I. Introduction
Just when I was struggling with how to combine optimizers and learning rate adjustment methods, I saw this article, which really made me suddenly enlightened.
There is no basis for words, and the comparison of experimental data can explain the problem better. Seemingly metaphysics, alchemy (training) also has a way. Worship the boss!
Two, the text
The author of this article simulated and reproduced various situations that he may encounter during the deep learning training process, and tried to solve these problems. The article revolves around learning rate, momentum, learning rate adjustment strategy, L2 regularization, and optimizer.
"The depth model is a black box, and this time I did not try an ultra-deep and ultra-wide network, so the conclusion can only provide a priori, not a standard answer! At the same time, different tasks may also lead to differences, such as segmentation, so it must be specific Analyze the problem in detail!"
I participated in several CV competitions a while ago, and found such a problem: Although the theoretical knowledge I understand is not particularly small, and the experiments and paper codes I have run are okay, but there will always be some strange problems in practice, and then It is also a bit uncomfortable to solve, so I plan to simulate and reproduce the situation as much as possible, try to solve it and explain it (but the reason for the explanation can only be justified, after all, black box experiment), so as not to encounter similar situations in the future without solving it train of thought.
During this golden week, I obediently did a few days of experiments in the research institute, mainly around the following keywords:
"Learning rate; momentum; learning rate adjustment strategy; L2 regularization; optimizer"
(All the conclusions are supported by experiments, but some of the experimental data are lost to me...555)
Thinking
In these experiments and some materials (mainly Wu Enda's "Machine Learning Yearning"), the following basic principles are summarized:
1. Factors affecting model performance:
a. Model expressiveness (depth and width) b. Learning rate c. Optimizer d. Learning rate adjustment strategy
2. Influencing factors of model overfitting:
a. Data volume (data augmentation can increase data volume)
b. Regularization
A little explanation: the expressiveness of the model does have a certain impact on whether the model is overfitting, but choosing an appropriate regularization strength can effectively slow down this effect! So I did not include the expressive ability of the model as an over-fitting factor. And Wu Enda's book ("Machine Learning Yearning") also expressed a similar idea (very happy, I have the same idea as the boss).
lab environment
Resnet-18
Cifar-10
Details
Learning rate and momentum I will talk about learning rate and momentum together, because I found that these two things are a natural couple. Friends who understand deep learning should know that there will be problems if the learning rate is too large or too small:
"Excessive learning rate will cause the model to fail to enter the local optimum or even cause the model to explode (failure to converge). Too small learning rate will lead to slow model training and waste time"
Is there a way to make the model training fast and convergent? have!
I came to the following conclusions after four experiments:
Using a large learning rate + large momentum can speed up the training of the model and quickly converge
"The experimental design is as follows (I forgot to save the experimental graph, sorry!):
Experiment 1: Small learning rate + small momentum Result: The model training speed is slow, although it converges, the convergence speed is very slow, and the performance on the verification set is very stable
Experiment 2: Small learning rate + large momentum Result: The model training speed is slow, although it converges, the convergence speed is very slow, and the performance on the verification set is very stable
Experiment 3: Large learning rate + small momentum Result: The model training speed is fast, although it is difficult to converge and the performance on the verification set fluctuates greatly, indicating that the model is very unstable
Experiment 4: Large learning rate + large momentum Result: The model is trained quickly and converges quickly, and the performance on the verification set is very stable”
I think this reason can be explained from two perspectives, one is the particularity of vector addition; the other is explained from the perspective of the integrated model. I won't talk about the first angle here, because I don't want to draw a picture. . , I come from the second point of view:
A large learning rate means instability, but because this learning rate can also make the model go in the correct direction of optimization, you can understand that a large learning rate is a weak machine learning model; when you use a large momentum , which means that the learning rate this time has a smaller effect on the final model optimization, that is to say, the use of large momentum -> the proportion of a single loss function is low, which means that the optimization of my model is composed of this time + a lot in the past The comprehensive result calculated by the secondary learning rate (weak machine learning model), is that an integrated model~ so, the effect is better.
Just to mention it, when the model is very unstable, if there is a better result at a certain moment, such as an accuracy rate of 98%, it does not mean that the model is a good model at this moment, because your model is very good at this time. Might be overfitting to the validation set! If you don’t believe me, you can divide a test set and try (I fell in place when I participated in the brain PET recognition competition).
2. Learning rate adjustment strategy
In the past, I hardly used the learning rate adjustment strategy, because I thought it was ridiculous and the effect was not great, but when I played the Hualu Cup with my little brother a while ago, I saw that he used cosine annealing and it had a good effect, so I decided to try it too. , the conclusion is: really fragrant!
Sorry, I also forgot to save the experiment diagram here, sorry!
I tried 3 learning rate adjustment strategies, namely: 1.ReduceLROnPlateau; 2. Cosine annealing; 3. StepLR
in conclusion:
All three strategies are good
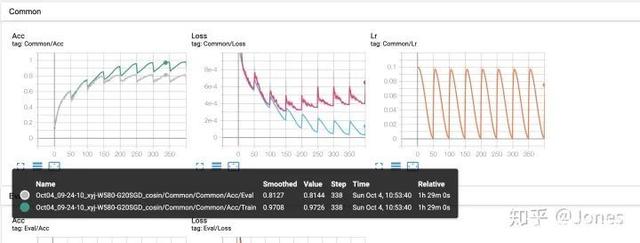
a. When cosine annealing is used, the magnitude of the difference between the maximum learning rate and the minimum learning rate should not be too large (such as 1e-1 and 1e-4), otherwise it will lead to too slow when it should be fast, and too fast when it should be slow , especially when it is close to the optimal solution, if it is too large, it will directly deviate (Figure 1) [in the Acc graph, the gray curve is the accuracy rate on the verification set. ignore this]
b. Cosine annealing I recommend that it can be used during warm-up, and you can change it later
c.ReduceLROnPlateau I think it is the best among the three, and it can be adjusted dynamically according to the training situation (there are also some mysterious situations (mode parameters), which I will talk about later), what needs to be noted is that when using this It is best to set the minimum learning rate, otherwise the model will not be able to be trained later because the learning rate decays too small.
d. StepLR is very traditional and easy to use, but its flexibility is not as good as ReduceLROnPlateau.
3. L2 regularization
There are two main types of regularization, one is L1 and the other is L2, because pytorch comes with L2, so I only use L2 (hee hee), and directly conclude:
a. Do not adjust L2 too large, otherwise it will be very difficult to train (difficult to train/unable to train the mark is that the performance on the verification set has been fluctuating at a low level, not as good as 10% -> 12% -> 9%), This means that our model has not learned anything
b. L2 should not be too small, otherwise the overfitting will be serious, about 1e-2 can have a good effect (resnet18)
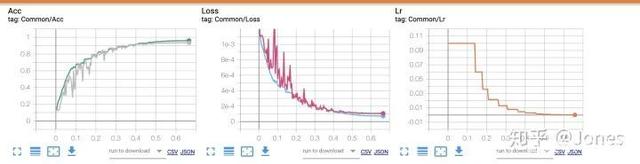
c. Even if the regularization strength is used correctly, it will cause the verification set to be unstable in the early stage or even fail to train, but it will stabilize later! Don't panic! (As shown in Figure 2, in Acc, the gray curve is the accuracy of the model on the verification set)
4. Optimizer
I will save the picture for the optimizer part!
In fact, the optimizer is not only tested here, it should be the optimizer + learning rate strategy + momentum
In fact, what I want to do is to find an optimal solution that can be used as my prior knowledge.
I did several sets of experiments:
First group:
a.SGD (large initial learning rate) + momentum (large momentum) +StepLR + L2 (every 70 epochs, the learning rate decays to the previous 0.1)
b. Adam (large initial learning rate) + StepLR + L2 (every 70 epochs, the learning rate decays to the previous 0.1)
c.AdamW (large initial learning rate) +StepLR + L2 (every 70 epochs, the learning rate decays to the previous 0.1)
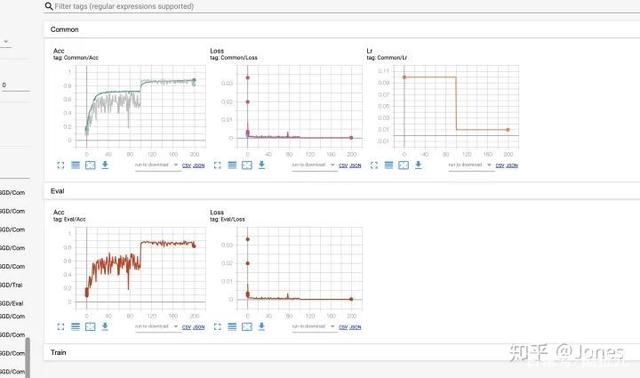
Conclusion (Figure 3):
a. SGD+momentum works better when the learning rate is large and the momentum is large;
b. Whether it is SGD or Adam or AdamW, the adjustment of the learning rate is helpful to them

Second Group:
a.ReduceLROnPlateau(mode='min') + SGD (large learning rate) + momentum (large momentum) + L2
b.ReduceLROnPlateau(mode='max') + SGD (large learning rate) + momentum (large momentum) + L2
c. Cosine annealing + SGD (large learning rate) + momentum (large momentum) + L2
"First explain the two modes of ReduceLROnPlateau: min and max. When the model is min, if the indicator A does not decrease for a period of time, the learning rate decays. When the model is max, if the indicator A is in a period of time If there is no increase in the learning rate, the learning rate decays."
When I choose the mode of ReduceLROnPlateau as the min mode, the indicator is acc. It is very interesting that its convergence speed is very fast (faster than the mode is max). I guess the reason should be:
When the acc increases, it means that the optimization direction is correct, and the optimization speed should be slowed down at this time! But in this experiment, the optimal solution is worse than the max mode (the optimal solution in min mode is 0.916, and max is 0.935). There should be two reasons:
1. It is because the decay rate of lr is too fast, so that the learning rate is too low later, and the training does not move; (I did an experiment later to prove that this is the reason!)
2. Because the learning rate is reduced as soon as it encounters a place that can be optimized, it is very likely that the model will enter the local optimum prematurely (but I later felt that this reason was untenable hahaha, because even if other optimizers are used, it will also There is a problem of falling into local optimum, so this point is not important, but in order to preserve the thinking process from experiment to notes, I still do not delete this point.)
For reason 1, I did an experiment to verify it later. The idea of the experiment is to reduce the value of the learning rate decay period and decay coefficient/set the minimum learning rate to ensure that the learning rate in the later stage will not be too small, and finally solve the problem of the optimal solution. .

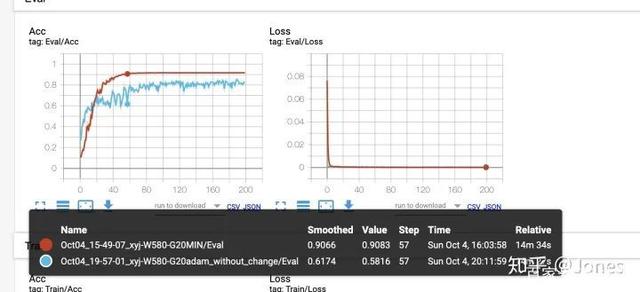
Conclusion (Figure 4):
a. SGD with momentum plus cosine annealing converges faster and more stable (the other two are not bad either!)
b. It is best to set a lower limit for the learning rate, otherwise the training will not stop later
The third group:
a.StepLR+ SGD (large learning rate) + momentum (large momentum) + L2 (Figure 5)
b. Adam + L2 (Figure 6)
in conclusion:
a. For SGD+momentum, this thing is still very sensitive to the learning rate, so it is best not to just use it, it is best to add some other strategies (cosine/ReduceLROnPlateau).
b. Pure Adam is very rubbish, - - the initial value I gave it is 1e-3, but compared with the previous results, it is very poor in terms of stability and convergence speed.
By the way: I also tried simulated annealing + Adam, but because the annealing range is too large, the effect is even worse (my pot). Next time try normal amplitude annealing.
experience:
From the above experiments, it can be seen that monument is very, very important, so that SGD, which is a bit rubbish, will go to the sky at once (no wonder the paper likes to use this pair of couples). At this time, some learning rate adjustment strategies (annealing/ReduceLROnPlateau) can be added. Go directly to heaven, let alone, I will start this combination first in the future.
Compared with SGD, Adam is indeed much better, but compared to the optimal combination (SGD+momentum+learning rate adjustment strategy), it is a little weaker. (A big guy from Qualcomm told me to try using nadam in the group of Char Siu Brother, because nadam can be understood as Adam+monument, but because pytorch does not have a corresponding API officially, I am too lazy to try it, but I believe it should be very easy. fierce!)
Reprinted in: Baidu Security Verification
If there is any infringement, please contact me to delete the article.