1. Brief introduction of the paper
1. First author: Yongrong Cao
2. Year of publication: 2022
3. Published journals: BMVC CCF-C category
4. Keywords: MVS, 3D reconstruction, context, self-attention, global information
5. Exploration motivation: The limitation of CNN, the lack of global context usually leads to local ambiguity in untextured or weakly textured regions, thus reducing the robustness of matching.
- Local features are well captured by convolutions. The locality of convolution features prevents the perception of global context information, which is essential for robust depth estimation at challenging regions in MVS, such as weak texture, repetitive patterns, and non-Lambertian areas.
- When decoding matching costs, the features to be simply added, and potential depth information correspondences are not taken into consideration.
- Convolution operation has strong ability to extract local feature information, such as texture and color. However, for a whole input image, the correlation degree of the relevant information of the image itself seriously affects the learning of the global features of the object.
6. Work goal: Self-attention can mine global context in each view.
Self-attention modules complement convolutions and help model long-range, multi-level dependencies across image regions. With self-attention, the network can capture images in which fine details in each local area are carefully coordinated with fine details in distant parts of the image.
7. Core idea:
- We propose a novel end-to-end deep neural framework, namely Global Context Complementary Network (GCCN), for robust long-range global context aggregation within images. Moreover, the combination of local and global information contributes to converge network.
- In addition, to better regress the depth map, we introduce a contextual-feature complementary learning module to restore the 3D structure information of the scene.
8. Experimental results:
Our method achieves state-of-the-art results on the DTU dataset and the Tanks & Temples benchmark.
9. Paper download:
https://bmvc2022.mpi-inf.mpg.de/919/
2. Implementation process
1. Overview of GCCN
The structure is shown in the figure. Using CVP-MVSNet as the backbone network, given 1 reference image and N source images:
- First, build an image pyramid from high to low resolution. Then, features are extracted using FPN. Next, a cost body pyramid structure is adopted to share weights at each level. The op can be trained on low-resolution images and still work on any high-resolution images during inference. Finally, the cost volume is regressed by 3D CNN, and the final depth map is estimated.
- GCCN introduces the Global Context Interaction Module (GCIM), which mainly includes two key points: local detail extraction and global feature acquisition. This combination not only prevents the network from deteriorating, but also captures the long-distance dependencies between the underlying semantic features and high-level structural features. Therefore, feature images contain rich local and global feature information.
- GCCN introduces an effective Contextual Feature Complementary Learning Module (CCLM) strategy in the 3D CNN regression cost volume calculation, which can complementarily learn the features of two input cost volumes of different depths. Finally, the depth map is constrained by a pixel-wise loss.

2. Global Context Interaction Module (GCIM)
The GCIM module can effectively combine local and global features to improve the performance of the network in the 2D feature extraction stage. As shown in the figure below, the convolutional neural network (CNN) is utilized to extract local details in the lower branch. At the same time, self-attention is used to learn the overall information of another branch. Finally, according to the importance of channels, the SE fusion module is adopted to better integrate the complementary features of local dependent features and long-range dependent features. In order to prevent network damage, GCIM is based on skip connections and self-attention mechanisms to prevent network overfitting.

3. Contextual Feature Complementary Learning Module (CCLM)
CVP-MVSNet, its 3D cost body regression network adopts a standard 3D CNN U-shaped network, and the process is divided into encoding (downsampling) part and decoding (upsampling) part. The 3D cost body structure of the same depth in the encoding stage and the decoding stage is directly connected. Due to the limitations of the U-shaped structure itself, downsampling and then upsampling will lead to the weakening of high-level semantic information and the loss of spatial information, thus affecting the final integrity of the depth map. To effectively fuse 3D cost volumes and preserve rich contextual relations at different depths, a Contextual Feature Complementary Learning Module (CCLM) is adopted. CCLM decodes the wider contextual information between the features of two layers into local features, thus enhancing their representation ability. The specific operation steps of CCLM are shown in the figure below.

Given two layers of 3D cost bodies f eature_x, f eature_y ∈ C×D×H×W with inconsistent depths, they are first input into a convolutional layer with a stride of 1 × 1 × 1 to generate two new feature maps respectively Xout and Yout. Then, a matrix multiplication is performed between the transposes of Xout and Yout, and a softmax layer is applied to compute a spatial attention map S−XY.
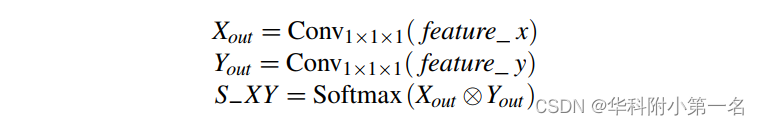
At the same time, matrix multiplication is performed between Yout and the transpose of S−XY to obtain the feature F−XY. Finally, we perform an element-wise summation over feature_y and F−XY, defined as:
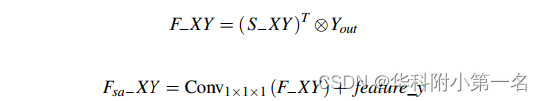
F−XY is the correlation coefficient matrix of the input 3D cost body feature_x and feature_y, and Fsa−XY is the 3D cost body output after the context feature complementary learning module.
4. Loss function
Similar to the existing coarse-to-fine MVS, a mean absolute error (MAE) is applied at each scale to supervise the depth estimation results at different resolutions, which can be expressed as:

Among them, Pvalid represents the valid pixel set in the real depth map, and l represents the number of layers of the pyramid image. During training, l is set to 2. The predicted initial depth map is upsampled to the same size as the input image pyramid, and then error values are accumulated layer by layer.
5. Experiment
5.1. Implementation Details
Implemented with PyTorch, trained on GPU of NVIDIA GeForce GTX 1080Ti and CPU of Intel Core i9-9900K [email protected] GHz. During training, the number N of source images is set to 2, and the resolution of input images is set to 640×512. Adam optimized the network.
5.2. Comparison with advanced technologies

No results on Tanks & Temples data.