MySQL database knowledge collation
Detailed MySQL transaction
Four major characteristics of transactions ACID
- Atomicity: A transaction is an indivisible smallest unit. All operations of the transaction are either committed or rolled back on failure, and only a part of them cannot be executed.
- Atomicity is achieved through undo log (backtracking log) . The undo log is unique to the InnoDB storage engine. The specific implementation method is: write all data modifications (addition, deletion, and modification) to the log undo log. The undo log is a logical log, which records the SQL opposite to the transaction operation . . For example, if the transaction executes insert, undo log executes delete. It can record the log in the way of appending and writing, and will not overwrite the previous log. If a part of the operations in a transaction has been successful, but another part of the operations cannot be executed due to errors such as power outages and system crashes, the operations that have been successfully executed will be undone through the backtracking log, so as to achieve the purpose of failure of all operations. In addition, the undo log is also used to implement the multi-version concurrency control (MVCC) of the database .
- Consistency: The database always transitions from one consistent state to another consistent state. The transaction is not committed, and the modifications made in the transaction will not be saved to the database.
- Consistency is guaranteed by atomicity and persistence.
- Isolation: Modifications made by a transaction are not visible to other transactions until they are finally committed.
- Isolation is achieved through the lock mechanism and MVCC: when a transaction needs to modify a row of data in the database, it needs to add a row lock to the data first, and other transactions do not run operations on the locked data, and can only wait for the current Transaction commit or rollback will release the lock.
- Durability: Once a transaction is committed, its modifications are permanently saved to the database.
- ** Persistence is achieved through redo log. **redo log is also held by InnoDB. The specific implementation method is: **When data modification (addition, deletion, modification) occurs, the InnoDB engine will first write the record to the redo log and update the memory. At this time, the update is completed. At the same time, the InnoDB engine will flush records to disk at the right time. **redo log is a physical log, which records what changes have been made to a data page, not in the form of SQL statements. It has a fixed size and is written in a circular way to record the log. When the space is used up, the previous log will be overwritten.
Dirty reads, non-rereadable reads, and phantom reads
- Dirty read: Transaction 1 updated a piece of data but did not submit it. Transaction 2 reads the data updated by transaction 1 at this time. For some reason, transaction 1 is rolled back, so transaction 2 reads dirty data.
- Non-rereadable: Transaction 1 reads a piece of data, and before transaction 1 ends, transaction 2 also accesses the data for modification and submission. Due to the modification of transaction 2, the data read by transaction 1 is different from the data read before.
- Phantom reading: When transaction 1 reads a range of records, transaction 2 inserts new records in the range. At this time, when transaction 1 reads again, a phantom row is generated.
Four isolation levels for transactions
-
Uncommitted read (READ UNCOMMITTED)
- Modifications in a transaction are visible to other transactions even if they are not committed . That is, the latest data row is always read every time, rather than the data row that conforms to the current transaction version.
- This level causes dirty reads, non-repeatable reads, and phantom reads.
-
Commit to read (READ COMMITTED)
- Any modification made by a transaction is invisible to other transactions until it is committed. The implementation method is: add a shared lock to the read operation, but release it after the statement is executed.
- This level solves dirty reads, but cannot solve phantom reads and non-rereadables.
-
Repeatable read (REPEATABLE READ)
- This level ensures that the results of reading the same record multiple times in the same transaction are consistent, and it is the default transaction isolation level of InnoDB. The implementation method is: add a shared lock to the read operation, the shared lock is not released before the transaction is committed, and is released after the transaction is executed.
- This level solves dirty reads and non-repeatable reads, but does not solve phantom reads.
- InnoDB uses gap locks to solve the phantom reading problem of current reading, and MVCC solves the phantom reading under snapshot reading.
-
Serializable (SERIALIZABLE)
- **The highest isolation level, forcing transactions to be executed serially. **Lock each row of data. Although it is safe to do so, it will cause a lot of timeouts and lock contention. It is generally used when data consistency needs to be strictly guaranteed and no concurrency is accepted.
- This level prevents dirty reads, non-rereadable reads, and phantom reads.
dirty read non-rereadable Phantom reading uncommitted read meeting meeting meeting submit read Won't meeting meeting rereadability Won't Won't meeting Serializable Won't Won't Won't
Detailed explanation of MySQL engine
[External link picture transfer failed, the source site may have an anti-leeching mechanism, it is recommended to save the picture and upload it directly (img-Q6y6yGxQ-1679497838441) (C:\Users\12576\Desktop\Notes\Common mysql engine.jpg)]
MyISAM
- The default storage engine before MySQL5.1 does not support transactions, row-level locks and foreign keys , and cannot be safely recovered after a crash.
- MyISAM locks entire tables , not rows. When reading, add a shared lock to all tables that need to be read, and add an exclusive lock to the table when writing. While the table has data query, new records can also be inserted into the table (concurrently).
- MyISAM tables can be checked and repaired manually or automatically. Table repair operations are very slow and may result in some data loss.
- Supports full-text indexing , even for long fields of BLOB and TEXT, indexes can be created based on the first 500 characters.
- If the DELAY_KEY_WRITE option is specified, after each modification is executed, the modified index data will not be written to disk immediately, but will be written to the key buffer in memory. Only when the buffer is cleaned up or the table is closed will the corresponding index data be written to disk.
InnoDB
- The default transactional engine after MySQL5.5 is used to handle a large number of short-term transactions. Provides transaction safety with commit, rollback, and crash recovery capabilities. However, compared with the MyISAM engine, the write processing efficiency will be lower, and it will take up more disk space to retain data and indexes.
- Supports self-increasing sequences, foreign key constraints, and row locks.
- MVCC is used to support high concurrency , and four standard isolation levels are realized. The default isolation level is Repeatable Read. The gap lock strategy is used to prevent phantom reading. The gap lock enables InnoDB to not only lock the rows involved in the query, but also lock the gaps in the index to prevent the insertion of phantom rows.
- Based on the clustered index , the query on the primary key has high performance. But its secondary index (non-primary key index) must contain the primary key column, so if its primary key column is large, all other indexes will be large. Generally, the primary key is required to be auto-incremented, which ensures that the B+ tree index is expanded from the right every time it is inserted, avoiding frequent merging and splitting of the B+ tree.
- Solve the deadlock problem: roll back the transaction that holds the least row-level exclusive locks.
- Full-text index, not supported before 5.7, but supported after 5.7.
- With two locks, locking can be performed at any time during transaction execution. The lock will only be released when a COMMIT or ROLLBACK is executed, and all locks will be released at the same time. Automatically lock when needed according to the isolation level.
- Four characteristics
- insert buffer
- Used for insert performance. Among them, the change buffer is an enhancement of the insert buffer. The insert buffer is only valid for insert, and the change buffer is valid for insert, delete and update.
- It is only valid for the insertion of non-clustered and non-unique indexes: for each insertion, it is not directly written to the index page, but first judges whether the inserted non-clustered index page is in the buffer, if it is inserted directly, otherwise it is first placed In the insert buffer, the merge operation is performed according to a certain frequency, and then written back to the disk. This usually combines multiple inserts into one operation, in order to reduce the performance loss caused by random IO.
- Its size is 1/4 of the buffer pool by default, and the maximum can be set to 1/2.
- secondary write cache
- In order to solve the problem of page breaks, that is, when the database crashes abnormally, only part of the database pages are written to the disk, resulting in inconsistencies in the pages.
- **The secondary write cache is located in the storage area of the system table space, and is used to cache the data that the InnoDB data page reads from the insert buffer but is not written to the data file. **So even if it crashes during the process of writing to the disk, InnoDB can find a backup of the data page in the secondary write for recovery.
- The action of writing data pages to the double write cache requires less IO operations than the consumption of writing to data files.
- The size defaults to 2M.
- adaptive hash index
- The InnoDB storage engine will monitor the lookup of the secondary index on the table, and if it is observed that the establishment of a hash index can bring about a speed increase, a hash index will be established.
- The adaptive hash index is constructed through the B+ tree of the buffer pool, so the establishment speed is very fast, and there is no need to establish a hash index for the entire table.
- It will occupy the buffer pool of InnoDB, and it is only suitable for searching equivalent queries, and cannot be used for range queries.
- Read ahead: Improve IO performance, used to asynchronously read disk pages into the buffer pool, predicting that these pages will be read immediately. There are two implementations, linear read-ahead and random read-ahead.
- Linear read-ahead: It is predicted that pages adjacent to the data accessed in the buffer pool will also be accessed soon, which can be controlled by adjusting the number of consecutively accessed pages.
- Random read-ahead: Predict which pages may be accessed soon through the pages stored in the buffer pool, regardless of the reading order of these pages.
- insert buffer
- Using B+ tree
-
The non-leaf nodes of the B+ tree do not store data, but only key values.
- The size of the page (that is, the node in the tree) in the database is fixed, and InnoDB defaults to 16KB. If you don't store data, you can store more key values, which makes the tree shorter and fatter. In this way, the number of IOs we need to find data for disk will be reduced again, so that the efficiency of data query will be faster. If a node stores 1000 key values, a 3-layer B+ tree can store 1000x1000x1000=1 billion data! Generally, the root node is placed in memory.
-
All the data of the B+ tree index are stored in the leaf nodes, and the data is arranged in order.
- Doing so makes range, sort, group and deduplicate searches very easy. The data of the B-tree is scattered in each node, and in-order traversal is necessary to perform a range search. Each page of the B+ tree in InnoDB is connected through a two-way linked list, and the data in the leaf nodes is connected through a one-way linked list.
-
Summarize the advantages of B+ tree:
- The number of disk IOs involved in a single request is small (non-leaf nodes do not contain table data, and the height of the tree is small)
- The query efficiency is stable (any keyword query must be from the root node to the leaf node, and the query path length is the same)
- High traversal efficiency (you can start traversing from a certain leaf node that meets the conditions, while B-tree cannot avoid querying non-leaf nodes)
-
Memory
- It is suitable for fast access to data, and these data will not be modified, and it does not matter if they are lost after restarting. This engine is faster than MyISAM, because all data is stored in memory and no disk IO is required. Its table structure will be retained after restart, but the data will be lost.
- Hash index is supported; the table is a table-level lock, so concurrent write performance is low; BLOB and TEXT are not supported, and the length of each row is fixed, so even if VARCHAR is specified, it will be converted to CHAR during actual storage.
Merge
- A virtual table for merging multiple MyISAM tables, now obsolete
Archive
- Only INSERT and SELECT operations are supported, and indexes were not supported before MySQL5.1.
- Cache all columns and use zlib to compress inserted rows, less disk IO than MySIAM. But each SELECT needs to perform a full table scan. Therefore, the Archive table is suitable for log and data collection applications.
- Supports row-level locks and dedicated buffers, so high-concurrency insertions can be achieved. Before a SELECT starts and returns all the rows in the table, the Archive engine will block other SELECT executions to achieve consistent reads. And it realizes that the batch insert is not visible to the read operation until it is completed.
Comparing MyISAM and InnoDB
| primary key | storage | affairs | data cache | CRUD operations | index | Save the number of rows | foreign key | |
|---|---|---|---|---|---|---|---|---|
| MyISAM | Can have no primary key | Can be compressed and takes less storage space. Supports three different storage formats: default static table, dynamic table and compressed table | not support | not support | MyISAM emphasizes performance, so SELECT is fast (no row-level locks). The entire table needs to be locked when adding or deleting, which is less efficient | nonclustered index. The leaf node of the index stores the row data address, which needs to be addressed again to get the data | A variable is used to save the number of rows in the entire table, and the execution of count only needs to read the variable, which is very fast (you can’t add where, you can only read all the rows) | not support |
| InnoDB | There must be a primary key. If no primary key is specified, a non-empty unique index will be selected as the primary key. If there is still no primary key, InnoDB will customize a primary key, which is a 6-byte long integer | Requires more memory and storage, builds its dedicated buffer pool in main memory for caching data and indexes | Support, for each SQL statement, it will be packaged into a transaction by default and automatically submitted, which will affect the speed, so it is best to combine multiple SQL statements into a transaction | support | If you perform a large number of INSERT or UPDATE, InnoDB is more efficient. | Clustered index, the primary key index stores row data, so querying through the primary key is very efficient | If it is not saved, a full table scan is required when executing count (the number of rows in the same time table is different for different transactions due to the characteristics of InnoDB transactions) | support |
Use the show engines \G command, the default engine inside to view the engines supported by the database.
Multi-version concurrency control MVCC
- MVCC is a variant of row-level locks, but it avoids locking operations in many cases, so the overhead is lower, and most of them implement non-blocking read operations, and write operations only lock necessary rows.
- Principle: MVCC is implemented by saving a snapshot of the data at a certain point in time. No matter how long it takes to execute, the data seen by each transaction is consistent. Depending on the start time of the transaction, each transaction may see different data for the same table at the same time.
- Implementation method: It is realized by saving two hidden columns behind each row record, one saves the creation version number of the row, and the other saves the expired version number (deletion version number) of the row. Every time a new transaction is started, the version number of the system will be incremented, and the system version number at the beginning of the transaction will be used as the version number of the transaction, which is used to compare with the version number of each row of records queried.
- At the level of repeatable reading, the specific operation of MVCC:
- SELECT: InnoDB queries each row of records according to the following two conditions
- Only look for data rows whose row creation version is earlier than the current transaction version (the system version number of the row is less than or equal to the system version number of the current transaction), so as to ensure that the rows read by the transaction either exist before the transaction starts, or are Inserted or modified by the transaction itself.
- The row's delete version number is either undefined or greater than the current transaction version number. This ensures that rows read by a transaction are not deleted before the transaction begins.
- INSERT: InnoDB saves the current system version number as the creation version number for each newly inserted row.
- DELETE: InnoDB saves the current system version number as the delete version number for each row deleted.
- UPDATE: InnoDB saves the current system version number as the creation version number and deletion version number for each row inserted.
- SELECT: InnoDB queries each row of records according to the following two conditions
- Saving these two extra system version numbers allows most operations to be performed without locking. This makes the read data operation simple, the performance is better, and it is guaranteed that only rows that meet the standard will be read. But each row of records requires additional storage space, adding additional overhead and maintenance work.
- MVCC only works at two levels of committed read and repeatable read.
database paradigm
-
First Normal Form: Each column cannot be split again. The first normal form is the most basic requirement of a relational model, and a database that does not meet the first normal form is not a relational database.
-
Second normal form: On the basis of the first normal form, each non-primary key column is completely dependent on the primary key, not on a part of the primary key.
-
Third normal form: On the basis of second normal form, non-primary key columns can only depend on the primary key and must not depend on other non-primary keys.
-
BCNF paradigm: On the basis of satisfying the three paradigms, it should also satisfy:
- All non-primary attributes are fully functional dependencies on each code
- All primary keys are also fully functionally dependent on every key that does not contain it
- No property is fully functionally dependent on any set of properties that are not coded
Code: A certain attribute (or attribute group) of a tuple can be uniquely determined in the table. If there is more than one such code, then everyone is called a candidate code. We pick one from the candidate code to be the boss, and it is called the master code (i.e. primary key).
Detailed explanation of MySQL index
-
An index is a data structure used by the storage engine to quickly find records, which can be understood as containing reference pointers to all records in the data table.
-
Advantages: greatly speed up the retrieval speed of the database, and use the optimization hider to improve the performance of the system during the query process.
-
shortcoming:
- Creating indexes and maintaining indexes takes time.
- Indexes occupy additional physical space (every time one is created, a B+ tree must be built).
- When adding, deleting, and modifying data in the table, the index also needs to be dynamically maintained, which will reduce the efficiency of adding, deleting, and modifying.
-
scenes to be used:
- Query based on the primary key index.
- order by sorts the query results (the index itself is sorted).
- The join statement matches the relationship design field to create an index to improve efficiency.
-
Why is the index fast? Because when the DB executes a Sql statement, the default method is to scan the entire table according to the search conditions, and when the matching conditions are encountered, it is added to the search result set. If we add an index to a certain field, we will first go to the index list to locate the number of rows with a specific value at a time when querying, which greatly reduces the number of traversal matching rows, so the query speed can be significantly increased.
-
Index type: primary key index, unique index, common index, full-text index. (joint index, multi-index)
-
InnoDB's index data structure defaults to a B+ tree index and a hash index.
-
The basic principle of indexing is to turn unordered data into ordered queries:
- Sort the contents of all the columns that create the index
- Generating an inverted list for a sorted structure
- Add the address chain of the data on the content of the posting list
- When querying, first get the content of the posting table, and then get the data address chain, so as to get the specific data.
-
Principles of index design:
- Columns suitable for indexing should be the columns that appear in the where clause, or the columns specified in the link clause.
- If you use a short index, if you index a long string column, you should specify the prefix length, which can save a lot of index space.
- Don't overdo it with indexing.
-
Creation principles:
-
Leftmost prefix matching principle: MySQL will always match to the right until it encounters a range query (> < between like), so if it is the following statement, build an index according to abcd, and d is not used:
where a=1 and b=2 and c>3 and d=4 -
Fields that are frequently used as query conditions should be indexed, and columns that are seldom queried and have many repeated values are not suitable for indexing. Frequent updates are not suitable for indexing.
-
Columns that cannot effectively distinguish data are not suitable for indexing.
-
Extend the index as much as possible instead of creating a new one.
-
Data columns with foreign keys must be indexed.
-
Columns of text (text field), image, and bit data types are not suitable for indexing.
-
-
Clustered and nonclustered indexes
-
Clustered index: Construct a B+ tree according to the primary key of each table, store data and index together, and the leaf nodes of the index structure store data. The leaf nodes of the clustered index are also called data pages, and each table can only have one clustered index.
- InnoDB clusters the index through the primary key. If the primary key is not defined, it will choose a non-empty unique index instead. If there is still no such index, then InnoDB will implicitly define a primary key as the clustered index (the field length is 6 bytes. long integer).
- advantage:
- Data access is faster because the index and data are stored in the same B+ number.
- Sort lookups and range lookups on primary keys are very fast.
- shortcoming:
- The insertion speed depends heavily on the ordering of the primary key, and inserting in the order of the primary key is the fastest way. For InnoDB tables, we generally define an auto-increment ID as the primary key.
- The cost of updating the primary key is high, because it will cause the updated row to move and change the structure of the B+ tree. For InnoDB tables, we generally define that the primary key cannot be updated.
-
Non-clustered index: An index built on the clustered index. The data is stored separately from the index. The leaf nodes of the index structure store the primary key value. First find the primary key value through the non-clustered index, and then find the corresponding data page based on the primary key value. Therefore, it requires a secondary search, which is slower than the clustered index.
- The existence of nonclustered indexes does not affect the organization of data in clustered indexes, so a table can have multiple nonclustered indexes.
- MyISAM uses nonclustered indexes by default.

-
-
Interview question: Can like go to the index? How to go?
- The SQL statement in the case of indexing should be like h% or like h. And like %h is not indexed.
-
Interview question: Why not use other data structures as the storage engine of InnoDB
- Problems with sorted arrays:
- Sorted arrays can be searched with a time complexity of OlogN, but insertion and deletion operations are too expensive to be ON.
- Problems with Hash tables:
- The time complexity of the hash algorithm is O1 when there is no conflict (to mention here, the random query of the array is O1, but the fastest query by value is the binary search OlogN), that is to say, its retrieval efficiency is higher than that of the B+ tree index. From root node to leaf node, multiple IO access is much higher.
- But its disadvantages are also obvious:
- The size relationship of the hash value after processing by the hash algorithm is not exactly the same as before processing, which also makes it unable to satisfy some range queries , such as >, <, etc., it can only satisfy =, IN, <= > . (<=> is similar to =, the difference is the result, a<=>NULL is 0, NULL<=>NULL is 1, and for =, both operations are NULL)
- Hash indexes cannot be queried by using partial index keys . When calculating the hash value, the hash indexes are calculated by combining the index keys together instead of separately.
- Table scanning cannot be avoided at any time . Different index keys may have the same hash value, so even if a certain hash value is satisfied, it cannot be queried directly, and the actual data in the table must continue to be accessed.
- If a large number of equivalent hash values are encountered, the performance is not necessarily higher than that of B+Tree .
- Problem with binary search tree (red-black tree):
- No matter what kind of binary search tree, its height will increase as the number of nodes increases. The index of the database is too large to be directly loaded into the memory (the root node may be installed in the memory). When searching, you need to read the disk IO every time you go down one level. And the efficiency of IO is very low.
- The database is stored in the form of pages. The InnoDB storage engine defaults to a page size of 16K. A page can be regarded as a node. A node in a binary tree can only store one data, resulting in a huge waste of space.
- Problems with B-trees:
- Whether the B-tree is a leaf node or a non-leaf node, it will store data, which leads to a reduction in the number of pointers that can be stored in the non-leaf node. In the case of fewer pointers, saving a large amount of data can only increase the height of the tree, resulting in more IO operations and lower query efficiency.
- In order to implement range search, B-tree can only perform in-order traversal.
- Problems with sorted arrays:
Covering index: For SELECT, JOIN, WHERE operations, all the required data can be obtained only from the index, without the need to go back to the table to read from the data table (the query column is covered by the index used).
- Back to the table: When using the non-clustered index to search for data, you need to go to the clustered index to look up the complete user record again according to the primary key value. This process is called back to the table.
- Because when the index is built, the leaf nodes of the B+ tree that are queried already have all the indexed data and primary key values, so naturally there is no need to return the table
Composite Index: An index on two or more columns is known as a composite index.
- The leftmost prefix of the joint index: MySQL uses the fields in the index from left to right. A query can only use part of the index, but only the leftmost part. For example, the joint index is index(a,b,c), It can support three combinations of a ab abc to search, but does not support bc to search. The implementation is to use a B+ tree, each node contains multiple keywords, and they are sorted according to the keywords when sorting. ps: For multiple single-column indexes, only the first index will take effect under multi-condition query.
- The joint index is also a B+ tree, and the sorting method is to sort according to the columns of the index. For example, according to (bcd) to build a joint index, bcd becomes a binary tree . It conforms to the principle of leftmost matching, that is, first sorts according to the first index b. If the first index is equal, sort by the second index , and so on. If sorted according to the leftmost index, the remaining indexes are unordered .
Locks in MySQL
-
Locks in isolation level:
- Uncommitted read: read data does not need to add a shared lock, so that it will not conflict with the exclusive lock on the modified data.
- Commit to read: Read operations add a shared lock, but release it after the statement is executed.
- Rereadable: shared locks are added to read operations, the shared locks are not released before the transaction is committed, and are released after the transaction is executed.
- Serializability: Lock the entire range of keys until the transaction completes.
-
According to the granularity, there are three kinds of locks:
- Row-level lock: Only lock the row currently being operated. Row-level lock can greatly reduce database operation conflicts. The granularity is the smallest, but the overhead of locking is also the largest. Row-level locks are divided into shared locks and exclusive locks.
- Table-level lock: lock the entire table currently being operated, which is simple to implement and low in overhead. The largest particle size.
- Page-level locks: The granularity is between row-level locks and table-level locks. There are many table-level conflicts, but the speed is fast; there are few row-level conflicts, but the speed is slow, and the overhead is between row-level locks and table-level locks. Deadlocks will occur and the concurrency is average.
-
InooDB completes row locks based on indexes. There are three types of lock algorithms:
-
Record Lock: row lock, a lock on a single row record.
-
Gap Lock: Gap lock, locking a range, excluding the record itself.
-
Next-key Lock: Locks a range up to and including the record itself.
-
InnoDB uses Next-key Lock for row queries, and it solves the problem of phantom reading. When the query index contains the only attribute, downgrade the Next-key Lock to Record Lock.
-
The design purpose of Gap lock is to prevent multiple transactions from inserting records into the same range to prevent phantom reading.
事务A 事务B 事务C begin begin 查询id、姓名 两个数据:1,hty1 20,hty20 更新hty = hty11 where id = 12 插入条数据,id=15,waiting 插入条数据,id=33 commit; 事务A commit之后,这条语句才插入成功 commit; commit;We open three transactions. The id=12 updated by transaction A is between (1,20]. Even if no data is modified, InnoDB will add a Gap lock in this interval, while other intervals will not be affected. So the insertion id of transaction B =15, you need to wait for transaction A to commit before submitting normally. The insertion id of transaction C is not in this range, so insert normally.
If we do not use any index, even if no data is matched, then a gap lock will be added to the entire table (no index, no interval), and other transactions cannot insert any data unless the transaction is committed
-
-
Row locks prevent other transactions from being modified or deleted, Gap locks prevent other transactions from being added, and the Next-key combined with row locks and Gap locks solves the problem of phantom reading of data written at the RR level.
-
-
MySQL deadlock problem
- Deadlock: Two or more transactions occupy each other on the same resource, and at the same time request each other's resources to cause mutual waiting. If there is no external force, they cannot proceed.
- solution:
- Make sure to access the tables in the same order.
- Keep transactions short.
- The same transaction tries to lock all the resources needed at one time.
- Lowering the isolation level and reducing RR to RC can avoid many deadlocks caused by Gap locks.
- InnoDB for deadlocks: Roll back transactions that hold the fewest row-level locks.
- Four necessary conditions for a deadlock:
- Mutual exclusion : A resource can only be used by one process.
- Request and hold : When a process is blocked due to requesting resources, it does not let go of the resources it has already obtained.
- Inalienable : The resources acquired by the process cannot be forcibly deprived before they are used up.
- Circular waiting : A head-to-tail circular waiting resource relationship is formed among several processes.
-
Two-stage lock protocol: divide the transaction into a locking phase and an unlocking phase.
- Locking phase: Apply for and obtain a shared lock before reading any data (other transactions can continue to add shared locks, but cannot add exclusive locks), apply for and obtain exclusive locks before performing write operations (other transactions No locks can be added). If the locking is unsuccessful, the transaction enters the waiting state until the locking is successful.
- Unlocking phase: After a transaction releases a lock, it enters the unlocking phase, which can only be unlocked but not locked.
MySQL page splitting and page merging
The internals of the page
Pages can be empty or filled, rows will be sorted by primary key order, if you use AUTO_INCREMENT you will have sequential ID 1234 etc.
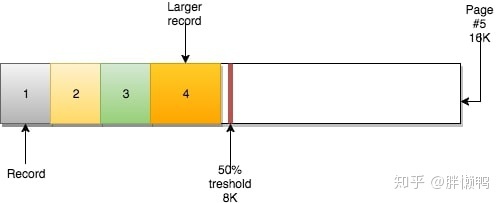
The page also has an attribute MERGE_THRESHOLD. The default value of this parameter is 50% of the page size, which plays an important role in page consolidation in InnoDB. When inserting data, the data size can fit into the page, then they fill up the page in order; if the page is full or cannot fit, the next row of records will be inserted into the next page.
According to the characteristics of the B+ tree, it can traverse from top to bottom, and can also traverse each leaf node horizontally, because each leaf node has a pointer to the page containing the next sequential record. Under this mechanism, fast sequential scanning (range scanning) can be achieved.
page merge
When a record is deleted, the record is not actually physically deleted, the record is marked for deletion and its space becomes available for use by other record claims.
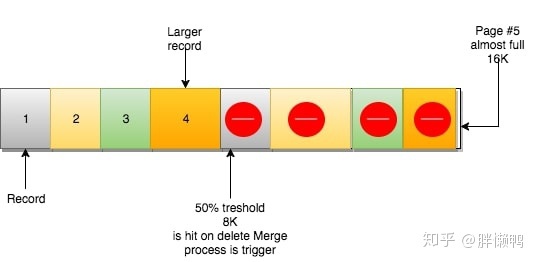
When the deleted records on the page reach MERGE_THRESHOLD (50% of the default page volume), InnoDB will start looking for the closest page (both before and after) to see if the two pages can be merged to optimize space usage. Merging frees up space on other pages to accommodate new data. Of course updates are also possible.
page split
A certain page is full or is about to be full. At this time, a data size larger than the remaining space comes:
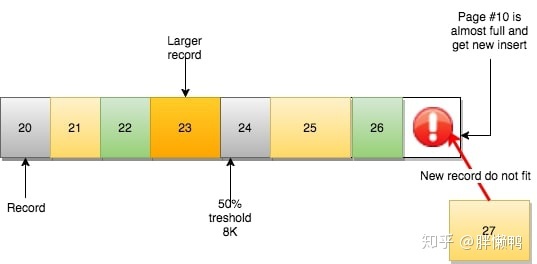
According to the logic of the next page, the data record should be processed by the next page of this page, but the next page is not enough, and the data cannot be inserted out of order:
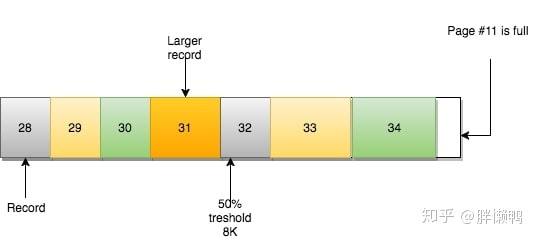
At this time, InnoDB's approach is:
- create new page
- Determine where the current page and the next page can be split from (record level)
- move record line
- Redefine the relationship between pages
After page splitting, the horizontal orientation of the B+ tree is still satisfied. However, in terms of physical storage, the pages are out of order and may fall into different areas.
Page splits can occur on inserts or updates and cause page misalignment (falling into different extents). In this case, if you want to restore the order, you need to split the new page and delete the page because it is lower than the merge threshold. At this time, InnoDB uses page merge to merge the data back.
How a SQL statement is executed
- First connect to the database, this time received by the connector. The role of the connector is to establish a connection with the client, obtain permissions, maintain and manage the connection.
- After MySQL gets a query request, it first goes to the query cache to see if the statement has been executed before, and if it has been executed, it returns the result directly from the cache.
- If not, the analyzer will identify what the string in this statement is, what it represents, and judge whether it satisfies the SQL grammar.
- After passing the analysis by the analyzer, execute the optimizer for optimization. The optimizer decides which index to use when there are multiple indexes in the table, or decides the connection order of each table when a statement is associated with multiple tables.
- Then the executor executes the statement. When executing the statement, it first judges whether the statement has access permission to the table. If not, it directly returns a no permission error.
- Connector-"Check Cache-"Analyzer-"Optimizer-"Executor
Some questions about MySQL statements
MySQL keyword execution order
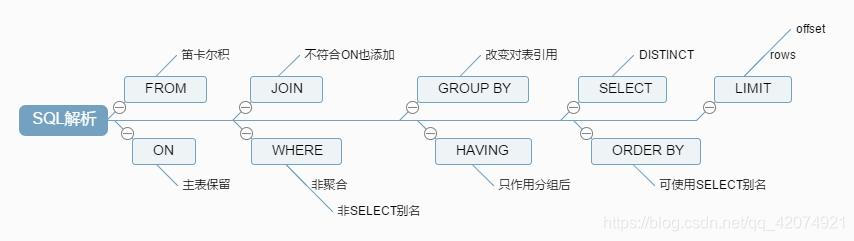
EXISTS vs IN
- EXISTS uses the loop to query the external table one by one. Each query will check the statement in EXISTS. When the conditional statement in EXISTS can return the record row, the condition will be true, and the record that the current loop has reached will be returned. Otherwise, this record of the current loop is discarded.
- IN is the superposition of multiple or conditions. First find out all the records of the sub-query condition, assuming that the result set is r, and there are m records in total, and then decompose the result set of the sub-query condition into m, and then perform m times Inquire.
- The subquery in IN requires that the returned result must have only one field, while EXIST does not have this limitation.
- IN will be changed to EXISTS to execute when querying.
UNION vs UNION ALL
These two operations are the union operation of two result sets, the difference
- The result of UNION does not include duplicate rows, which is equivalent to distinct, and is sorted by default rules; while UNION ALL includes duplicate rows, and all results are displayed without sorting.
- UNION will sort the obtained results, but UNION ALL will not.
Common Aggregate Functions
- AVG: Returns the average value in the specified column, ignoring null values.
- COUNT: Returns the number of rows in the specified column.
- MAX, MIN return the maximum and minimum values in the specified column, respectively.
- SUM: Returns the sum of the specified data, can only be used for numeric columns, and ignores null values.
WHERE vs HAVING
- When using HAVING, we require that the fields in the condition must be filtered out, while WHERE does not require it.
- The WHERE condition cannot be followed by an aggregate function, because the execution order of WHERE is greater than that of the aggregate function. If you need to use an aggregate function as a filter condition, use HAVING.
- HAVING usually filters the data after grouping, so it is generally used after using GROUP BY or aggregation functions, while WHERE filters the data before grouping.
GROUP BY
-
Group summary, which requires the result fields of SELECT to be summable, otherwise an error will occur. Generally combined with aggregate functions to group the result set according to one or more columns
-
Principle: Among all the columns after SELECT, the columns that do not use aggregate functions must be behind GROUP. For example, the following statement is wrong, because the name, gender and age are not aggregated and not necessarily single:
SELECT id, name, sex, sum(score) FROM students GROUP BY id /*该语句错误!*/
Interview question: What is the difference between char and varchar?
char is a fixed-length type, and varchar is a variable-length type.
- In a data column of char (M) type, each value occupies M bytes fixedly. If the length of a column is less than M, MySQL will fill it with space bytes on the right. Fill out the space bytes to remove.
- In a varchar(M) type data column, each value only occupies just enough bytes plus a byte used to record its length (M+1 bytes)
In MySQL, the rules used to determine whether to convert the data column type:
- In a data table, if the length of each data column is fixed, then the length of each data row will also be fixed.
- As long as one data column has a variable length, each data row has a variable length.
- If the length of a data row in a data table is variable, in order to save storage space, MySQL will convert the fixed-length data column in this data table into a corresponding variable-length type (length less than 4 characters does not will be converted)
mysql connection
cross connect
CROSS JOIN: Cartesian product, directly join the records of the two tables together.
outer join
LEFT JOIN: Returns all rows from the left table even if there are no matches in the right table. Returns null if the right table has no records.
RIGHT JOIN: Returns all rows from the right table even if there is no match in the left table. Returns null if the left table has no records.
FULL OUTER JOIN: Find the complete set, some DBMSs are FULL JOIN, but mysql does not support it, only left union right. If there is data, return data, if not, return null.
inner join
INNER JOIN: returns rows if there is at least one match in the table. Equivalent to direct JOIN. That is, the intersection of the two tables does not return null, and they are strictly connected.
natural connection
NATURAL JOIN: Natural join is a special kind of equivalent join. It requires that the columns connected in the two relational tables must be the same attribute column (same name), without adding any join conditions, and eliminate duplicate attributes in the result. List.
For example: There are two tables A and B
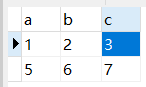

If execute: select * from table1 natural join table2
then returns:
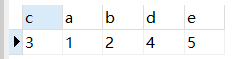
MySQL optimization
-
Enable the slow query log, and record the SQL statements that run slowly in the log.
-
Modify the configuration file and add a few lines in my.ini: mainly the definition time of slow queries and the log records of slow queries.
-
Enable slow query through MySQL database
-
-
To analyze MySQL slow query logs, you can use the explain keyword.
- Execute EXPLAIN SELECT * FROM res_user ORDER BY xxx LIMIT 0,1000; Display the result:
- table shows which table the data of this row is about
- type This is the important column that shows what type of connection was used. The join types from best to worst are const, eq_reg, ref, range, indexhe, and ALL
- rows shows the number of rows that need to be scanned
- The index used by key
- Execute EXPLAIN SELECT * FROM res_user ORDER BY xxx LIMIT 0,1000; Display the result:

optimization point
-
Don't build too many indexes.
- Space cost: Every time an index is created, a B+ tree must be built for it, and each node of each B+ tree is a data page. A page occupies 16KB of storage space by default, and a large B+ tree will take up a lot of space.
- Time cost: Each time the data in the table is added, deleted, or modified, each B+ tree index must be modified. The nodes at each level of the B+ tree are doubly linked lists arranged in ascending order of the values of the index columns. The values in the leaves and inner nodes are single-linked lists from small to large. Addition, deletion and modification will damage the record ordering of these nodes, so the storage engine needs some extra time to perform some record shifting.
-
For the problem of joint index, such as index(name, birthday, phone), the joint index is sorted in the order of the index in the B+ tree. Therefore, in the index index, sort according to the name column first, and then sort by birthday if the name is the same, and then sort by phone if the birthday is the same.
-
Match the leftmost index : the data page records of the B+ tree are first sorted by the value of the name column, and if the values of the name column are the same, they are sorted by birthday. If the values of the name column are different, the birthday is out of order. For example:
SELECT * FROM person WHERE birthday = '1990-09-27';For queries without name, the index will be invalid.
-
Matching range value: When using a joint index for range search, if a range search is performed on multiple columns at the same time, the B+ tree index can only be used if the range search is performed on the leftmost column of the index, for example :
SELECT * FROM person WHERE name > 'ddd' AND name < 'hty' AND birthday > '2000-11-11';For the joint index, name can be used to quickly locate and pass the condition name > 'ddd' AND name < 'hty', but it cannot continue to filter by birthday > '2000-11-11'. Because the range search records by name may not be sorted by birthday.
-
Match exactly one column and range match another column
SELECT * FROM person WHERE name = 'hty' AND birthday > '2000-11-11' AND birthday < '2011-11-11' AND phone > '11111111111';The name is an exact search, so the birthday is sorted when the name is the same, and the B+ tree index can be used for the range search of the birthday, but for the phone, the birthday is sorted but the phone is out of order. The index cannot be used.
-
sorting problem
-
For a joint index, the order of the columns after the ORDER BY clause must also be given in the order of the index columns, if:
ORDER BY phone, birthday, name DESCYou can't use the B+ tree index.
-
For the mixed use of ASC and DESC, the joint index cannot be used for sorting. We require that the sorting order of each sorting column be the same, or all columns are ASC or DESC.
-
Index columns that are not used for sorting in the WHERE clause cannot use indexes, for example:
SELECT * FROM person WHERE country = 'China' ORDER BY name LIMIT 10;This statement needs to find out the entire row of records after returning to the table and filter them before sorting, and the index cannot be used.
-
Indexes cannot be used when the sorting column contains columns that are not the same index, for example
SELECT * FROM person ORDER BY name, country LIMIT 10; -
Indexes cannot be used with functions in ORDER BY.
-
-
-
Matching column prefix (leftmost matching principle) : If a field is of VARCHAR type, the arrangement of the name field in the index will follow the following rules:
-
First compare the first character of the string, if the first character is smaller, the string is smaller.
-
If the first characters of two strings are the same, the second is compared, the second smaller string is smaller, and so on.
-
This is what we often say about the like indexing problem:
SELECT * FROM person WHERE name LIKE 'ht%'; /*走索引*/ SELECT * FROM person WHERE name LIKE '%ty'; /*不走索引*/
-
-
Covering index: If all the columns we can query are found in the index, then there is no need to go back to the table to find the corresponding columns . For example:
SELECT name, birthday, phone FROM person WHERE name > 'ddd' AND name < 'hty'We only query these three, all of which are in the joint index, so after querying the results, there is no need to search for the remaining columns in the clustered index.
-
Let the index column appear alone in the comparison expression : Suppose there is an integer column col in the table, we create an index for this column, and perform the following query:
WHERE col * 2 < 4 WHERE col < 4 / 2Although the semantics of these two sentences are the same, the efficiency is different:
- The col of the first article does not appear in the form of a separate column, but in the form of an expression such as col * 2. The storage engine will traverse all the records in turn to calculate whether the expression is less than 4. In this case, the index created by the col column will not be used.
- If the col column of the second column appears alone, it can be indexed.
-
Performance consumption caused by page splitting
- We assume that a page can only store 5 pieces of data, and the middle three are specific data, sorted by 135. We insert a 4, then we have to allocate a new page. 5>4 The index is in order, we need to move 5 to the next page, and insert a new piece of data with id=4 into the original page. We call this process page splitting, page splitting and record shifting means performance loss. We have to try to avoid this unnecessary performance loss. Therefore, the primary key of the inserted record is generally incremented in turn, that is, the primary key AUTO_INCREMENT, and the storage engine generates the primary key by itself.
-
Reduce row lock time
-
Two-stage lock protocol: In InnoDB, row locks are added when needed, but they are not released immediately when they are not needed, but are not released until the end of the transaction. Therefore, if you need to lock multiple rows in a transaction, put the locks that are most likely to cause lock conflicts and affect concurrency later.
-
Suppose there is a business:
A在电影院B购买电影票: 1.从顾客A账户余额中扣除电影票价 2.给影院B的账户余额增加这张电影票价 3.记录一条交易日志The logic to complete the transaction normally is 123, we need two updates and one insert. In order to ensure the atomicity of the transaction, we put these three records in one transaction. If customer A and customer C buy tickets at the same time, then these two transactions will conflict in statement 2, because they want to update the balance of the same theater account and modify the same row of data. According to the two-stage lock protocol, no matter how the statements are arranged, the row locks required by all operations are released when the transaction is committed, so if the statements are arranged in the order of 312, this minimizes the waiting for locks between transactions , increasing the concurrency.
-
-
Count function optimization: compare count(*), count(primary key id), count(field) and count(1)
count() is an aggregation function. For the returned result set, it is judged line by line. If the parameter of the count function is not NULL, the cumulative value will be added by 1, otherwise it will not be added. Finally returns the accumulated value.
- For count (primary key id), InnoDB will traverse the entire table, take out the id of each row, and return it to the server layer. After the server layer gets the id, it judges that it cannot be empty and adds up row by row.
- For count(1), InnoDB traverses the entire table, but does not take a value. The server layer puts a number 1 for each row returned, and accumulates row by row if it is judged that it cannot be empty. Obviously, count(1) is faster.
- For count (field)
- If the field is defined as not null, read this field from the record line by line, judge that it is impossible to be null, and directly add up line by line.
- If the field definition allows null, then when it is executed, it is judged that it may be null, then the value is taken out and judged, and it is accumulated only if it is not null.
- For count(*), MySQL has specifically optimized it, which is also a strategy of not taking a value, and the bottom layer will automatically optimize which field to execute. The specific efficiency is similar to count(1).
- Therefore: count(*) ≈ count(1) > count(primary key id) > count(field not null) > count(field allows null)
-
ORDER BY performance optimization
- MySQL sorting will use memory for sorting (sort_buffer_size), which is the size of memory (sort_buffer) opened by MySQL for sorting. If the amount of data to be sorted is smaller than sort_buffer_size, the sorting will be done in memory. If the amount of sorting is too large to be stored in memory, temporary disk files must be used to assist sorting. If there are many fields returned by the query, too many fields should be placed in the sort_buffer, so that the number of rows that can be stored in the memory at the same time is very small, and the score will be divided into many temporary files, resulting in poor sorting performance.
- So when we execute ORDER BY
- The number of data columns returned should be as small as possible, and unnecessary data columns should not be returned.
- The index is naturally ordered. If the column to be sorted can be set as an index if necessary, then it can be returned directly without sorting in sort_buffer.
- If necessary, you can use a covering index, so that when returning data, you can directly query the data without even returning to the table through the primary key.
-
Implicit type conversion, implicit character encoding conversion
SELECT * FROM student WHERE stu_id = 11;We specify stu_id as the primary key index, VARCHAR type, this statement does not use the index but the entire table. Because the input is an INT integer, it means that SQL with implicit type conversion cannot be indexed. The same applies to implicit character encoding conversions.
-
JOIN optimization: There are two tables t1 and t2, the table results are exactly the same, field a is an index field
-
Case 1: Double index lookup
SELECT * FROM t1 JOIN t2 ON (t1.a = t2.a);1. Read a row of data R from t1
2. Take field a from data R and look it up in table t2
3. Take out the rows that meet the conditions in table t2 and form a row with R as part of the result set
4. Repeat the steps 1 to 3 until the end of t1 the loop endsThis SQL uses an index, so after taking out the data of the t1 table, according to the a field of the t1 table, it is actually an equivalent search for an index of the t2 table, so the number of rows compared between t1 and t2 is the same. Since the driving table t1 matches the driven table t2, the number of matches depends on how much data t1 has. Therefore, when using index association, it is best to use a table with a small amount of data as the driving table.
-
Case 2: Single index lookup
SELECT * FROM t1 JOIN t2 ON (t1.a = t2.b);If there is no index available for the driven table, perform the following operations at this time:
1. Read the data of table t1 into the join_buffer of the thread memory. Since we wrote SELECT * in this statement, put the entire t1 into the memory
2. Scan t2 , Take out each row in t2 and compare it with the data in join_buffer, and those that meet the join condition will be part of the result set. If the default 256k of join_buffer cannot fit, it will be segmented. If segmented, the driven table will have to be scanned multiple times, affecting performance. -
To sum up, for which table is used as the driving table, we should filter according to their respective conditions. After filtering, calculate the total data volume of each field participating in the join, and the table with a small data volume is used as the driving table.
-
Summarize the situation where the index fails
- Joint index failure conditions:
- If the leftmost index does not appear in the first position of the query result, or does not appear, the index is invalid.
- For a range search, only the leftmost column can use the index. If the leftmost column has an equality query, then the second index can go, and so on.
- The order of the columns after the clause of ORDER BY must also be given in the order of the index columns, otherwise it is invalid.
- ASC and DESC are mixed, and joint indexes cannot be used for sorting.
- In the WHERE clause, the index column used for non-sorting cannot use the index.
- Indexes cannot be used for columns that do not contain the same index as the sort column.
- Functions are used in ORDER BY and indexes cannot be used.
- If the query condition uses or, each column in the or condition must be indexed, otherwise it is invalid.
- LIKE '%ty' cannot walk the index.
- WHERE col * 2 < 4 cannot be indexed, because the index column does not appear alone in the expression. There is an aggregate function in the WHERE clause and the index cannot be used
- If it contains implicit type and implicit character encoding conversion, it cannot be indexed.
SQL injection
Definition: SQL injection refers to modifying and splicing the original URL, form fields or data input parameters of the web page into SQL statements, passing them to the web server, and then passing them to the database server to execute database commands. If the web program does not filter or verify the data or cookies entered by the user (there is an injection point), it will be directly transmitted to the database, resulting in the execution of the concatenated SQL, obtaining information about the database and escalating privileges, and an SQL injection attack occurs .
Prevention:
- Hierarchical management: Strictly limit user permissions. For ordinary users, it is forbidden to give database write permissions.
- Parameter value passing: Do not directly write variables into SQL statements, but pass related variables by setting corresponding parameters. Data input cannot be directly embedded in query statements.
- Filtering: Check the user's input, and process it if a special character is encountered to ensure the security of data input.
Master-slave replication, log and database recovery in MySQL
The undo log and redo log mentioned above are not directly written to the disk, but are first written to the log buffer, and then wait for the appropriate actual synchronization to the OS buffer, and then the OS system decides when to flush to the disk. Both undo log and redo log are from the log buffer to the OS buffer and then to the disk. If there is still a possibility of log loss due to power failure or hardware failure in the middle. For this purpose, MySQL provides three persistence methods:
- One parameter: innodb_flush_log_at_trx_commit, this parameter is to control the time point when InnoDB writes the data in the log buffer to the OS buffer and flushes it to the disk, the values are 0, 1, 2 respectively, and the default is 1
- 0: Write OS buffer every second and call fsync() to flush to disk.
- 1: Each submission is written to the OS buffer and called fsync() to flush to disk.
- 2: Each submission is written to the OSbuffer, and then the OS buffer calls fsync() every second to flush to the disk.
From the perspective of ensuring data consistency, 1 this method is safe, but the efficiency is not high. Each submission is directly written to the OS buffer and written to the disk, which will lead to too many IOs per unit time and low efficiency. Compared with method 0, method 2 saves one copy process (from log buffer to OS buffer) after writing to OS buffer and then writing to disk, which is more efficient than method 0.
These two logs can restore the database from an abnormal state to a normal state:
- When the database system crashes and restarts, the database is in an inconsistent state at this time, and a crash recovery process must be performed first: read the redo log, and rewrite the data that has been successfully submitted but has not yet been written to the disk to the disk to ensure persistence . After reading the undo log, the transactions that have not been successfully committed are rolled back to ensure atomicity. After the crash recovery ends, the database returns to a consistent state.
bin log
The bin log is a binary log that records all DDL and DML statements (processing data query statements, etc.), records them in the form of events, and also includes the execution time of the statements. Among them, MySQL's binary log is transaction-safe, and the main purpose of binlog is replication and recovery.
- MySQL master-slave replication: MySQL Replication opens the bin log on the Master side, and the Master passes its binary log to the Slaves to achieve the purpose of master-slave data consistency.
- Data recovery: recover data by using the MySQL bin log tool.
Master-slave replication: realized through binlog
step:
- The update events (update, insert, delete) of the main database db are written to the binlog
- Initiate a connection from the library and connect to the main library
- At this time, the main library creates a binlog dump thread (main library thread), and sends the contents of the binlog to the slave library
- After starting from the library, create an I/O thread, read the binlog content from the main library and write it to the relay log (local relay log)
- A SQL thread will also be created to read content from the relay log (relay log), execute the read update event from the Exec_Master_Log_Pos position, and write the update content to the db of the slave library
The entire MySQL master-slave replication is asynchronous .
When to record bin log
Statement: Based on the Binlog at the SQL statement level, each SQL statement that modifies data will be saved in the Binlog.
Row: Based on the row level, record the changes of each row of data, that is, record the changes of each row of data in Binlog, which is very detailed, but does not record the original SQL; when copying, it will not be due to stored procedures Or triggers cause data inconsistency between the master and slave databases, but the amount of logs recorded is much larger than the Statement format.
Mixed: Mixed Statement and Row modes. By default, Statement mode is used to record. In some cases (determined by system conditions), it will switch to Row mode and also corresponds to the three technologies of MysQL replication.
When to save bin log to disk
Timing of bin log being stored on disk: For InnoDB, an engine that supports transactions, the binlog must be committed only after the transaction is committed. When the binlog is flushed to disk is related to the parameter sync_binlog.
- If it is set to 0, it means that MySQL does not control the refresh of the binlog, and the file system controls the refresh of its cache;
- If it is set to a value other than 0, it means that every sync_binlog transaction, MySQL calls the refresh operation of the file system to refresh the binlog to the disk;
- Setting it to 1 is the safest, and the update of at most one transaction will be lost when the system fails, but it will affect performance.
If sync_binlog = 0 or sync_binlog is greater than 1, when a clerk fails or the operating system crashes, some transactions that have been submitted but whose binlog has not been synchronized to the disk may be lost, and the recovery program will not be able to restore these transactions. Prior to MySQL 5.7.7, the default value of sync_binlog was 0, and MySQL 5.7.7 and later use the default value of 1, which is a safe choice. Generally set to 0 or 100 to improve performance.