capture words and cannot solve problems such as polysemy.
Simply put, it is Transformer that allows ChatGPT to learn to draw inferences from one instance! This makes it very efficient to learn .
— 03 —
Word by word, take you to understand the unique mechanism of GPT
In addition to the core architecture Transformer, the book also reveals the unique mechanism behind the operation of ChatGPT.
Similar to the BERT model, ChatGPT or GPT-3.5 automatically generates each word (word) of the answer based on the input sentence and the language/corpus probability. From the perspective of mathematics or machine learning, the language model is the modeling of the probability correlation distribution of the word sequence, that is, using the sentence that has been said (the sentence can be regarded as a vector in mathematics) as the input condition to predict the next The probability distribution of the occurrence of different sentences or even language sets at any time.
ChatGPT is trained using reinforcement learning from human feedback, a method that augments machine learning with human intervention for better results. During training, a human trainer acts as both user and AI assistant, fine-tuned by a proximal policy optimization algorithm.
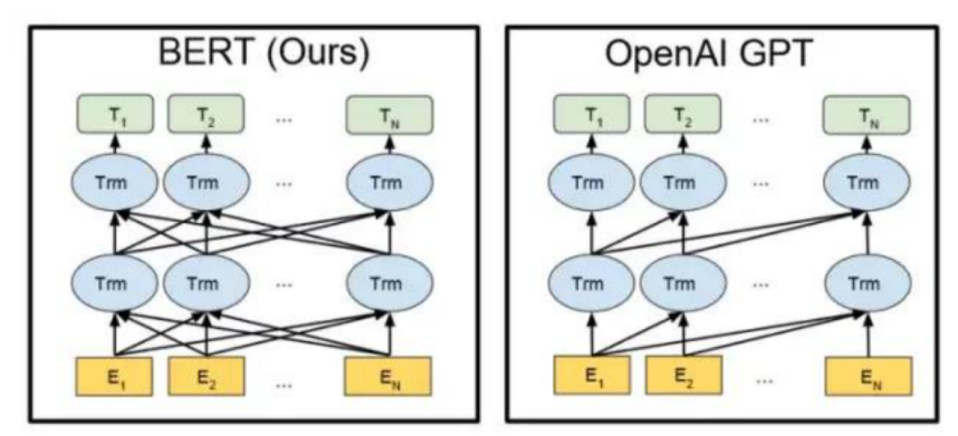
Due to ChatGPT's stronger performance and massive parameters, it contains more topic data and can handle more niche topics. ChatGPT can now further process tasks such as answering questions, writing articles, text summarization, language translation and generating computer code.
— 04 —
Want to understand the mystery of AI learning? the answer is here
The book also mentions that the reason why ChatGPT has evolved so rapidly is mainly due to several learning algorithms:
Phase 1: Training a Supervised Policy Model
It is difficult for GPT 3.5 itself to understand the different intentions contained in different types of human instructions, and it is also difficult to judge whether the generated content is a high-quality result. In order for GPT 3.5 to initially have the intention to understand instructions, humans must first use the method of "cramming education" to let the GPT-3.5 model know what the "standard answer" is .
The specific method is: first randomly select questions in the data set, and human labelers give high-quality answers, and then use these manually labeled data to fine-tune the GPT-3.5 model.
If GPT 3.5 is trained well at this stage, humans will applaud it and say: This kid is really smart, and now he can make some open-ended propositions.
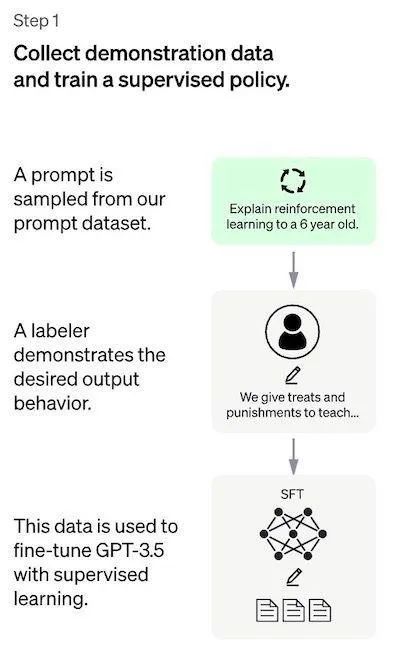
The second stage: training reward model (Reward Mode, RM)
This stage is mainly to train the reward model by manually labeling the training data (about 33K data). Randomly sample questions in the dataset, using the model generated in the first stage
It's just that at this point, the question no longer has a "standard answer", but for each question, multiple different answers are generated.
For these "open-ended questions" that do not have a standard answer, human annotators will give a ranking order based on the comprehensive consideration of these results.
Next, use this ranking result data to train the reward model. Multiple sorting results are combined in pairs to form multiple training data pairs. The RM model takes an input and gives a score that evaluates the quality of the answer. Thus, for a pair of training data, the parameters are tuned such that high-quality responses are scored higher than low-quality responses.
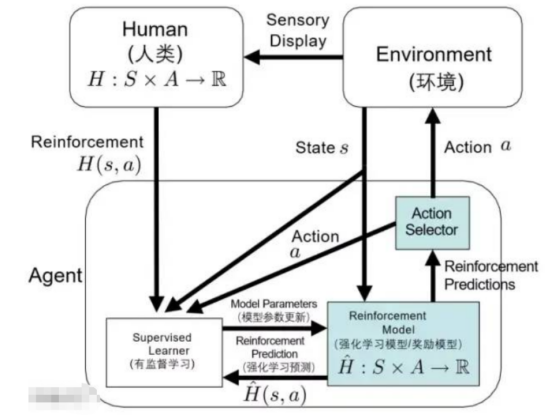
The third stage: use PPO (Proximal Policy Optimization, proximal strategy optimization) reinforcement learning to optimize the strategy.
The core idea of PPO is to transform the On-policy training process in Policy Gradient into Off-policy, that is, transform online learning into offline learning. You can understand this process as the transition from open-book exams to closed-book exams .
Not only is it not allowed to "turn the book", but the randomness of the questions has also greatly increased.
By randomly selecting questions from the reward model dataset trained in the second stage, the PPO model is used to generate answers, and the RM model trained in the previous stage is used to give quality scores. The reward scores are transmitted sequentially, thereby generating a policy gradient, and updating the PPO model parameters through reinforcement learning.
If we keep repeating the second and third stages, through iterations, a higher quality ChatGPT model will be trained.
— 05 —
An AI treasure map, waiting for you to open
In addition to the above content, Xiaoyi also introduced a lot of technical points about ChatGPT in the book, including but not limited to:
—— Convolutional Network, Recurrent Neural Network
- Machine Learning (Data Science)
- Deep Learning (Artificial Neural Networks)
——Language model (word vector, corpus)
——Reinforcement Learning from Human Feedback (RLHF)
- Self-supervised learning
——GAN generative confrontation network
Even, the author with a humanistic spirit, in Chapter 27 and Chapter 28 of this book, dedicated two chapters to discuss the philosophy, ethics and security of artificial intelligence.
It can be said that this is a masterpiece with both technology and temperature.
At this moment when AI technology is changing with each passing day, the powerful learning algorithm behind ChatGPT undoubtedly represents the most shining crystallization of artificial intelligence technology, and this book is the summary and analysis of these crystallizations in the process of artificial intelligence development .

△ Click on the cover to buy, 50% discount for a limited time
From the original Turing test to today's reinforcement learning algorithm, the book covers mathematics, psychology, neuroscience, computer science and other aspects involved in the development of artificial intelligence.
Its content is rich, like a treasure map that hides countless treasures, slowly unfolding in front of your eyes.
In this ever-changing intelligent age, if we can study the theories and knowledge in the book carefully, we will surely gain a greater advantage before the upcoming technological revolution.
Copywriter: Liao Editor: fine. Reviewers: Tong Xi, Luo Yuqi, Shan Ruiting
Reference source:
1. "Large models are becoming an important inflection point of the AI wave"
2. "ChatGPT Development History, Principles, Detailed Technical Architecture and Industrial Future"
—END—
