HashMap
After reading the source code, the harvest is not small. It is better to write an article by yourself than to read many articles. Adhering to the principle of insisting on output, the length of this article may be very long O(∩_∩)O, and it will be more fragrant for review! I think a new technology will appear to solve some problems. To learn a new technology, you must first understand what it does? how to use? , and then what is his realization principle? The last thing is how to implement (source code), so sometimes it is not friendly to directly upload the source code! There is no reason to put the source code there is just playing hooligans haha
What does HashMap in data structure look like? Its structure and underlying principles?
1. This is about jdk1.7 and 1.8 points
1.1、在jdk1.7是这样的
HashMap is a very commonly used data structure. It is a data structure composed of an array and a linked list. Every place in the array stores an instance of Key-Value. It is called Entry in Java7 and Node in Java8.

We know that HashMap is stored in the form of key-value pairs. When put is inserted, an index value will be calculated according to the hash of the key, and then inserted into the specific position of the array according to the hash value. This is also the reason why HashSet is out of order. The details are as follows: put
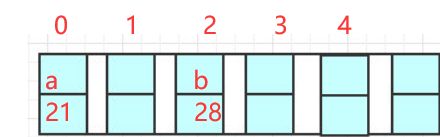
( "b", 28), put("a", 21), for these two elements, if hash(b)=2, then the element b will be added at the position of index=2, and the same is true for put element a in this way
Why introduce a linked list again?
哈希本身就存在概率性,有可能出现两个key计算出来的hash值是相同的
这就导致了哈希冲突,同一个位置需要插入两个元素
解决办法就是在下方生成一个链表来储存相应的元素
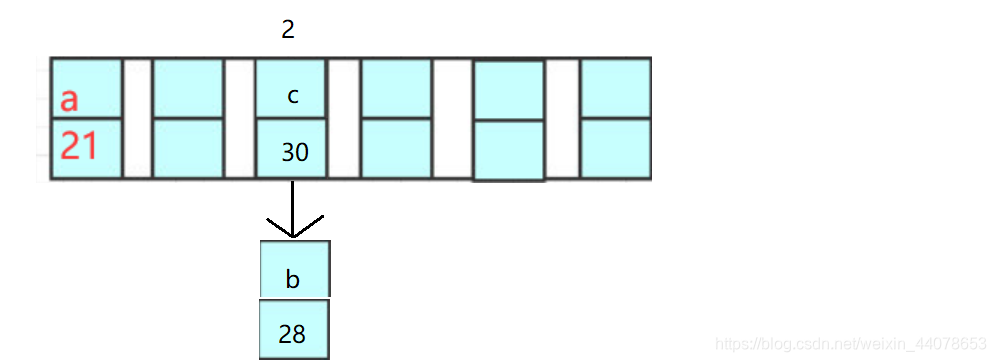 put("c", 30)
put("c", 30)
Assuming that c, b and hash value are both 2, the above situation occurs, then a linked list will be generated at the position of 2 to store the new element
In fact, there is another problem here. How does the hashmap determine that b and c are not the same element? What if there are two b stored? We can see that, but the machine will only execute orders!
It stands to reason that the same hash value should not be overwritten directly?
In fact, when there is a hash conflict, it is necessary to add new elements to the linked list. There is also an eques method to compare whether the content of the key is consistent. The key is generally stored with a string of type String, and it happens that String rewrites this Two methods (hashCode and eques) (the string "gdejicbegh" and the string "hgebcijedg" have the same hashCode() return value -801038016, and eques can compare them to be different), in this case Satisfied to add the corresponding element on the linked list
The storage of the elements mentioned above is called Entry in Java7 and Node in Java8, so how are new elements added to the linked list?
The tail insertion method is used after Java8 , and the head insertion method is used in Java7 and before. record each element)
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//根据key计算的hash值
final K key;//key
V value;//值
Node<K,V> next;//下一个元素
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
Why use header insertion? Why was it changed to tail plugging later?
We all know that the query speed of linked list is very slow. Is it because the new put element has a high probability of being get, so putting it in the front improves the query efficiency in a sense? I thought so!
But when it comes to why it was changed to the tail plug method, it must be that there is a problem with the head plug method that needs to be solved. The emergence of this problem involves its expansion mechanism
resize()? 1.7 How to expand?
In 1.7, a new Entry array will be created with twice the length of the original, and the source code explanation will be given first (the content of the short book: https://www.jianshu.com/p/08e12481c611 is quoted)
void transfer (HashMapEntry[]newTable ){
//新容量数组桶大小为旧的table的2倍
int newCapacity = newTable.length;
// 遍历旧的数组桶table
for (HashMapEntry<K, V> e : table) {
// 如果这个数组位置上有元素且存在哈希冲突的链表结构则继续遍历链表
while (null != e) {
//取当前数组索引位上单向链表的下一个元素
HashMapEntry<K, V> next = e.next;
//重新依据hash值计算元素在扩容后数组中的索引位置
//(Hash的公式---> index = HashCode(Key) & (Length - 1))因为长度变了
//所以需要重新计算
int i = indexFor(e.hash, newCapacity);
//将数组i的元素赋值给当前链表元素的下一个节点
e.next = newTable[i];
//将链表元素放入数组位置
newTable[i] = e;
//将当前数组索引位上单向链表的下一个元素赋值给e进行新的一圈链表遍历
e = next;
}
}
}
The entire expansion process is to take out the array element (each element at the actual array index position is the head of each independent one-way linked list, that is, the last conflicting element put in after the Hash conflict occurs) and then traverse the element headed One-way linked list elements, calculate their subscripts in the new array based on the hash value of each traversed element and then exchange them (that is, the tail of the one-way linked list with the original hash conflict becomes the head of the expanded one-way linked list)
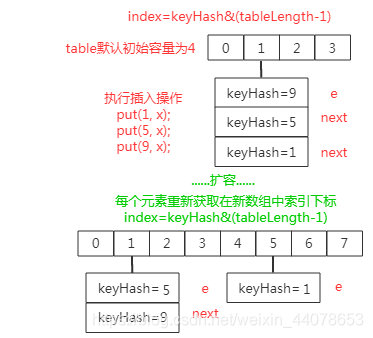
Back to the topic, what problem does this lead to?
In the picture above, we can see that after the capacity expansion is completed by using the header insertion method, such a situation will occur. In the original linked list in the picture above, 9–>5–>1 and the new linked list 5–>9, but at this time. The next element node of 9 still points to 5, causing an infinite loop of 5–>9–>5–>9–>5–>9… At this time, if you go to get the element, an Infinite Loop will occur. .
This is the 1.8 tail insertion method. Due to the tail insertion method, the newly formed linked list and the old one are at least consistent in order, thus avoiding this situation.
Let's talk about some upgrades of jdk1.8. We all know that jdk1.8 is implemented in the way of array + linked list + red-black tree. What upgrades have been made specifically?
1.8 In addition to using the tail insertion method to solve the above problems, adding a red-black tree is mainly to solve the efficiency problem caused by hash conflicts that cause the linked list to be too long. The longer the linked list is, the slower the traversal will be. When the linked list reaches 8 , the linked list will be converted into a red-black tree, also called a balanced binary tree. Compared with the linked list, the query is very fast
The problem comes again. When the size of the linked list in the Hashmap exceeds eight, it will be automatically converted into a red-black tree. When the deletion is less than six, it will become a linked list again. Why?
According to the Poisson distribution, when the default load factor is 0.75, the probability that the number of elements in a single hash slot is 8 is less than one in a million, so 7 is used as a watershed. The conversion is only performed when it is less than or equal to 6, and it is converted into a linked list. After all, the structure of the entire lower part is to resolve hash collisions
Next, why is the default initialization length of HashMap 16? Nothing else?
As long as it is a power of 2, its practicality is about the same as 8 and 32. The reasons are as follows: (source: https://blog.csdn.net/zhucegemingzizheng/article/details/81289479)
虽然我们有链表红黑树等一系列解决方案,但是根本问题还是在于减少哈希冲突才能提高效率,
用2次幂次方作为初始值,目的是为了Hash算法均匀分布的原则尽量减少哈希冲突
We know the calculation formula of index: index = HashCode (Key) & (Length- 1)
1. Assuming that the HashMap length is the default 16, the result of calculating Length-1 is 15 in decimal and 1111 in binary.
3. Perform AND operation on the above two results, 101110001110101110 1001 & 1111 = 1001, the decimal is 9, so index=9.
It can be said that the final index result obtained by the Hash algorithm depends entirely on the last few digits of the Hashcode value of the Key.
Assuming that the length of HashMap is 10, repeat the operation steps just now:

Looking at this result alone, there is no problem on the surface. Let's try a new HashCode 101110001110101110 1011 again:

Let's try another HashCode 101110001110101110 1111:

Yes, although the penultimate and third digit of the HashCode has changed from 0 to 1, the result of the operation is always 1001. That is to say, when the HashMap length is 10, some index results are more likely to appear, while some index results will never appear (such as 0111)!
This causes more hash collisions, which obviously does not conform to the principle of uniform distribution of the Hash algorithm.
On the other hand, if the length is 16 or other powers of 2, the value of Length-1 is that all binary bits are all 1. In this case, the result of index is equivalent to the value of the last few bits of HashCode. As long as the input HashCode itself is evenly distributed, the result of the Hash algorithm is uniform.
After discussing these, we will talk about the thread safety of HashMap. First of all, is it thread safe?
It is not thread-safe. First of all, if multiple threads use the put method to add elements at the same time, and assuming that there are exactly two put keys colliding (with the same hash value), then according to the implementation of HashMap, these two keys will be added to the array The same location, so that the data put by one of the threads will eventually be overwritten. The second is that if multiple threads detect that the number of elements exceeds the array size * loadFactor at the same time, multiple threads will expand the Node array at the same time, recalculating the element position and copying data, but in the end only one thread expands The array will be assigned to the table, which means that other threads will be lost, and the data put by the respective threads will also be lost.
So what methods are used to solve the thread safety problem?
Three ways:
//Hashtable
Map<String, String> hashtable = new Hashtable<>();
//synchronizedMap
Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>());
//ConcurrentHashMap
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
1. The HashTable source code uses synchronized to ensure thread safety, such as the following get method and put method:
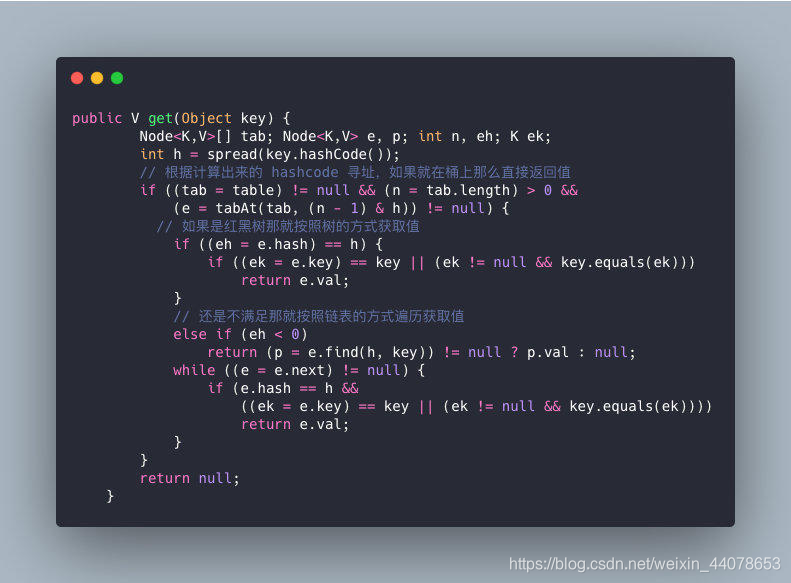
public synchronized V get(Object key) {
// 省略实现
}
public synchronized V put(K key, V value) {
// 省略实现
}
, when one thread uses the put method, the other thread not only cannot use the put method, but even the get method is not allowed, the efficiency is very low, and it is basically not selected now!
1.1 Can you tell some difference between Hashtable and HashMap?
Hashtable does not allow the key or value to be null, while the key value of HashMap can be null.
This is because Hashtable uses a fail-safe mechanism (fail-safe), which makes the data you read this time not necessarily the latest data.
If you use a null value, it will make it impossible to judge whether the corresponding key does not exist or is empty, because you cannot call contain(key) again to judge whether the key exists. ConcurrentHashMap is the same.
The implementation is different : Hashtable inherits the Dictionary class, while HashMap inherits the AbstractMap class.
The initial capacity is different : the initial capacity of HashMap is: 16, the initial capacity of Hashtable is: 11, and the default load factor of both is: 0.75.
Different iterators : The Iterator iterator in HashMap is fail-fast, while the Enumerator of Hashtable is not fail-fast.
Therefore, when other threads change the structure of HashMap, such as adding or deleting elements, ConcurrentModificationException will be thrown, but Hashtable will not.
Fail-fast (fast failure): Judging by checking whether modCount is consistent, because every operation on the collection will change the value of modCount (for details, see the article on ArrayList, the principle is the same)
2. SynchronizedMap
uses the synchronized synchronization keyword in the SynchronizedMap class to ensure that operations on Map are thread-safe.
// synchronizedMap方法
2 public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
3 return new SynchronizedMap<>(m);
4 }
5 // SynchronizedMap类
6 private static class SynchronizedMap<K,V>
7 implements Map<K,V>, Serializable {
8 private static final long serialVersionUID = 1978198479659022715L;
9
10 private final Map<K,V> m; // Backing Map
11 final Object mutex; // Object on which to synchronize
12
13 SynchronizedMap(Map<K,V> m) {
14 this.m = Objects.requireNonNull(m);
15 mutex = this;
16 }
17
18 SynchronizedMap(Map<K,V> m, Object mutex) {
19 this.m = m;
20 this.mutex = mutex;
21 }
22
23 public int size() {
24 synchronized (mutex) {
return m.size();}
25 }
26 public boolean isEmpty() {
27 synchronized (mutex) {
return m.isEmpty();}
28 }
29 public boolean containsKey(Object key) {
30 synchronized (mutex) {
return m.containsKey(key);}
31 }
32 public boolean containsValue(Object value) {
33 synchronized (mutex) {
return m.containsValue(value);}
34 }
35 public V get(Object key) {
36 synchronized (mutex) {
return m.get(key);}
37 }
38
39 public V put(K key, V value) {
40 synchronized (mutex) {
return m.put(key, value);}
41 }
42 public V remove(Object key) {
43 synchronized (mutex) {
return m.remove(key);}
44 }
45 // 省略其他方法
3.
For the specific implementation of ConcurrentHashMap, please refer to this blog for details: Address
See also the brief introduction below:
Compared with the former two, this method supports more concurrency. The bottom layer of ConcurrentHashMap is based on array + linked list, but the specific implementation is slightly different in jdk1.7 and 1.8. In 8, CHM abandoned the concept of Segment (lock segment), but enabled a new way to implement it, using the CAS algorithm.
3.1 first is like this in 1.7
It is composed of Segment array and HashEntry. Like HashMap, it is still an array plus a linked list.
Segment is an internal class of ConcurrentHashMap, the main components are as follows:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶
transient volatile HashEntry<K,V>[] table;
transient int count;
// 记得快速失败(fail—fast)么?
transient int modCount;
// 大小
transient int threshold;
// 负载因子
final float loadFactor;}
HashEntry is similar to HashMap, but the difference is that he uses volatile to modify his data Value and the next node next.
What are the characteristics of volatile?
- It ensures the visibility of different threads operating on this variable, that is, a thread modifies the value of a variable, and this new value is immediately visible to other threads. (for visibility)
- Instruction reordering is prohibited. (to achieve order)
- volatile can only guarantee atomicity for a single read/write. i++ does not guarantee atomicity for such operations.
The core of concurrentHashMap is the use of segment lock technology, in which Segment inherits from ReentrantLock.
Unlike HashTable, both put and get operations need to be synchronized. In theory, ConcurrentHashMap supports thread concurrency of CurrencyLevel (the number of Segment arrays).
Whenever a thread occupies a lock to access a segment, it will not affect other segments.
That is to say, if the capacity is 16, its concurrency is 16, allowing 16 threads to operate 16 segments at the same time, and it is thread-safe.
PUT logic:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException(); //这就是为啥他不可以put null值的原因
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
He first locates the Segment, and then performs the put operation.
Let's look at his put source code, and you will know how he achieves thread safety.
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
First, the first step will try to acquire the lock. If the acquisition fails, there must be competition among other threads, then use scanAndLockForPut() to spin to acquire the lock.
Attempt to spin to acquire a lock.
If the number of retries reaches MAX_SCAN_RETRIES, it will be changed to blocking lock acquisition to ensure success.
GET logic:
The get logic is relatively simple. You only need to locate the Key to a specific Segment through a Hash, and then locate a specific element through a Hash.
Since the value attribute in HashEntry is modified with the volatile keyword, memory visibility is guaranteed, so it is the latest value every time it is acquired.
The get method of ConcurrentHashMap is very efficient, because the whole process does not require locking
3.2 and 1.8 are like this
Among them, the original Segment segment lock is abandoned, and CAS + synchronized is used to ensure concurrency security
It is very similar to HashMap. It also changed the previous HashEntry to Node, but the function remains the same. The value and next are modified with volatile to ensure visibility, and a red-black tree is also introduced. When the linked list is greater than a certain value will be converted (default is 8).
Is it the access operation of its value? And how to ensure thread safety?
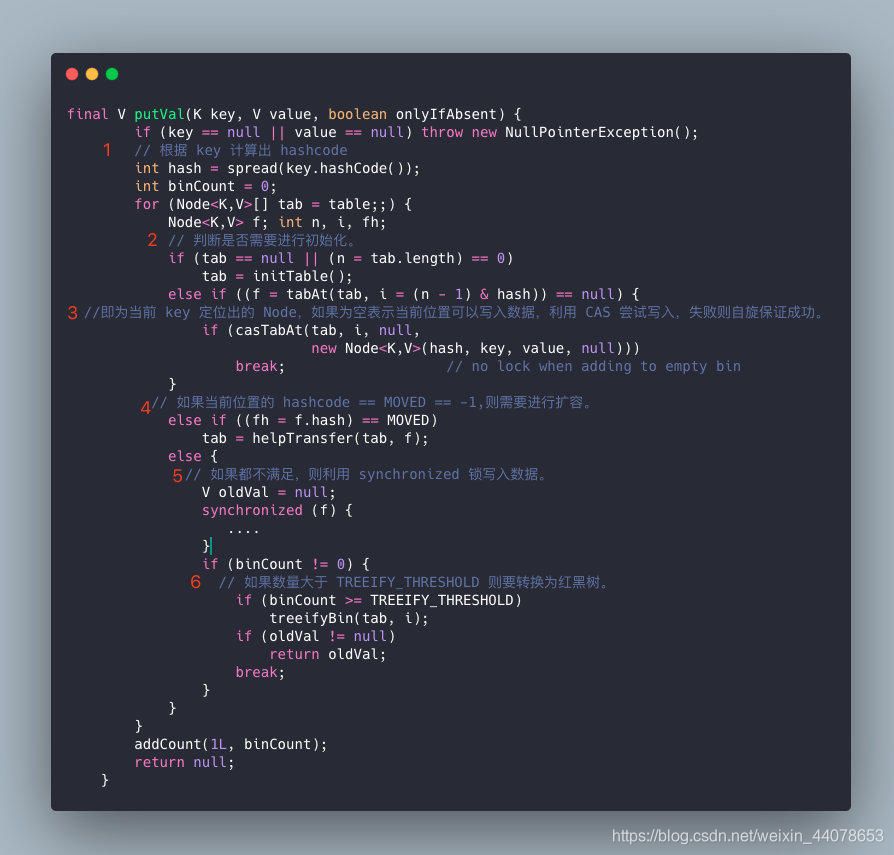
The put operation of ConcurrentHashMap is still relatively complicated, which can be roughly divided into the following steps:
- Calculate the hashcode based on the key.
- Determine whether initialization is required.
- It is the Node located by the current key. If it is empty, it means that the current location can write data. Use CAS to try to write. If it fails, the spin guarantees success.
- If the hashcode of the current location == MOVED == -1, it needs to be expanded.
- If not satisfied, use the synchronized lock to write data.
- If the number is greater than TREEIFY_THRESHOLD, it will be converted to a red-black tree.
Here is to learn what is the CAS of Ao Bing?
CAS is an implementation of optimistic locking, and it is a lightweight lock. The implementation of many tool classes in JUC is based on CAS.
The flow of the CAS operation is shown in the figure below. The thread does not lock the data when it reads the data. When preparing to write the data back, it compares whether the original value has been modified. If it has not been modified by other threads, it will be written back. Execute the read process.
This is an optimistic strategy in the belief that concurrent operations do not always occur.
The performance of CAS is very high, but I know that the performance of synchronized is not good. Why is there more synchronized after jdk1.8 upgrade?
Synchronized has always been a heavyweight lock before, but later java officials upgraded it, and now it uses the lock upgrade method to do it.
For the synchronized way of acquiring locks, JVM uses an optimization method of lock upgrade, which is to use a biased lock to give priority to the same thread and then acquire the lock again. If it fails, it will be upgraded to a CAS lightweight lock. If it fails, it will spin for a short time to prevent The thread is suspended by the system. Finally, if all of the above fail, upgrade to a heavyweight lock.
So it was upgraded step by step, and it was locked in many lightweight ways at first.
What about the get operation of ConcurrentHashMap?
- According to the calculated hashcode addressing, if it is on the bucket, then return the value directly
- If it is a red-black tree, then get the value according to the tree.
- If you are not satisfied, then traverse to obtain the value according to the linked list.