Article directory
foreword
Why do we need to understand the virtual DOM Diff algorithm?
Understanding its operating mechanism not only helps to better understand the life cycle of React components, but also helps to further optimize React programs.
1. Virtual DOM
Virtual DOM: virtual DOM, using ordinary js objects to describe the DOM structure, because it is not a real DOM, so it is called virtual DOM.
In Javascript objects, the virtual DOM is represented as an Object object. And it contains at least three attributes: tag name (tag), attribute (attrs) and child element object (children). Different frameworks may have different names for these three attributes.
1. Problems to be solved by virtual DOM
1. Before the emergence of react, vue and other technologies:
to change the content displayed on the page, you can only find the dom that needs to be modified by traversing the dom tree, and then modify the style behavior or structure to achieve the purpose of updating the ui
It consumes quite a lot of computing resources (almost every dom query needs to traverse the entire dom tree)
2. Use virtual DOM (js object): Every change of dom becomes a change of the property of js object, so that the property change of js object can be found, which is less performance overhead than querying dom tree.
Virtual DOM is designed to solve browser performance problems.
2. Front end - the process from receiving html to displaying it on the page
- Create a DOM tree (analyze HTML elements and build a DOM tree)
- Create StyleRules (analyze CSS files and inline styles on elements to generate style sheets for pages)
- Create a Render tree (associate the DOM tree with the style sheet)
- Layout Layout (the browser starts the layout, and determines a precise coordinate for each node on the Render tree to appear on the display screen)
5. Drawing Painting (call the paint method of each node to draw them)
3. What is DOM
Document Object Model (Document Object Model), is an API provided for HTML and XML;
According to DOM standards, both HTML and XML are tree structures constructed with tags as nodes. DOM abstracts the same structural essence of HTML and XML, and then accesses and operates according to the model standards in DOM through scripting languages such as Javascript document content.
Javascript can directly access and manipulate the content of webpage documents through DOM, and the interface connecting js and html structures is DOM.
4. Why the performance overhead of operating dom is high:
It's not that the performance overhead of querying the dom tree is high
reason:
- The implementation module of the dom tree is separate from the js module , and these cross-module communication increases the cost.
- The reflow and redrawing of the browser caused by the dom operation makes the performance overhead huge.
Remarks: There is no performance problem on the PC side (because the computing power of the PC is strong), but with the development of the mobile terminal, more and more web pages run on smartphones, and the performance of mobile phones is uneven, and there will be performance problems .
5. For comparison, why use virtual dom
for example:
In one operation, I need to update 10 DOM nodes . After the browser receives the first DOM request, it does not know that there are still 9 update operations, so it will execute the process immediately, and finally execute 10 times . After the first calculation, immediately after the next DOM update request, the coordinate value of this node will change, and the previous calculation is useless. Calculating the coordinate values of DOM nodes, etc. are all wasted performance.
The virtual DOM does not operate the DOM immediately, but saves the diff content of these 10 updates in a local JS object, and finally attaches the JS object to the DOM tree at one time, and then performs subsequent operations to avoid a lot of unnecessary calculations quantity .
6. The meaning of virtual dom
advantage:
- The real meaning of vdom is to achieve cross-platform, server-side rendering (thus the birth of react native, etc.);
- Provide a fairly good Dom update strategy;
shortcoming:
- Unable to perform extreme optimization: Although virtual DOM + reasonable optimization is sufficient to meet the performance requirements of most applications, in some applications with extremely high performance requirements, virtual DOM cannot be targeted for extreme optimization ;
- When rendering a large amount of DOM for the first time, it will be slower than innerHTML insertion due to the calculation of an additional layer of virtual DOM.
7. Implementation process of virtual DOM
The render function is called when the component is rendered.
- The render function first generates a virtual DOM based on the real DOM
- When the data of a node in the virtual DOM changes, a new Vnode is generated
- Comparing Vnode with oldVnode, if there is any difference, modify it directly on the real DOM, and then make the value of oldVnode Vnode
- The real dom is mounted to the page
2. Diff algorithm
1. What is DOM Diff algorithm
The web interface is composed of a DOM tree. When a part of it changes, it means that a corresponding DOM node has changed. In React, the idea of building a UI interface is to determine the interface by the current state. The two states before and after correspond to two sets of interfaces, and then React will compare the difference between the two interfaces, which requires Diff algorithm analysis on the DOM tree.
That is, given any two trees, find the fewest transformation steps. However, the complexity of the standard Diff algorithm needs to be O(n^3), which obviously cannot meet the performance requirements. In order to achieve the purpose of refreshing the interface as a whole every time the interface, it is necessary to optimize the algorithm. This seems very difficult, but Facebook engineers did it. They combined the characteristics of the web interface and made two simple assumptions, which directly reduced the complexity of the Diff algorithm to O(n).
- Two identical components produce similar DOM structures, and different components produce different DOM structures;
- For a group of child nodes at the same level, they can be distinguished by a unique id.
Algorithmic optimization is the basis of React’s entire interface Render, and the facts have proved that these two assumptions are reasonable and accurate, ensuring the performance of the overall interface construction.
2. Comparison of different node types
In order to compare between trees, we must first be able to compare two nodes. In React, we compare two virtual DOM nodes. When the two nodes are different, what should we do? This is divided into two cases:
(1) The node types are different,
(2) The node types are the same, but the attributes are different.
This section looks at the first case first.
When different types of nodes are output before and after the same position in the tree, React directly deletes the previous nodes, and then creates and inserts new nodes. Suppose we output different types of nodes at the same position in the tree twice.
renderA: <div />
renderB: <span />
=> [removeNode <div />], [insertNode <span />]
When a node changes from a div to a span, simply delete the div node directly and insert a new span node. This matches our understanding of real DOM manipulation.
It should be noted that deleting a node means completely destroying the node, rather than checking whether there is another node equal to the deleted node in subsequent comparisons. If there are child nodes under the deleted node, then these child nodes will also be completely deleted, and they will not be used for subsequent comparisons. This is why the complexity of the algorithm can be reduced to O(n).
When React encounters different components at the same location, it simply destroys the first component and adds the newly created one. This is the application of the first assumption. Different components generally produce different DOM structures. Instead of wasting time comparing DOM structures that are basically not equivalent, it is better to create a new component and add it.
From this React's processing logic for different types of nodes, we can easily infer that React's DOM Diff algorithm actually only compares the tree layer by layer , as described below.
3. Node comparison layer by layer
When it comes to trees, I believe that most students immediately think of complex data structure algorithms such as binary trees, traversal, and shortest paths. In React, the tree algorithm is actually very simple, that is, two trees will only compare nodes at the same level. As shown below:
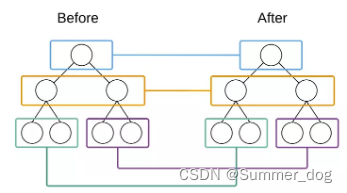
React will only compare DOM nodes within the same color box, that is, all child nodes under the same parent node. When it is found that the node no longer exists, the node and its child nodes will be completely deleted and will not be used for further comparisons. In this way, only one traversal of the tree is required to complete the comparison of the entire DOM tree.
For example, consider the following DOM structure transformation:
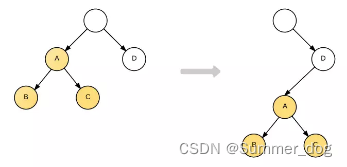
The A node is completely moved to the D node. Intuitively, the DOM Diff operation should be
A.parent.remove(A);
D.append(A);
But because React only simply considers the position transformation of the same-layer nodes, **For nodes of different layers, only simple creation and deletion. **When the root node finds that A is missing in the child node, it will directly destroy A; and when D finds that it has an additional child node A, it will create a new A as a child node. So the actual operation for the transformation of this structure is:
A.destroy();
A = new A();
A.append(new B());
A.append(new C());
D.append(A);
It can be seen that the tree with A as the root node is completely recreated.
Although it seems that such an algorithm is a bit "simple", it is based on the first assumption: two different components generally produce different DOM structures. According to the official React blog, this assumption has not resulted in serious performance issues so far. This of course also gives us a hint that maintaining a stable DOM structure will help improve performance when implementing our own components. For example, we can sometimes hide or show certain nodes via CSS without actually removing or adding DOM nodes.
4. Understand the life cycle of components by DOM Diff algorithm
In the previous article, I introduced the life cycle of React components, each of which is actually closely related to the DOM Diff algorithm. For example the following methods:
- constructor: constructor, executed when the component is created;
- componentDidMount: executed when the component is added to the DOM tree;
- componentWillUnmount: Executed when the component is removed from the DOM tree, in React it can be considered that the component is destroyed;
- componentDidUpdate: Executed when the component is updated.
The relationship between life cycle and DOM Diff algorithm. When the DOM tree transitions from "shape1" to "shape2". Let's observe the implementation of these methods:
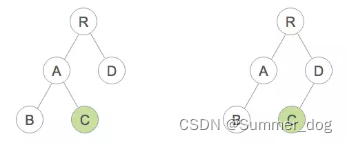
The browser development tool console outputs the following results:
C will unmount. C将被销毁
C is created. C被创建
B is updated. B被更新
A is updated. A被更新
C did mount. C被挂载
D is updated. D被更新
R is updated. R被更新
Note: Changes in the upper and lower layers and the same layer of the destroyed component.
It can be seen that the C node is completely rebuilt and added under the D node instead of "moving" it.
7. Comparison of nodes of the same type
The comparison of the second type of nodes is the same type of nodes, and the algorithm is relatively simple and easy to understand. React will reset the property to realize the conversion of the node. For example:
renderA: <div id="before" />
renderB: <div id="after" />
=> [replaceAttribute id "after"]
The style attribute of virtual DOM is slightly different, its value is not a simple string but must be an object, so the conversion process is as follows:
renderA: <div style={
{
color: 'red'}} />
renderB: <div style={
{
fontWeight: 'bold'}} />
=> [removeStyle color], [addStyle font-weight 'bold']
8. Comparison of list nodes
The above describes the comparison of nodes that are not in the same layer, even if they are exactly the same, they will be destroyed and recreated. So how are they handled when they are on the same layer? This involves the Diff algorithm of list nodes. I believe that many students who use React have encountered such warnings:

This is the warning that React prompts when it encounters a list but cannot find the key. While most interfaces will work correctly ignoring this warning, it usually indicates a potential performance problem. Because React feels that it may not be able to update this list efficiently.
Operations on list nodes typically include adding, removing, and sorting. For example, in the figure below, we need to directly insert node F into B and C. In jQuery, we may directly use $(B).after(F) to achieve. In React, we only tell React that the new interface should be ABFCDE, and the update interface is completed by the Diff algorithm.
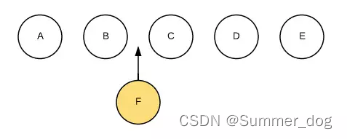
At this time, if each node does not have a unique identifier, React cannot identify each node, then the update process will be very inefficient, that is, update C to F, D to C, E to D, and finally insert an E node. Results as shown below:
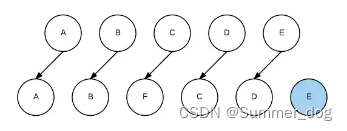
It can be seen that React will update the nodes one by one and switch to the target node. And finally inserting a new node E involves a lot of DOM operations. And if each node is given a unique identifier (key), then React can find the correct position to insert a new node, as shown in the following figure:
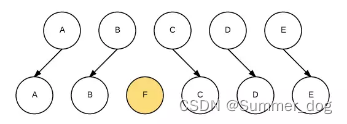
The adjustment of the order of list nodes is actually similar to insertion or deletion. Let's take a look at the conversion process with an example. Transform the shape of the tree from shape5 to shape6:
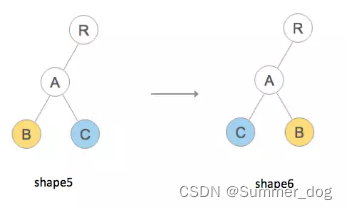
That is to adjust the position of nodes on the same layer. If the key is not provided, then React thinks that the component types of the corresponding positions after B and C are different, so it is completely deleted and rebuilt. The console output is as follows:
B will unmount.
C will unmount.
C is created.
B is created.
C did mount.
B did mount.
A is updated.
R is updated.
And if the key is provided, as in the following code:
shape5: function() {
return (
<Root>
<A>
<B key="B" />
<C key="C" />
</A>
</Root>
);
},
shape6: function() {
return (
<Root>
<A>
<C key="C" />
<B key="B" />
</A>
</Root>
);
},
Then the console output is as follows:
C is updated.
B is updated.
A is updated.
R is updated.
It can be seen that providing a unique key attribute for list nodes can help React locate the correct node for comparison, thereby greatly reducing the number of DOM operations and improving performance.