Article directory
Practical basic theory of GCN (for coding)
1. Representation of graphs

A : adjacency matrix of graph structure A ~ : adjacency matrix with self-connection A ~ = A + ID ~ : degree matrix of adjacency matrix with self-connection D ~ ii = ∑ j A ~ ij H : characteristics of graph nodes l : The number of neural network layers \begin{aligned} & A: adjacency matrix of graph structure\\& \widetilde{A}: adjacency matrix with self-connection\\& \widetilde{A} = A + I \\& \widetilde{ D}: degree matrix of adjacency matrix with self-connection\\& \widetilde{D}_{ii} = \sum_{j} \widetilde{A}_{ij} \\& H: characteristics of graph nodes\\ &l:Number of neural network layers\end{aligned}A : adjacency matrix of graph structureA
: adjacency matrix with self-connectionA
=A+ID
: degree matrix of adjacency matrices with self-connectionsD
ii=j∑A
ijH : characteristics of graph nodesl:Neural Network Layers
2. The principle of GCN
H ( l + 1 ) = δ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ( l ) W ( l ) ) H^{(l+1)} = \delta(\widetilde{D}^{-1/2}\widetilde{A}\widetilde{D}^{-1/2}H^{(l)}W^{(l)}) H(l+1)=d (D −1/2A D − 1/2 H(l)W(l))
- The input of GCN is the adjacency matrix A and the node feature H, directly do the inner product, then multiply a parameter matrix W, and then activate it, isn't it equivalent to a neural network layer? Why have a self-connected adjacency matrix?
Hint: It is impossible to distinguish between "self-node" and "no-connection node". If only A is used, since the diagonal of A is all 0, when multiplying with the feature matrix H, only the weighted sum of the features of all neighbors of a node will be calculated, and the features of the node itself will be ignored. .
- Why do you need a degree matrix with a self-connected adjacency matrix?
Tip: A is a matrix that has not been normalized, so multiplying it with the feature matrix H will change the original distribution of the feature, so do a normalization process on A. The importance of nodes with a large degree of balance. (symmetric normalized Laplacian matrix)
Norm A ij = A ijdidj NormA_{ij} = \frac{A_{ij}}{\sqrt{d_{i}}\sqrt{d_{j}}}NormAij=didjAij
3. The underlying implementation of GCN (pytorch)
Pytorch-Geometric (PyG):https://github.com/pyg-team/pytorch_geometric
Official documentation https://pytorch-geometric.readthedocs.io/en/latest/notes/introduction.html
PyG provides the following main functions:
- Data Handling of Graphs (graph data processing)
- Common Benchmark Datasets (common benchmark datasets)
- Mini-batches
- Data Transforms (data conversion)
- Learning Methods on Graphs (graph learning algorithm)
- Exercises _
3.1 Data Handling of Graphs (graph data processing)
Graphs are used to model pairwise relationships (edges) between objects (nodes). A single graph in PyG is described by an instance of torch_geometric.data.Data, which by default contains the following properties:
data.x: node feature matrix H, shape:[num_nodes, num_node_features]data.edge_index: graph adjacency matrix A, shape:[2, num_edges], data type:torch.longFor example: [[0,1,1,2],[1,0,2,1]]: indicates that there is an edge between node 0 and node 1, and an edge between node 1 and node 2,
namely: [[all starting points node], [all endpoint nodes]]. This is different from general thinking, they are transposed of each other. Note that when using it, it must be converted to this form before usedata.edge_attr: edge feature matrix, shape:[num_edges, num_edge_features]data.y: training target (can be any shape), eg , label on node scale, shape:[num_nodes, *]or label on whole graph scale[1, *]data.pos: node coordinate matrix, shape:[num_nodes, num_dimensions]
import torch
from torch_geometric.data import Data
# 注意:edge_index是定义所有边的源节点和目标节点的张量,不是索引元组的列表。
# --------------------第一种定义方法-----------------------------
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
>>> Data(edge_index=[2, 4], x=[3, 1])
# --------------------第二种定义方法-----------------------------
edge_index = torch.tensor([[0, 1],
[1, 0],
[1, 2],
[2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index.t().contiguous()) # 注意这里edge_index进行了转置
>>> Data(edge_index=[2, 4], x=[3, 1])
3.2 Common Benchmark Datasets
Contains some basic datasets used for testing
3.3 Mini-batches
Neural networks are usually trained in a batch fashion. PyG parallelizes mini-batches by creating a sparse block-diagonal adjacency matrix (defined by 'edge_index') and concatenating the feature and target matrices in the node dimension.
This combination allows different numbers of nodes and edges in a batch example (i.e. A1~An their dimensions can be different):
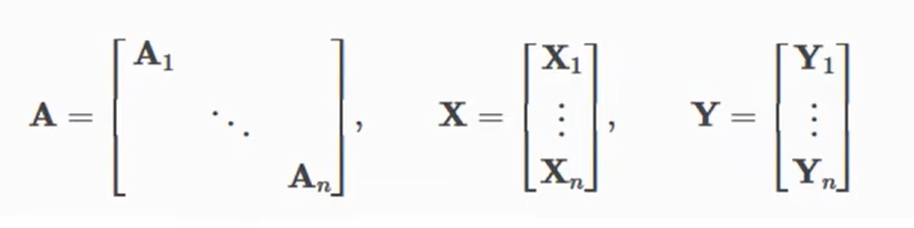
4. Implement the GCN layer
This formula can be broken down into the following steps:
- Add self-loops in the adjacency matrix.
- Linearly transform the node feature matrix.
- Calculate the normalization coefficient.
- Normalize node features
- Summing adjacent node features (“add” aggregation).
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='add') # "Add" aggregation (Step 5).
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: 在邻接矩阵中添加自循环。~A
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: 线性变换节点特征矩阵。H*W
x = self.lin(x)
# Step 3: 计算归一化系数。
row, col = edge_index # row:第一行数据,col:第二行数据
deg = degree(col, x.size(0), dtype=x.dtype) # deg:度矩阵D; 参数为col算入度,参数为row算出度
deg_inv_sqrt = deg.pow(-0.5) # D^(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
# The result is saved in the tensor norm of shape [num_edges, ]
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] # D^(-0.5) * ~A * D^(-0.5)
# Step 4-5: 规范化节点特征,对相邻节点特征求和(“add”聚合)。
return self.propagate(edge_index, x=x, norm=norm) # D^(-0.5) * ~A * D^(-0.5) * H * W
def message(self, x_j, norm): # 扩展相乘,保证A和H能够相乘
# x_j has shape [E, out_channels]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j
5. Simple example of GCN
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
class GNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16) # 参数1: 节点特征数,参数2: 随机
self.conv2 = GCNConv(16, dataset.num_classes) # 参数1: 与上一层一致,参数2: label类别数
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index) # x为特征矩阵,edge_index为邻接矩阵
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='./data/Cora', name='Cora')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GNN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {
acc:.4f}')
Mathematical theoretical basis of GCN (for understanding)
1. GCN foundation
GNN公式: H ( l + 1 ) = f ( A , H ( l ) ) H^{(l+1)} = f(A, H(l)) H(l+1)=f(A,H ( l )) , whereAAA is graph adjacency matrix,HHH is the characteristic matrix of all nodes on the graph
GCN公式: H ( l + 1 ) = δ ( D ^ − 1 / 2 A ^ D ^ − 1 / 2 H ( l ) θ ) H^{(l+1)} = \delta(\hat D^{-1/2}\hat A\hat D^{-1/2}H^{(l)}\theta) H(l+1)=d (D^−1/2A^D^− 1/2 H( l ) θ), whereDDD is the degree matrix,θ \thetaθ is the parameter to be learned
The difference between GNN and GCN:
GNNs include:
- Direct processing of graphs from the airspace
- First convert the graph from the spatial domain to the spectral domain, and then convert to the spatial domain after the spectral domain operation is completed. Namely GCN . As for why it is necessary to convert from the spatial domain to the spectral domain, it is because the structure of the nodes on the graph is not fixed in the spatial domain (for example, the adjacent nodes of the nodes on each graph are inconsistent), so it is difficult to find a general convolution. Check the image to extract features, but convert it to the spectral domain, which is easy to handle. This is why the idea of Fourier transform is used.
Let's explore the source of the following GCN formula.
2. Spectral Domain Graph Theory
In short, the spectral domain graph theory is a theory that studies some properties of the correlation matrix with the adjacency matrix A.
First, review a few related concepts in linear algebra:
(1) Eigenvalues and eigenvectors
For a matrix A, if A x ⃗ = λ x ⃗ A\vec{x} = \lambda\vec{x}Ax=lx, and ∣ x ⃗ ∣ ≠ 0 |\vec{x}|\neq0∣x∣=0 , thenx ⃗ \vec{x}xIs the eigenvector of A, λ \lambdaλ is a corresponding eigenvalue
(2) Real symmetric matrix: The elements of the matrix are all real numbers, and the matrix is a symmetric matrix.
Properties of real symmetric matrices : The eigenvectors corresponding to different eigenvalues of real symmetric matrix A are orthogonal . Written as a mathematical expression, A can be expressed as A = U Λ UTA=U\Lambda U^TA=UΛUT ,withUUT= I UU^T=IU U UT=I ,Λ \LambdaΛ is a matrix whose diagonal elements are all eigenvalues and other positions are 0.
(3) Positive semi-definite matrix:
Properties of positive semi-definite matrices: The matrix is a real symmetric matrix; all eigenvalues of the matrix are greater than or equal to 0
(4)二次型:x ⃗ TA x ⃗ \vec{x}^TA\vec{x}xT Ax
(5)Rayleigh商: x ⃗ T A x ⃗ / x ⃗ T x ⃗ \vec{x}^TA\vec{x} / \vec{x}^T\vec{x} xT Ax/xTx. Properties: when x ⃗ \vec{x}xWhen is the eigenvector of A, the Rayleigh quotient is the corresponding eigenvalue.
With the above theories, let's take a look at some matrices related to the adjacency matrix A:
Laplace matrix: L = D − AL = D - AL=D−A ,where D is the degree matrix where D is the degree matrixwhere D is the degree matrix
symmetric normalized Laplacian matrix: L sym = D − 1 / 2 LD − 1 / 2 L_{sym} = D^{-1/2}LD^{-1/2}Lsym=D− 1/2 LD−1/2
Why study the above two matrices? It is because these two matrices have excellent properties (these properties can be applied to the Fourier transform). The properties are as follows:
- Both matrices are real symmetric matrices (and therefore positive semi-definite matrices), so there are n eigenvalues and corresponding eigenvectors greater than or equal to zero.
- L s y m L_{sym} LsymThe value range of the eigenvalue is [0,2]
The first property does not need to be proved, because the relevant properties of the matrix have been given above. Let's prove the second property:
- First define a matrix G, where (i,i), (i,j), (j,i), (j,j) are 1, and other positions are 0, the form is as follows: 0 0 0 . . . 0 0
0 0 0 0 . . . 0 0 0 0 0 1 . . . 1 0 0 . . . 0 0 1 . . . 1 0 0 0 0 0 . . . 0 0 0 0 0 0 . . . 0 0 0 \begin {matrix} 0&0&0&...&0&0&0\\ 0&0&0&...&0&0&0\\ 0&0&1&...&1&0&0\\ ...\\ 0&0&1&...&1&0&0\\ 0&0&0&0&...&0&0&0\\ 0&0&0&0&...&0&0&0\\ \end{matrix}000...000000000001100..................001100000000000000- Then calculate x ⃗ TG x ⃗ \vec{x}^TG\vec{x}xTGx, where x ⃗ \vec{x}xFor any vector, the result is x ⃗ TG x ⃗ = ( xi + xj ) 2 \vec{x}^TG\vec{x} = (x_i+x_j)^2xTGx=(xi+xj)2 (I won’t expand it here, you can calculate it on the draft paper yourself)
- Define a L pos = D + AL^{pos} = D+ALpos=D+A,易得 L p o s = D + A = ∑ i , j ∈ E G L^{pos} = D+A = \sum_{i,j\in E}G Lpos=D+A=i,j∈E∑G (the following summation formula is the addition of the G matrix in all cases)
- Then you can get x ⃗ TL posx ⃗ = ∑ i , j ∈ E ( xi + xj ) 2 \vec{x}^TL^{pos}\vec{x} = \sum_{i,j\in E}( x_i+x_j)^2xTLposx=∑i,j∈E(xi+xj)2
- 定义 L s y m p o s = D − 1 / 2 L p o s D − 1 / 2 = D − 1 / 2 ( D + A ) D − 1 / 2 = I + D − 1 / 2 A D − 1 / 2 L_{sym}^{pos} = D^{-1/2}L^{pos}D^{-1/2}=D^{-1/2}(D+A)D^{-1/2}=I+D^{-1/2}AD^{-1/2} Lsympos=D− 1/2 Lp os D−1/2=D−1/2(D+A)D−1/2=I+D− 1/2 AD−1/2。
- 又因为 x ⃗ T L s y m p o s x ⃗ = x ⃗ T ( I + D − 1 / 2 A D − 1 / 2 ) x ⃗ > = 0 \vec{x}^TL_{sym}^{pos}\vec{x} =\vec{x}^T(I+D^{-1/2}AD^{-1/2})\vec{x} >=0 xTLsymposx=xT(I+D− 1/2 AD−1/2)x>=0 , so after expanding the transformation, you can get
x ⃗ TL symx ⃗ / x ⃗ T x ⃗ < = 2 \vec{x}^TL_{sym}\vec{x}/\vec{x}^T\vec{x} <=2xTLsymx/xTx<=2- It is found that the left side of the equal sign is the Rayleigh quotient. According to the properties of the Rayleigh quotient mentioned above, when x ⃗ \vec{x}xThe eigenvector of the matrix is, and the value of the corresponding Rayleigh quotient is the eigenvalue, so the above expression is L sym L_{sym}LsymAll eigenvalues of are less than or equal to 2.
- And because L sym L_{sym}Lsymis a positive semidefinite matrix, so the eigenvalues are greater than or equal to 0. Therefore L sym L_{sym}LsymThe range of eigenvalues is [0,2].
This property is very important and will be used below.
Let's discuss the knowledge of Fourier transform used in graph convolution.
3. Fourier transform
First of all what is the Fourier transform? Let's understand it from the following picture: Suppose we have a function f ( t ) f(t)
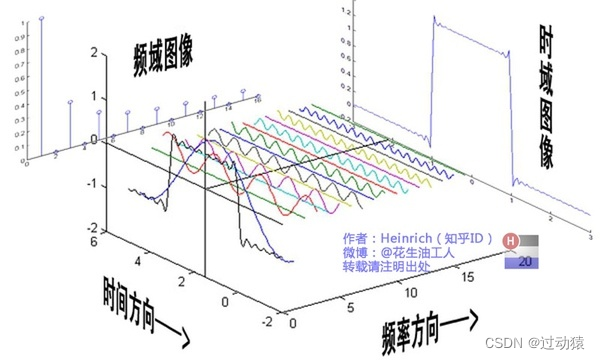
that describes sound waves in timef ( t ) , then the function of Fourier transformis to decompose this function into multiple sinusoidal functions that also take time as an independent variable. is the mathematical principle of Fourier transform, which will not be discussed here), and then put these functions on another coordinate system with the amplitude as the ordinate and the frequency as the abscissa. To put it simply, the original function is the left view of the above image (ie, the instant domain image), and the transformed function is the right view of the above image (ie, the frequency domain image).
Why do such transformations? Because in some tasks, if we deal with the problem in the time domain, it will be very troublesome, but it will be very simple to deal with the problem in the frequency domain. For example, a man and a woman talk at the same time (as we all know, the frequency of boys’ voices is low, and the frequency of girls’ voices is high), we have obtained this audio, but we want to remove the voice of boys in this audio, if only based on the time domain image Processing will be It is very troublesome, but if we can map this wave to the frequency domain, then the sound waves of boys will be concentrated in the low frequency band, and the sound waves of girls will be concentrated in the high frequency band, so we can directly delete the sound waves of the low frequency band. This is very simple.
Reflected on the figure, it is difficult for us to solve the problem in the airspace, so we need to change this problem to another coordinate system to solve (that is, the spectral domain), and then convert the result back to the airspace. This is the idea of Fourier transform used in GCN.
Having said so many conceptual things, let's talk about mathematical theory:
First define c ⃗ \vec{c}cis a certain eigenvector of all nodes in the graph, and then explore L c ⃗ L\vec{c}Lcmeaning of:
- 首先L = D − AL = D - AL=D−A,因此L c ⃗ = ( D − A ) c ⃗ = D c ⃗ − A c ⃗ L\vec{c} = (D - A)\vec{c} = D\vec{c} - A\vec {vs}Lc=(D−A)c=Dc−Ac。
- Then calculate D c ⃗ D\vec{c} separatelyDc和A c ⃗ A\vec{c}Ac, and then do the difference, you can get (the right side is a matrix of n*1)
L c ⃗ = ∑ xj ∈ node adjacent to x 1 ( x 1 − xj ) ∑ xj ∈ node adjacent to x 2 ( x 2 − xj ) ∑ xj ∈ node adjacent to x 1 ( x 1 − xj ) . . . ∑ xj ∈ node adjacent to x 1 ( x 1 − xj ) L\vec{c} = \begin{matrix } \sum_{x_j\in is adjacent to x_1}(x_1-x_j)\\ \sum_{x_j\in is adjacent to x_2}(x_2-x_j)\\ \sum_{x_j\in is adjacent to x_1 Adjacent nodes}(x_1-x_j)\\ ...\\ \sum_{x_j\in Nodes adjacent to x_1}(x_1-x_j)\\ \end{matrix}Lc=∑xj∈ and x1Adjacent nodes(x1−xj)∑xj∈ and x2Adjacent nodes(x2−xj)∑xj∈ and x1Adjacent nodes(x1−xj)...∑xj∈ and x1Adjacent nodes(x1−xj)- We see each element on the right side of the matrix, the first element is the sum of the difference between the x1 node and all nodes adjacent to the x1 node, and the second element is the sum of the x2 node and all nodes adjacent to the x2 node sum of differences, ..., and so on. Therefore L c ⃗ L\vec{c}LcIt is an operation similar to aggregating information about oneself and neighbors. Recalling CNN, isn't this exactly what the convolution kernel does! ! Therefore L c ⃗ L\vec{c}LcIt is a convolution operation, so what does this have to do with the Fourier transform?
- Because L is a real symmetric matrix, L can be expressed as L = U Λ UTL = U\Lambda U^TL=UΛUThe form of T , and then bring this into the aboveL c ⃗ L\vec{c}Lc中,电影L c ⃗ = U Λ UT c ⃗ L\vec{c} = U\Lambda U^T\vec{c}Lc=UΛUTc
- According to the properties of real symmetric matrices mentioned above, UUU和UTU^TUT is an orthogonal matrix, and we know a vector (herec ⃗ \vec{c}c) If multiplied by an orthogonal matrix, it means that this vector is mapped to another coordinate space. (So the knowledge of Fourier transform is used here, and the feature c in the space domain ⃗ \vec{c}cmapped to the spectral domain space)
- 那么 L c ⃗ = U Λ U T c ⃗ L\vec{c} = U\Lambda U^T\vec{c} Lc=UΛUTcThe meaning is to first map the features in the spatial domain to the spectral domain (ie UT c ⃗ U^T\vec{c}UTc), and then perform a certain degree of transformation in the spectral domain (ie Λ UT c ⃗ \Lambda U^T\vec{c}ΛUTc), and then map the processed results in the spectral domain back to the spatial domain (ie U Λ UT c ⃗ U\Lambda U^T\vec{c}UΛUTc)
Here we seem to have found the expression method of the graph convolution formula, that is:
g θ ∗ c ⃗ = U g θ ( Λ ) UT c ⃗ g_{\theta} * \vec{c} = Ug_{\theta}( \Lambda)U^T\vec{c}gi∗c=And Mri( L ) UTc
Enclosure g θ ( Λ ) g_{\theta}(\Lambda)gi( Λ ) is aboutΛ \LambdaThe polynomial of Λ ,θ \thetaθ is the parameter to be learned in it. The meaning is to extract some transformations of features in the spectral domain space.
But what we can't ignore is that in this method we first need to decompose LLL to getUUU和UTU^TUT , the complexity here isO ( n 2 ) O(n^2)O ( n2 )When the graph is very huge, the computational complexity will be unbearable.
Therefore, if we choose a better g θ ( Λ ) g_{\theta}(\Lambda)gi( Λ ) so as to avoid decomposingLLL becomes a more necessary question.
4. Graph Convolution
According to the above analysis, we have obtained the calculation formula of graph convolution, g θ ∗ c ⃗ = U g θ ( Λ ) UT c ⃗ g_{\theta} * \vec{c} = Ug_{\theta}(\Lambda )U^T\vec{c}gi∗c=And Mri( L ) UTc
Next, we need to determine a suitable g θ ( Λ ) g_{\theta}(\Lambda)gi( Λ ) to avoid decomposingLLL , the ordinary polynomial a 1 x + a 2 x 2 + . . . + anxn a_1x+a_2x^2 + ...+a_nx^na1x+a2x2+...+anxIn fact, n is also possible, but it is easy to cause the problem of gradient disappearance and gradient explosion in the process of neural network propagation. So here we choose to use Chebyshev polynomials. (If you don’t understand here, you can look down first)
Chebyshev polynomial:
T 0 ( x ) = 1 T 1 ( x ) = x T n + 1 ( x ) = 2 x T n ( x ) − T n − 1 ( x ) T_0(x) = 1\\ T_1(x)=x\\T_{n+1}(x)=2xT_n(x)-T_{n-1}(x)T0(x)=1T1(x)=xTn+1(x)=2xTn(x)−Tn−1( x )
Properties of Chebyshev polynomials:
T n ( cos θ ) = cosn θ T_n(cos\theta) = cosn\thetaTn(cosθ)=cos n θ This ensures that no matter how large n is, there is a stable trend of swinging in the value range, which will not cause the problem of gradient disappearance or explosion.But this introduces a new problem, the domain of the independent variable is [-1,1], so the above mentioned is used here: L sym L_{sym}LsymThe value range of the eigenvalue is [0,2], this conclusion.
So we can L sym − I L_{sym}-ILsym−I is the real symmetric matrix finally determined, andit is used as the input of the Chebyshev polynomial, and the value range of its eigenvalue is exactly [-1,1]. (As for why L sym − I L_{sym}-ILsym−I is used as an input, except that it can prevent the gradient from disappearing or exploding, the most important thing is that it is a real symmetric matrix, which can avoid decomposingLLThe problem of L (this is also our core problem), the following will talk about why it can avoid decomposingLLL)
Therefore, we finally determine θ ( Λ ) = ∑ k = 0 K θ k T k ( Λ ) g_{\theta}(\Lambda)=\sum_{k=0}^K\theta_kT_k(\Lambdagi( L )=k=0∑KikTk( L )
Next, we expand the convolution formula: g θ ∗ c ⃗ = U ∑ k = 0 K θ k T k ( Λ ) UT c ⃗ g_{\theta} * \vec{c} = U\sum_{k =0}^K\theta_kT_k(\Lambda)U^T\vec{c}gi∗c=Uk=0∑KikTk( L ) UTc
g θ ∗ c ⃗ = ∑ k = 0 K θ k ( UT k ( Λ ) UT ) c ⃗ g_{\theta} * \vec{c} = \sum_{k=0}^K\theta_k(UT_k(\ Lambda)U^T)\vec{c}gi∗c=k=0∑Kik(UTk( L ) UT)c
然后由于 U T k ( Λ ) U T = T k ( U Λ U T ) UT_k(\Lambda)U^T=T_k(U\Lambda U^T) UTk( L ) UT=Tk(UΛUT )(This point can be proved by yourself, it will not be proved here)
g θ ∗ c ⃗ = ∑ k = 0 K θ k T k ( U Λ U T ) c ⃗ g_{\theta} * \vec{c} = \sum_{k=0}^K\theta_kT_k(U\Lambda U^T)\vec{c} gi∗c=k=0∑KikTk(UΛUT)c
g θ ∗ c ⃗ = ∑ k = 0 K θ k T k ( U Λ U T ) c ⃗ g_{\theta} * \vec{c} = \sum_{k=0}^K\theta_kT_k(U\Lambda U^T)\vec{c}gi∗c=k=0∑KikTk(UΛUT)c
Here we see that the input of the Chebyshev polynomial is U Λ UTU\Lambda U^TUΛUT , it is necessary to ensure that the input matrix must be a real symmetric matrix, and we mentioned above, we need toL sym − I L_{sym}-ILsym−I is used as the input of the Chebyshev polynomial, andL sym − I L_{sym}-ILsym−I is indeed a real symmetric matrix. So substituting in, the formula becomes:
g θ ∗ c ⃗ = ∑ k = 0 K θ k T k ( L sym − I ) c ⃗ g_{\theta} * \vec{c} = \sum_{k=0}^K\theta_kT_k(L_{sym }-I)\vec{c}gi∗c=k=0∑KikTk(Lsym−I)c
So far, we found that UUU和UTU^TUT is gone, i.e. no need to decomposeLLL came to find these two matrices, and we solved the core problem mentioned at the beginning. Next, let's simplify this formula to see what form it will eventually become.
In order to simplify this problem, we set K=1, that is, only take the first two Chebyshev polynomials, T 0 ( x ) = 1 T_0(x)=1T0(x)=1 andT 1 ( x ) = x T_1(x)=xT1(x)=x , expand the summation formula to get
g θ ∗ c ⃗ = θ 0 T 0 ( L s y m − I ) c ⃗ + θ 1 T 1 ( L s y m − I ) c ⃗ g_{\theta} * \vec{c} = \theta_0T_0(L_{sym}-I)\vec{c}+\theta_1T_1(L_{sym}-I)\vec{c} gi∗c=i0T0(Lsym−I)c+i1T1(Lsym−I)c
g θ ∗ c ⃗ = θ 0 c ⃗ + θ 1 ( L s y m − I ) c ⃗ g_{\theta} * \vec{c} = \theta_0\vec{c}+\theta_1(L_{sym}-I)\vec{c} gi∗c=i0c+i1(Lsym−I)c
由于L sym = D − 1 / 2 LD − 1 / 2 = D − 1 / 2 ( D − A ) D − 1 / 2 = I − D − 1 / 2 AD − 1 / 2 L_{sym}=D^ {-1/2}LD^{-1/2}=D^{-1/2}(DA)D^{-1/2}=ID^{-1/2}AD^{-1/2 }Lsym=D− 1/2 LD−1/2=D−1/2(D−A)D−1/2=I−D− 1/2 AD−1/2
Substitute:
g θ ∗ c ⃗ = θ 0 c ⃗ − θ 1 D − 1 / 2 AD − 1 / 2 c ⃗ g_{\theta} * \vec{c} = \theta_0\vec{c}-\theta_1D^{- 1/2}AD^{-1/2}\vec{c}gi∗c=i0c−i1D− 1/2 AD−1/2c
In order to further simplify the problem, we make θ 1 = − θ 0 \theta_1=-\theta_0i1=− i0, then the formula becomes:
g θ ∗ c ⃗ = θ 0 ( I + D − 1 / 2 A D − 1 / 2 ) c ⃗ g_{\theta} * \vec{c} = \theta_0(I+D^{-1/2}AD^{-1/2})\vec{c} gi∗c=i0(I+D− 1/2 AD−1/2)c
To simplify the problem again, directly I + D − 1 / 2 AD − 1 / 2 I+D^{-1/2}AD^{-1/2}I+D− 1/2 AD− 1/2 is transformed intoD − 1 / 2 A ^ D − 1 / 2 D^{-1/2}\hat AD^{-1/2}D−1/2A^D− 1/2 , of whichA ^ = A + I \hat A = A+IA^=A+I
(As for why, it is because adding the identity matrix first and then normalizing has a certain graph meaning, that is, adding a self-loop to each node, so that it is the same as c ⃗ \vec{c }cAfter multiplication, the result will retain the characteristic information of its own node, not just the sum of the difference between the characteristic values of the node and its adjacent nodes. If you don’t understand it well, you can go to https://zhuanlan.zhihu.com/ p/107162772 )
The formula then becomes:
g θ ∗ c ⃗ = D − 1 / 2 A ^ D − 1 / 2 c ⃗ θ 0 g_{\theta} * \vec{c} = D^{-1/2}\hat AD^{-1/ 2}\vec{c}\theta_0gi∗c=D−1/2A^D−1/2ci0
Compare this formula with the GCN formula we mentioned at the beginning:
H ( l + 1 ) = δ ( D ^ − 1 / 2 A ^ D ^ − 1 / 2 H ( l ) θ ) H^{ (l+1)} = \delta(\hat D^{-1/2}\hat A\hat D^{-1/2}H^{(l)}\theta)H(l+1)=d (D^−1/2A^D^− 1/2 H( l ) i)
It is found that the two formulas are completely consistent in form, so this formula is the source of the formula we gave at the beginning.
At this point, the mathematical reasoning is over.