Article directory
1. Cache model and ideas
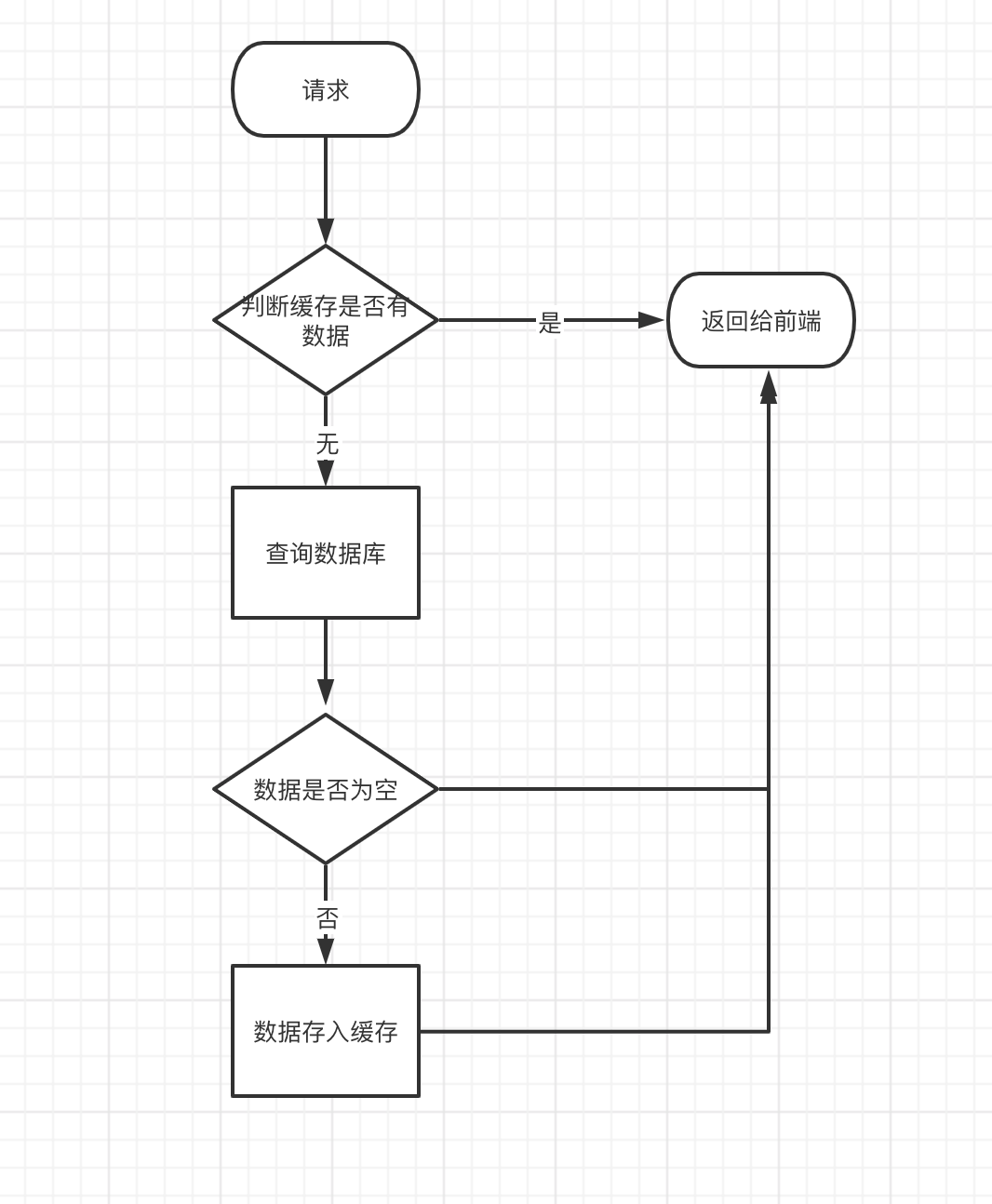
The standard operation method is to query the cache before querying the database. If the cached data exists, it will be returned directly from the cache. If the cached data does not exist, then query the database and store the data in redis.
caching model

In the project, we often use the cache to relieve the pressure on the database:
2. Cache update strategy
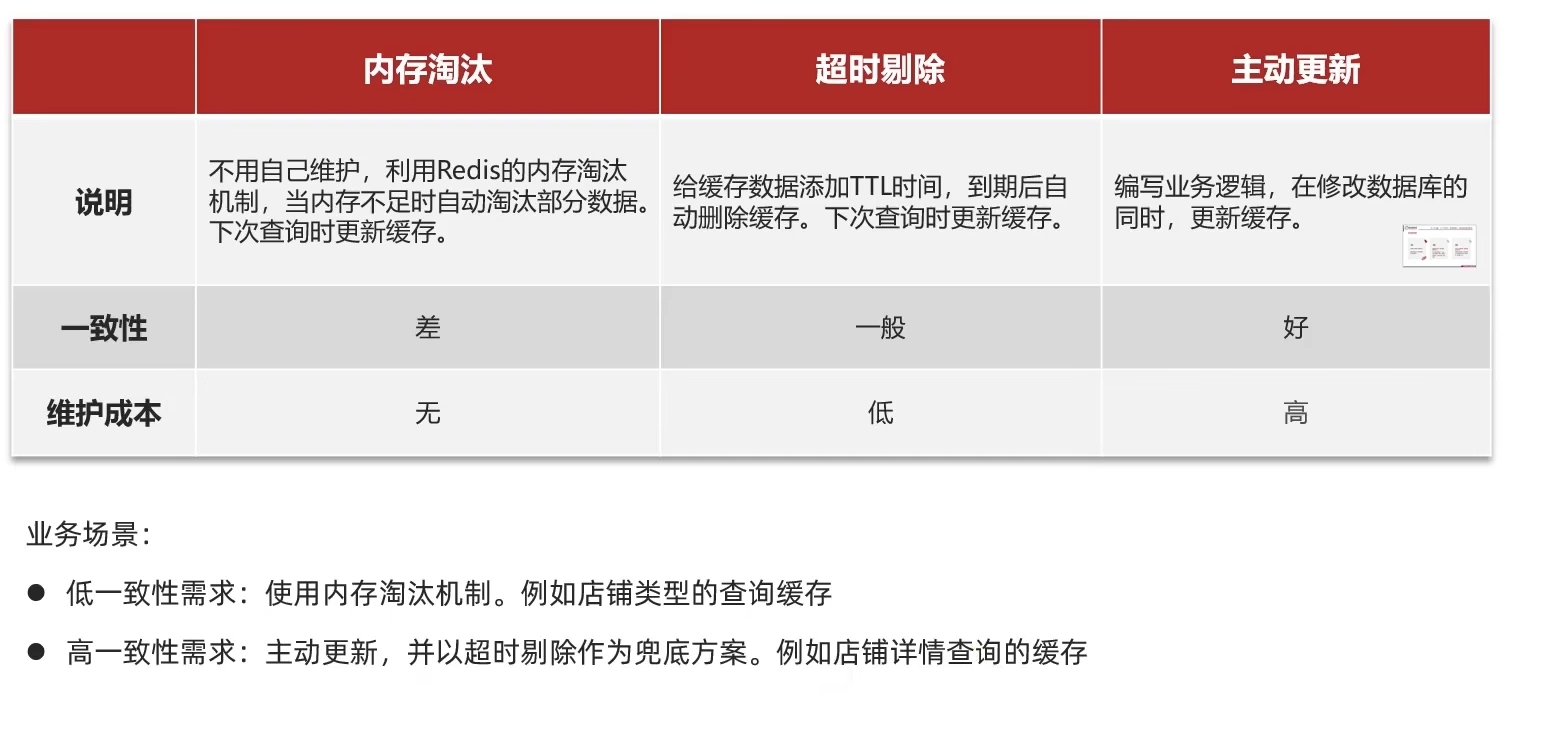
Cache update is a thing designed by redis to save memory, mainly because the memory data is precious. When we insert too much data into redis, it may cause too much data in the cache, so redis will process some data Update, or it is more appropriate to call him eliminated.
Memory elimination : redis is automatically carried out. When the redis memory reaches the max-memery we set, it will automatically trigger the elimination mechanism to eliminate some unimportant data (you can set the strategy by yourself)
Timeout removal : When we set the expiration time ttl for redis, redis will delete the timed out data so that we can continue to use the cache
Active update : We can manually call the method to delete the cache, which is usually used to solve the problem of inconsistency between the cache and the database
active update
-
Delete cache or update cache?
-
Update cache: every time the database is updated, the cache is updated, and there are many invalid write operations
-
Delete cache: invalidate the cache when updating the database, and then update the cache when querying == (choose this) ==
-
For example: if the database is updated 1000 times within 1 hour, then the cache will also be updated 1000 times, but this cache may only be read once after the last update, so is the first 999 updates necessary?
Conversely, if it is deleted, even if the database is updated 1000 times, then only one cache deletion is performed (judging whether the key exists before deletion), and the database is loaded only when the cache is actually read
-
-
-
How to ensure the success or failure of cache and database operations at the same time?
- Monolithic system, put cache and database operations in one transaction
- Distributed system, using distributed transaction schemes such as TCC
-
Do you operate the cache first or the database first?
- Delete the cache first, and then operate the database
- Operate the database first, then delete the cachechoose this
3. Two solutions
3.1. Delete the cache first, then update the database
Delete the cache first, and the database has not been updated successfully. At this time, if the cache is read, the cache does not exist, and the old value is read from the database, and then the cache is updated, and the cache inconsistency occurs. As shown in the picture:
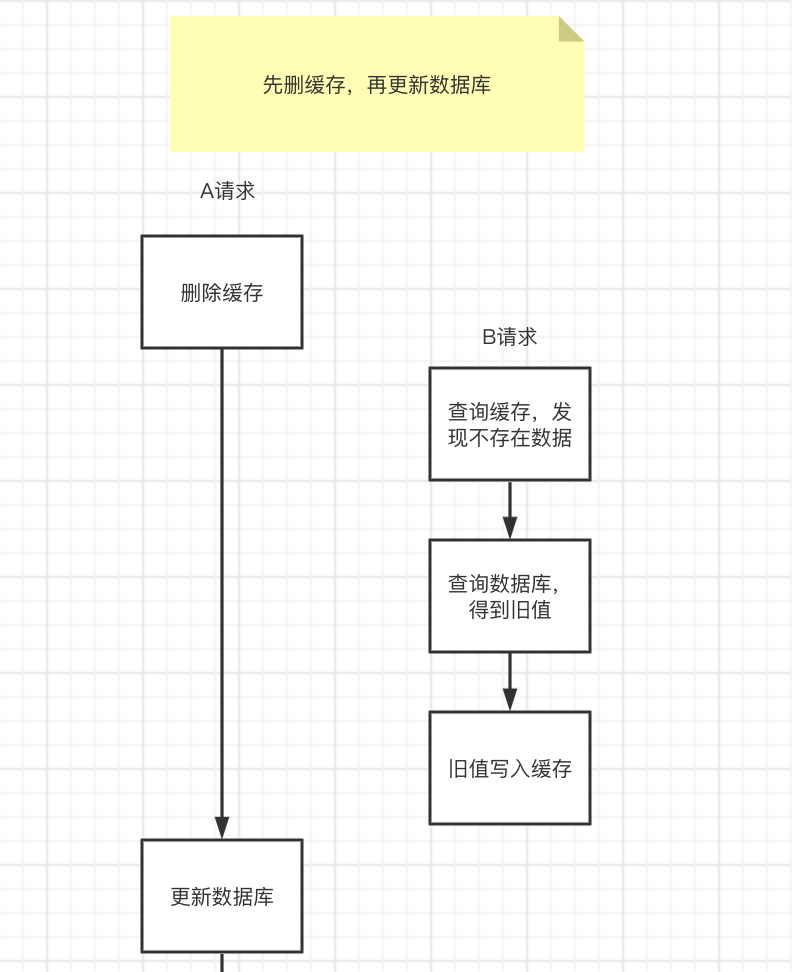
Cache inconsistency issues can occur in extreme cases
- Request A to come first and delete the cache. However, due to network reasons, it froze for a while and had not had time to update the database.
- At this time, request B came over. First query the cache and found no data, then check the database, there is data, but the old value.
- Request B to update the old value in the database to the cache.
- At this point, request A stops and writes the new value into the database.
3.1.1 Delayed double deletion (to solve the cache inconsistency problem caused by deleting the cache first and then updating the database)
The above problem can be solved with a delayed double-delete solution. The idea is that after updating the database, sleep for a while, and then delete the cache again.
The sleep time should be evaluated based on the business read and write cache time, and the sleep time should be longer than the read and write cache time.
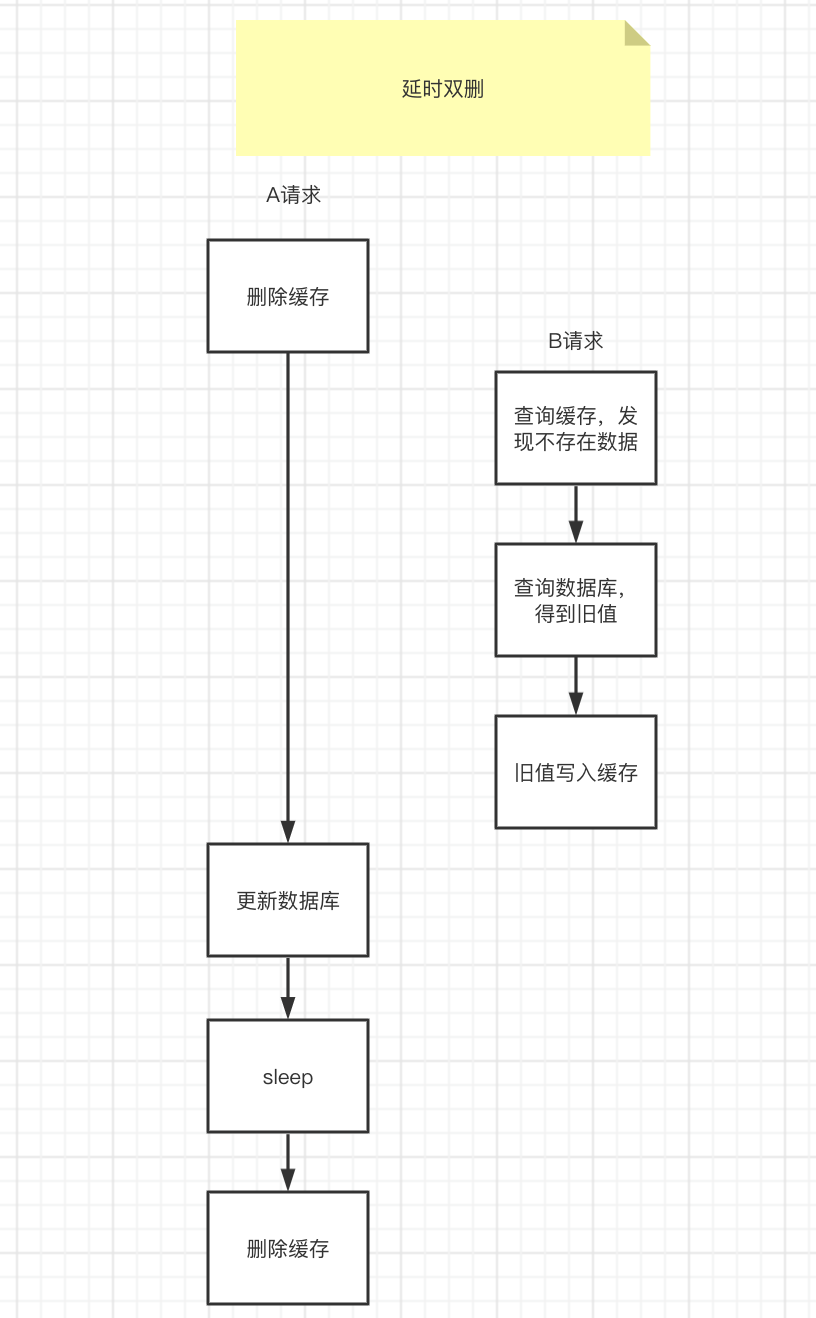
- Thread 1 deletes the cache and then updates the database
- Thread 2 reads the cache and finds that the cache has been deleted, so it reads directly from the database. At this time, because thread 1 has not been updated, it reads the old value, and then writes the old value into the cache
- Thread 1, according to the estimated time, sleep, because the sleep time is greater than the time of thread 2 reading data + writing cache, so the cache is deleted again
- If there are other threads to read the cache, the latest value will be read from the database again
1. What is delayed double deletion
The delayed double-deletion strategy is a common strategy for maintaining consistency in database storage and cache data in a distributed database, but it is not strong consistency. In fact, no matter which solution is used, the problem of dirty data in Redis cannot be avoided, but can only be alleviated. To solve it completely, it is necessary to use synchronization locks and the corresponding business logic level to solve it.
2. Why delay double deletion?
Generally, when we update database data, we need to synchronize the data cached in redis, so there are two methods:
The first solution: execute the update operation first, and then execute the cache clearing.
The second solution: perform the cache clear first, and then perform the update operation.
The disadvantage of these two solutions is that when there are concurrent requests, the following problems are prone to occur:
The first solution: After request 1 executes the update operation, there is no time to clear the cache. At this time, request 2 queries and uses the old data in redis.
The second solution: After request 1 clears the cache, the update operation has not yet been performed. At this time, request 2 queries the old data and writes it to redis.
3. How to implement delayed double deletion?
Execution steps of delayed double deletion scheme
1. Delete redis
2. Update database
3. Delay for N seconds (N seconds is longer than the time of a write operation, generally 3-5 seconds)
4. Delete redis
- Question 1: Why is there a delay of N seconds?
This is so that we can complete the database update operation before deleting redis for the second time.
Imagine that if there is no third step operation, there is a high probability that after the two operations of deleting redis are completed, the data in the database has not been updated. If there is a request to access the data at this time, the above mentioned at the beginning will appear that question. - Question 2: Why do we need to delete redis twice?
If we do not have a second delete operation, and there is a request to access data at this time, it may be redis data that has not been modified before. After the delete operation is executed, redis is empty and there is a request When you come in, you will visit the database. At this time, the data in the database is the updated data, which ensures the consistency of the data.
4. Summary
- Delayed double deletion achieves the final consistency of mysql and redis data in a relatively concise way, but it is not strong consistency.
- The delay is because the data synchronization between mysql and redis master-slave nodes is not real-time, so you need to wait for a while to enhance their data consistency.
- Latency refers to the current request logic processing delay, not the current thread or process sleep delay.
- The data consistency between mysql and redis is a complex topic, and usually multiple strategies are used at the same time, such as: delayed double deletion, redis expiration and elimination, serial processing of the same type of data through routing strategies, distributed locks, etc.
3.2. Update the database first, then delete the cache

the first case
- Request a to write to the database first. Due to network reasons, it froze for a while and did not have time to delete the cache.
- Request b to query the cache, find that there is data in the cache, and return the data directly.
- Request a to delete the cache.
the second case
But what if the read data request comes first?
- Request b to query the cache, find that there is data in the cache, and return the data directly.
- Request a to write to the database first.
- Request a to delete the cache.
This situation looks fine.
third case
But I am afraid of one situation: cache failure.
- The cache is automatically invalidated.
- Request a to query the cache, there is no data in the cache, and the old value of the database is queried, but due to network reasons, the cache is stuck and there is no time to update the cache.
- Request b writes to the database first, and then deletes the cache.
- Request a to update the old value into the cache.
as the picture shows:
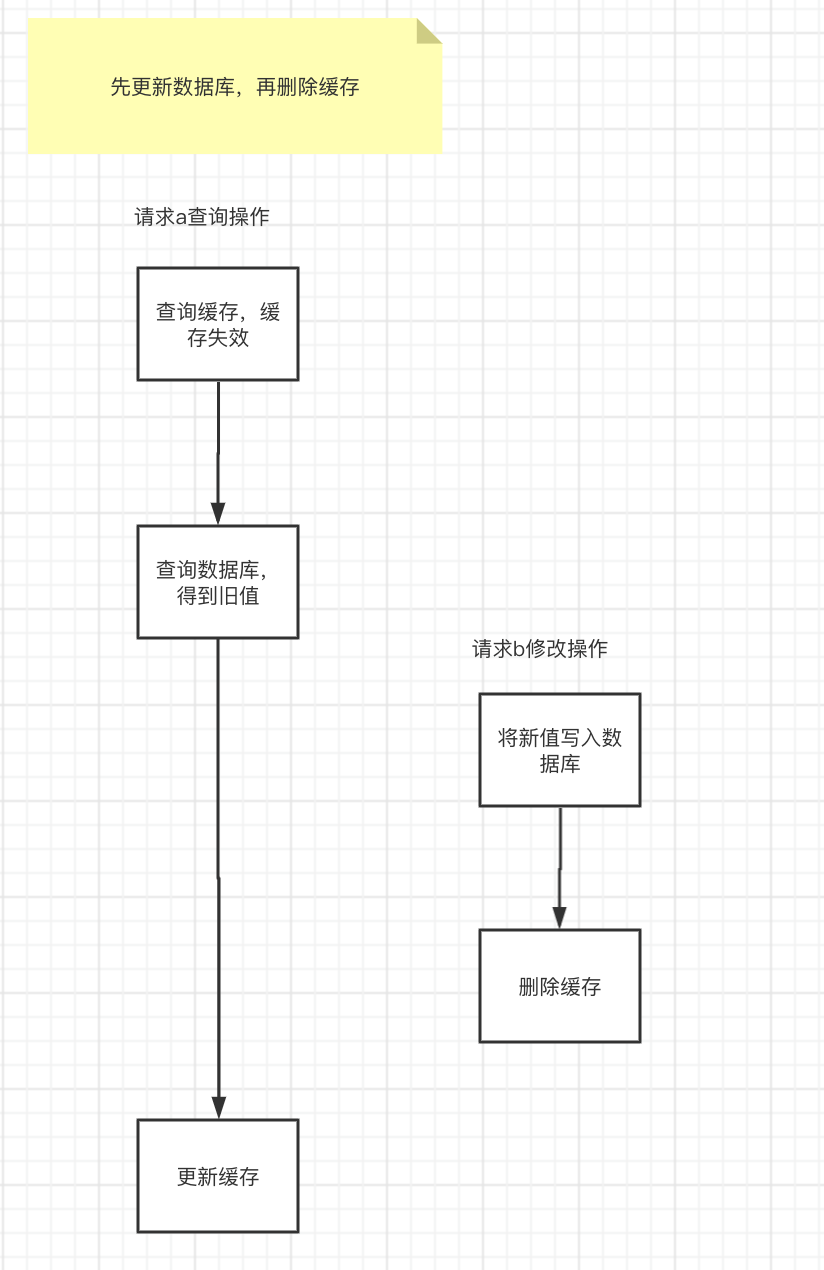
At this time, the data in the cache and the database are also inconsistent. However, this situation is still relatively rare, and the following conditions must be met at the same time:
-
The cache just happens to be invalidated automatically.
-
Requesting a to find out the old value from the database and updating the cache takes longer than requesting b to write to the database and delete the cache.
What should I do if I fail to delete the cache?
In fact, the scheme of writing to the database first and then deleting the cache is the same as the scheme of double-deleting the cache. It has a common risk point, that is: what should I do if the cache deletion fails?
Solution 1: Set the expiration time
The cache sets an expiration time, such as 5 minutes. Of course, this solution is only suitable for businesses with infrequent data updates.
Solution 2: Synchronous retry
Determine whether the deletion is successful in the interface, and retry if it fails, until it succeeds or exceeds the maximum number of retries, and returns the data. Of course, the disadvantage of this solution is that it may affect interface performance.
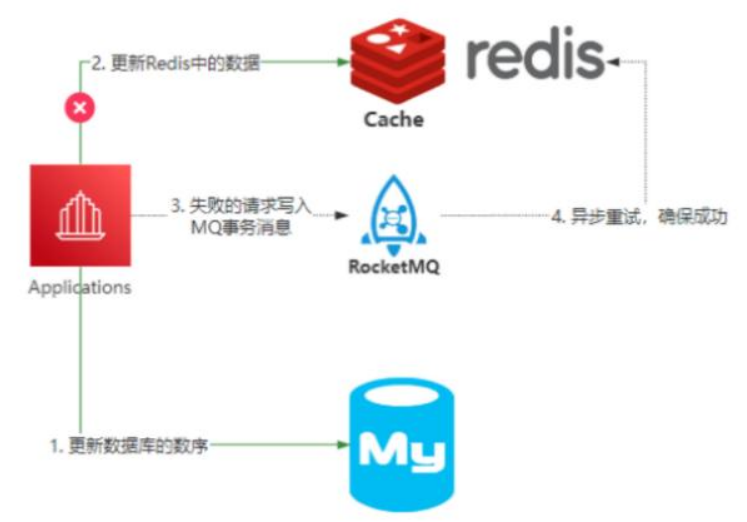
Solution 3: Message Queue
Write the delete cache task into message middleware such as mq, and process it in the consumer of mq. But there are many problems:
- After the introduction of message middleware, the problem is more complicated. What should I do if the business code is intrusive and the message is lost?
- The delay of the message itself will also cause short-term inconsistencies, but this delay is relatively acceptable
For example, based on RocketMQ's reliable message communication, to achieve final consistency.
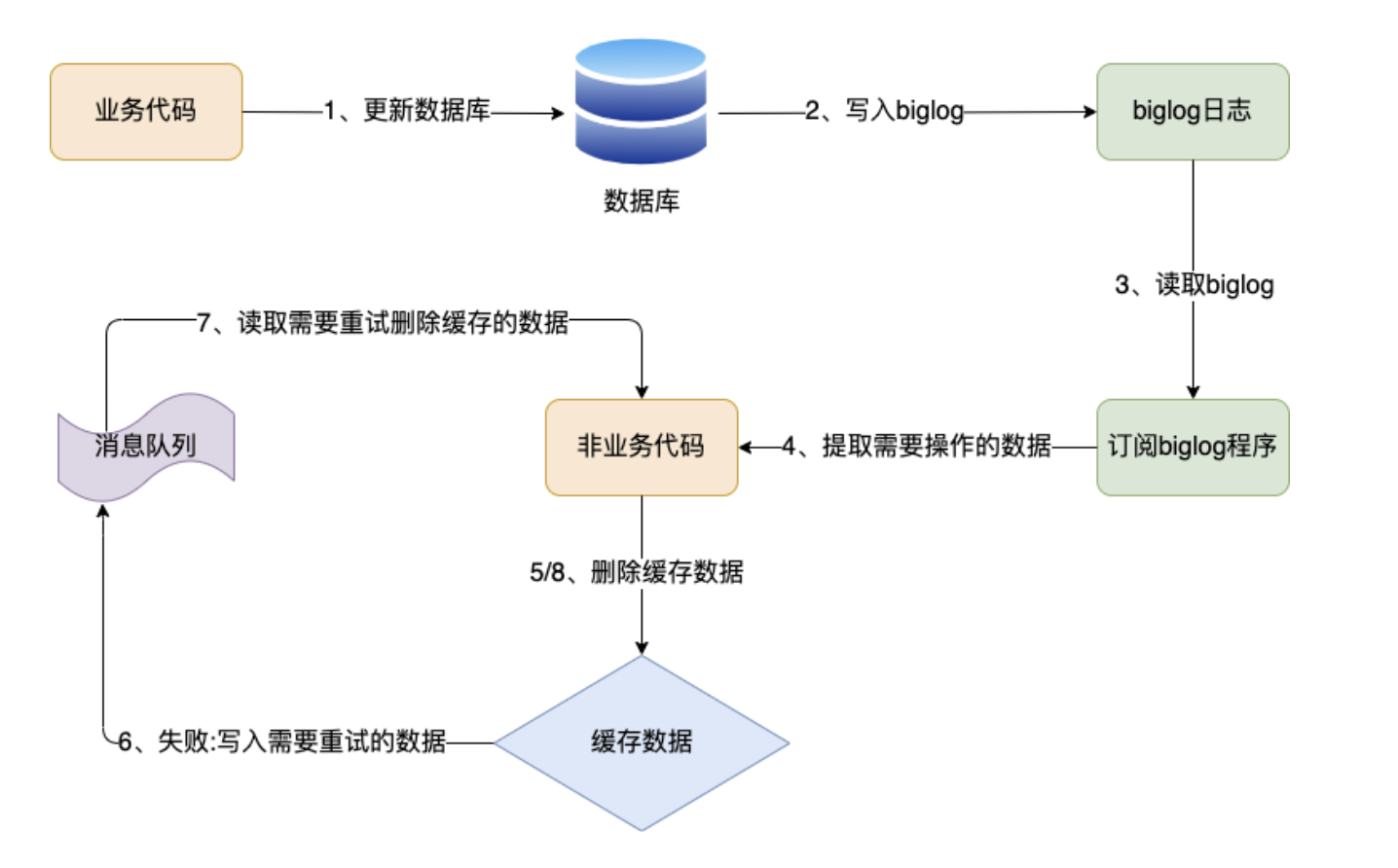
Solution 4: Subscribe to mysql binlog
We can use the message queue that listens to the binlog to delete the cache. The advantage of this is that the deletion action does not need to invade the business code, and the message middleware helps you decouple. At the same time, the middleware itself guarantees high availability.
4. Summary
There are two ways to delete the cache
-
Delete the cache first, then update the database. The solution is to use delayed double delete.
-
Update the database first, then delete the cache. The solution is to use message queues or monitor binlog synchronization. The introduction of message queues will cause more problems and is invasive to business code, so it is not recommended to use them directly.
For scenarios where cache consistency requirements are not very high, it is sufficient to only set the timeout period.