gcn原文(Multi-layer Graph Convolutional Network (GCN) with first-order filters)
GCN has been around for several years (it was born in 2016), but it has been particularly popular in the past two years. I am dull, and I have never been able to understand what this GCN is. At first, I read a 30-40-page review written by Tsinghua University. After reading a few pages, I stopped reading it; The mathematics part in the middle is kneeling; and later, when I read the explanations of the great gods on Zhihu, I was directly confused by the overwhelming formulas-what Fourier transform, what Laplace operator, etc. The more I read it, I felt: "Wow, these big guys are so powerful, why am I so good!".
Just like this over and over again, trying to give up once, and finally gradually understanding, slowly jumping out of those formulas, seeing the overall situation, and gradually understanding the principle of GCN. Today, I will record my understanding of GCN "phased".
The concept of GCN was first proposed in ICLR2017 (written in 2016):

1. What does GCN do
Before diving into the vast ocean of GCN, let's figure out what this thing does and what it's useful for.
Deep learning has always been dominated by several classic models, such as CNN, RNN, etc. They have achieved excellent results in both CV and NLP fields. How did this GCN come out? It is because we have found many problems that CNN and RNN cannot solve or the effect is not good - the data of the graph structure.
Recall that when we do image recognition, the object is a picture, which is a two-dimensional structure, so people invented a magical model like CNN to extract the features of the picture. The core of CNN lies in its kernel, which is a small window that translates on the picture and extracts features by convolution. The key here is the translation invariance of the picture structure: no matter where a small window moves to the picture, its internal structure is exactly the same, so CNN can realize parameter sharing. This is the essence of CNN.
Recall the RNN series again. Its object is sequence information such as natural language, which is a one-dimensional structure. RNN is specially designed for the structure of these sequences. Through various gate operations, the information before and after the sequence affects each other. , so as to capture the characteristics of the sequence well.
The pictures or language mentioned above belong to the data of Euclidean space, so there is the concept of dimension. The characteristic of data in Euclidean space is that the structure is very regular. But in real life, there are actually many, many irregular data structures, typically graph structures, or topological structures, such as social networks, chemical molecular structures, knowledge graphs, etc.; even languages are actually complex internally. The tree structure is also a graph structure; and like a picture, when doing target recognition, we actually only pay attention to some key points on the two-dimensional picture, and these points are also composed of a graph structure.
The structure of the graph is generally very irregular, and can be considered as a kind of data with infinite dimensions, so it has no translation invariance. The surrounding structure of each node may be unique, and the data of this structure makes the traditional CNN and RNN instantly invalid. Therefore, many scholars have been studying how to deal with such data since the last century. There are many methods emerging here, such as GNN, DeepWalk, node2vec, etc. GCN is just one of them. Here we only talk about GCN, and the others will be discussed later when we have time.
GCN, graph convolutional neural network, is actually the same as CNN, it is a feature extractor, but its object is graph data. GCN has cleverly designed a method of extracting features from graph data, so that we can use these features to perform node classification, graph classification, and link prediction on graph data. By the way, the embedded representation of the graph (graph embedding) can be obtained, which shows that it has a wide range of uses. So now people's brains are wide open, allowing GCN to shine in various fields.
2. What does GCN look like, is it scary?
GCN's formula still looks a bit scary, and the formula in the paper scared me even more. But it was later discovered that 90% of the content is not necessary to be ignored at all, just to clarify things mathematically, but it does not affect our understanding at all, especially for people like me who "pursue intuition and do not seek deep understanding".
Let's get to the point, let's take a look at what the core part of GCN looks like:
Assuming that we have a batch of graph data at hand, there are N nodes (nodes), and each node has its own characteristics. We set the characteristics of these nodes to form an N×D-dimensional matrix X, and then the relationship between each node is also An N×N-dimensional matrix A, also known as an adjacency matrix, will be formed. X and A are the inputs to our model.
GCN is also a neural network layer, and the propagation method between its layers is:
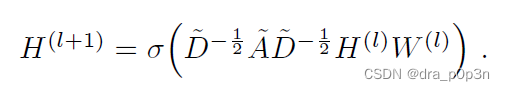
In this formula:
A wave=A+I, I is the identity matrix
D wave is the degree matrix of A wave, the formula is
H is the feature of each layer, for the input layer, H is X
σ is a nonlinear activation function ,
we will not use it first Consider why you want to design a formula the way you do. We now only need to know:
This part can be calculated in advance, because D wave is calculated from A, and A is one of our inputs.
So for those who don't need to understand the mathematical principles and just want to apply GCN to solve practical problems, you only need to know: Oh, this GCN has designed a powerful formula, which can be used to extract the graph well. feature. This is enough. After all, not everything needs to know the internal principle, which is determined according to the demand.
For intuitive understanding, we use a picture in the paper:
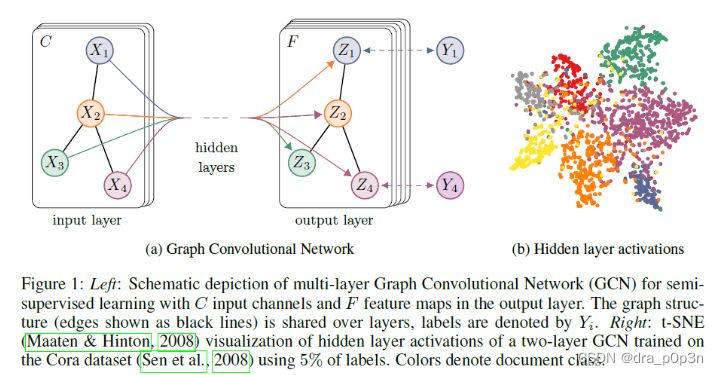
The GCN in the above figure enters a graph, and the feature of each node of GCN changes from X to Z through several layers. However, no matter how many layers there are in the middle, the connection relationship between nodes, that is, A, is shared.
Suppose we construct a two-layer GCN, and the activation functions use ReLU and Softmax respectively, then the overall forward propagation formula is:
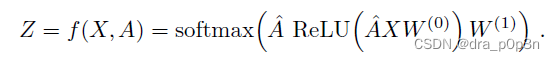
Finally, we compute the cross entropy loss function for all labeled nodes:
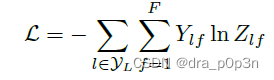
You can train a node classification model. Since it can be trained even if only a few nodes have labels, the authors call their method semi-supervised classification.
Of course, you can also use this method to do graph classification and link prediction, just change the loss function.
3. Why is GCN like this
I read a lot of people's interpretations back and forth, but after reading it around, it is the author Kipf's own blog that makes me understand why the GCN formula is like this: http://tkipf.github.io/graph-convolutional -networks/ I recommend everyone to read it.
The author gives a simple-to-complex process to explain:
The input of each layer of our GCN is the adjacency matrix A and the feature H of the node, then we directly make an inner product, multiply a parameter matrix W, and then activate it, which is equivalent to a simple neural network layer, yes Isn't it also possible?
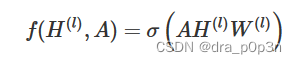
Experiments have proved that even such a simple neural network layer is already very powerful. This simple model should be understood by everyone. This is the normal neural network operation.
But this simple model has several limitations:
If only A is used, since the diagonal of A is all 0, when multiplying with the feature matrix H, only the weighted sum of the features of all neighbors of a node will be calculated, and the features of the node itself will be ignored. . Therefore, we can make a small change and add an identity matrix I to A, so that the diagonal elements become 1.
A is a matrix that has not been normalized, so multiplying it with the feature matrix will change the original distribution of the feature, resulting in some unpredictable problems. So we do a normalization on A. First let each row of A add up to 1, which we can multiply by an inverse of D, which is the degree matrix. We can further multiply the disassembly of D by A to obtain a symmetric and normalized matrix: .
By improving the above two limitations, we get the final layer feature propagation formula:
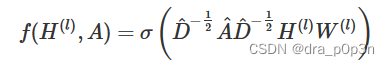
in
The formula in the formula is very similar to the symmetric normalized Laplacian matrix, and the core of spectral graph convolution is to use the symmetric normalized Laplacian matrix, which is also the origin of GCN's convolution name. The original paper gives a complete step-by-step derivation from spectral convolution to GCN. I can't stand it. If you are interested, you can read it by yourself.
4. How awesome is GCN
After reading the above formula and training method, I don't think GCN is so special. It is nothing more than a cleverly designed formula. Maybe I don't need such a complicated formula. Adding more training data or making the model deeper can also achieve comparable effect.
But it wasn't until I read the appendix of the paper that I suddenly realized: GCN is so awesome!
why?
Because even with unsupervised training, using the randomly initialized parameter W, the features extracted by GCN are excellent! This is completely different from CNN without training, which will not get any effective features at all without training.
Let's look at the original text of the paper:

Then the author did an experiment, using a club member's relationship network, using a randomly initialized GCN for feature extraction, getting the embedding of each node, and then visualized:
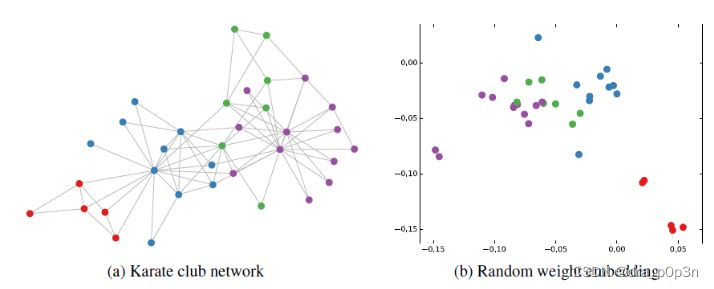
It can be found that the nodes of the same category in the original data have been automatically clustered in space through the embedding extracted by GCN. And this clustering result is comparable to the effect of node embedding obtained through complex training such as DeepWalk and node2vec. It's an exaggeration to say that GCN is already at the finish line before the game starts. Seeing this, I couldn't help but slapped my thigh and said, "NB!" Unsupervised training is already so effective, so given a small amount of labeled information, the effect of GCN will be even better. The author then provides only one labeled sample for each type of node, and then trains. The obtained visualization effect is as follows:

This picture is not clear enough to zoom in. The video link is here . This is the part that impressed me the most in the whole paper.
other:
For many networks, we may not have the characteristics of nodes. Can we use GCN at this time? The answer is yes. For example, in the paper, the author used the method of replacing the feature matrix X with the identity matrix I for the club network.
I don't have any labeling of node categories, or any other labeling information, can I use GCN? Of course, as mentioned earlier, GCN without training can also be used to extract graph embedding, and the effect is not bad.
How many layers of the GCN network is better? The authors of the paper have done comparative research on the depth of GCN networks. In their experiments, they found that the number of GCN layers should not be too many, and the effect of 2-3 layers is very good.
Reprinted from this blog , corrected several errors