Author | zzbtie
guide
The cost pressure of large-scale iteration of business in the cloud-native environment is increasing. Guided by the concept of serverless, we build a multi-dimensional personalized service portrait from the perspective of elasticity, traffic, and capacity for the back-end service of Baidu Feed, and elastically scale the service based on the portrait, and adaptively adjust the service capacity with traffic fluctuations, effectively To reduce business operating costs, this article focuses on the above-mentioned related strategies and practical solutions.
The full text is 6542 words, and the expected reading time is 17 minutes.
01 background
With the promotion of cloud native in Baidu's internal product lines, microservices have become the standard configuration of each business line. In strategic computing business scenarios such as search, recommendation, and advertising, the backend is usually composed of many microservices. These microservices Services generally have the following characteristics:
-
Multiple instances : each service consists of multiple instances, microservices communicate through rpc, and services generally support horizontal/vertical scaling.
-
Heavy calculation : Microservices contain relatively complex business logic. Usually, some policy dictionaries are loaded locally in the service to perform complex policy calculations. The service itself requires more CPU and other resources.
-
7*24h : Services usually use fixed capacity to provide 7*24h online services, and cloud-native components perform regular capacity management, such as redundant capacity recovery.
Baidu App Recommendation Service (Baidu Feed for short) is a typical recommendation business scenario. The backend contains many microservices with complex strategies and heavy calculations. These backend services generally use fixed capacity to provide 7*24h information flow for hundreds of millions of users Recommended services. For the back-end service of Baidu Feed, there are typical peaks and valleys in user traffic, and there is no doubt that using the same capacity during the trough and peak periods of traffic is a waste of resources. This article introduces the practice of Baidu Feed's serverless in the back-end service , detailing the technical solution and implementation of elastic scaling based on service portraits.
02 Ideas and goals
The large-scale practice of serverless in the industry is more on the FaaS side. Usually, the instance is lighter and the life cycle of the container is relatively short. What we are dealing with is relatively "heavy" back-end services. The instance expansion of such services usually includes the following stages:
-
PaaS initializes the container : PaaS finds a suitable machine to allocate the container according to the quota requirements of the instance (cpu, memory, disk, etc.), and initializes the container.
-
Binary file and dictionary file preparation : download the binary file and dictionary file of the service from the remote to the local, and decompress them.
-
Instance startup : The instance starts the process locally according to the startup script, and registers the instance information to the service discovery.
The expansion time of the back-end service instance is usually at the minute level, and the download and decompression of dictionary files generally account for more than 70% of the overall expansion time. For instances with larger dictionaries, it takes more time. It cannot be scaled in a very short period of time (such as seconds) to ensure stable capacity. However, the traffic of these backend services usually fluctuates periodically and has obvious tidal characteristics. If we can make more accurate predictions on the traffic of the service, then we can properly expand the capacity in advance to ensure the capacity in the face of the increase in traffic. A certain amount of capacity reduction can be performed to reduce traffic flow to save resource costs and realize on-demand use of resources.
On the whole, based on cloud-native components, we create a multi-dimensional personalized service portrait for each service, including elasticity, capacity, and traffic dimensions, and realize service capacity fluctuating with traffic volume under the premise of ensuring service stability. adaptive adjustment. The implementation effect is shown in the figure below. In the left picture, the amount of resources consumed by a service in the normal mode is fixed and does not change with traffic fluctuations (the amount of resources must meet the capacity required by the peak traffic). In the right picture, the amount of resources consumed by the service in the Serverless mode The amount of resources is dynamically adjusted with traffic fluctuations.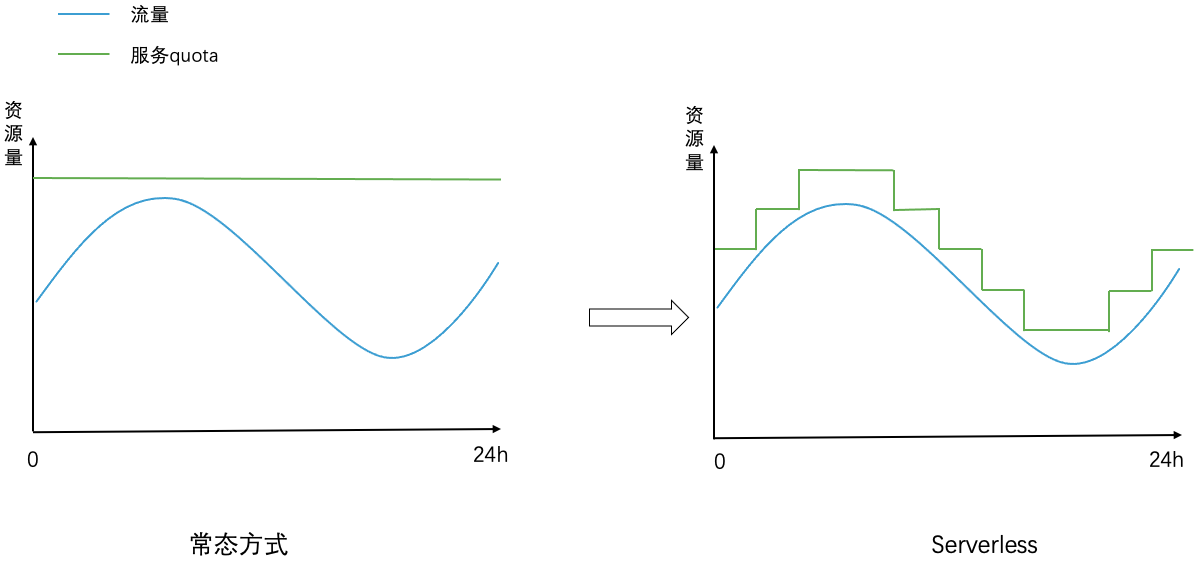
03 overall structure
The overall elastic scaling architecture is as follows:
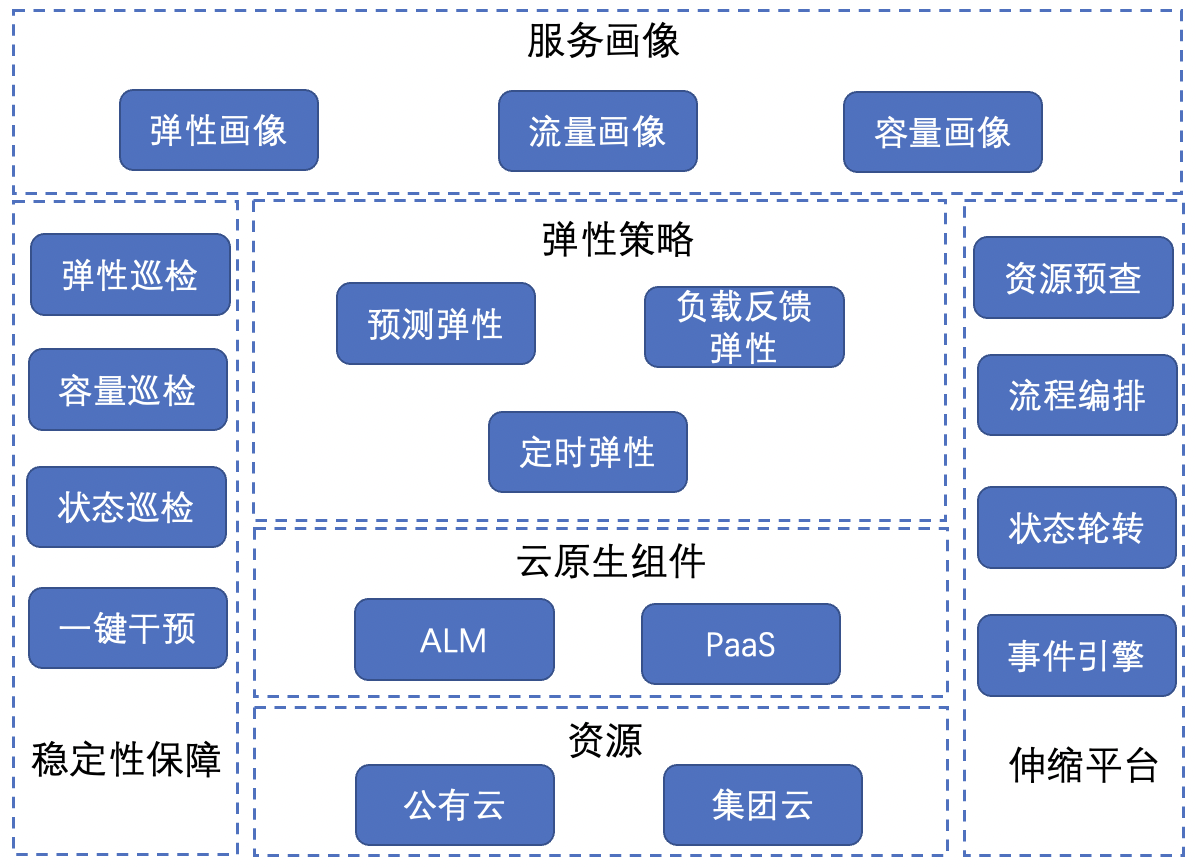
-
Service portrait : including elastic portrait, traffic portrait and capacity portrait, which portrays the personalized characteristics of services in multiple dimensions.
-
Elasticity strategy : Scaling strategies for different scenarios, including predictive elasticity, load feedback elasticity, and timing elasticity, are the basic core strategies for implementing Serverless.
-
Cloud-native components : including PaaS and ALM (app lifecycle manager), where PaaS is responsible for performing service scaling actions, and ALM is responsible for managing all data and policies related to services.
-
Resources : Including two types of elastic resources, group cloud and public cloud, Serverless supports service scaling related to two types of cloud resources.
-
Stability guarantee : various mechanisms to ensure the stability of elastic scaling, including elastic inspection, capacity inspection, status inspection, and one-click intervention.
-
Scalable platform : a support platform for implementing the overall strategy, including basic mechanisms such as resource pre-check, process orchestration, status rotation, and event engine.
Next, we will introduce the core strategies and practices, including service portraits, elastic strategies, and stability guarantees.
04 Service portrait
The backend of Baidu Feed contains many services. The dictionary files of each service have different sizes. Some services have more CPU calculations, while others have more IO. Each service has differences in scalability, traffic fluctuations, and load capacity. Therefore, around the online operation data of the service, we construct personalized elastic portraits, traffic portraits and capacity portraits from the dimensions of elasticity, traffic and load, and describe the personalized characteristics of each service in multiple dimensions.
4.1 Elastic portrait
Goal: Describe the scalability of the service from the perspective of scalability. Based on cloud-native indicators, service instance specifications, instance deployment and migration time, resource dependence and other dimensions to describe the elasticity of services, the services in the business are divided into the following three categories:
High elasticity : Completely stateless service, can be scaled at will without loss, and the scaling speed is fast.
Medium elasticity : It has certain scalability, but it takes a long time to restore the service state, and the scaling speed is average.
Low elasticity : There is almost no scalability, and a large cost is required to restore the service status, and the scaling speed is poor.
Elastic portrait construction :
For each service, obtain multiple recent instance expansion records from PaaS to obtain the instance expansion time, take the median as the instance deployment time of the service, combine the instance quota (cpu, memory, disk) of the service, whether there is a state, whether it exists External dependencies, using simple rules to classify all services into high, medium, and low elastic capabilities; at the same time, we promote services to undergo standardized container transformation and separation of storage and computing to improve service elasticity.
Increased resilience :
-
Standardized container transformation: Most of the service instances in the Baidu Feed business were non-standardized containers before, which had defects in port isolation and resource mixing, and could not support the separation of storage and computing, which affected the overall deployment and migration efficiency of services; by promoting service standardized container transformation, Each service supports cross-resource pool and cross-cloud scheduling and deployment, which can make full use of the fragmented resources of each resource pool, improve resource delivery efficiency and mixed deployment capabilities, and effectively improve the elastic scalability of services
-
Separation of storage and computing: For back-end services with large dictionary files, the time-consuming expansion of services is concentrated on downloading and decompressing dictionary files. We promote this type of service to connect to cloud disk shared volumes, and the dictionary content can be read remotely when service instances are deployed. Loaded into the memory, reducing the time-consuming download and decompression of dictionary files, significantly improving the service deployment and instance migration time, and effectively improving the elastic scalability of the service
4.2 Traffic Profile
Target:
Describe the traffic change trend of the service, predict the traffic at a certain time in the future, and then configure the corresponding capacity according to the traffic.
Traffic profile construction:
-
CPU usage: Although the traffic profile is based on historical traffic data to predict future traffic data, we do not directly collect qps data, but use cpu usage instead of qps. The main reason is that the backend service usually has multiple rpc/http interfaces, the number of interfaces of different services is different, and the qps and performance of different interfaces in a service are different, and the qps index of a single interface cannot reflect the overall resource consumption of the service. This leads to difficulties in establishing a mapping between the resource consumption of qps data and services using multiple interfaces. The main resource overhead of backend services is cpu, and the cpu usage of a service is a single general indicator for each service, which directly reflects the overall resource overhead of the service when processing multiple interface requests, so this indicator can be more accurate than qps Directly characterize the capacity requirements of the service.
-
Time slice: The traffic of backend services generally fluctuates periodically in 24 hours. We divide 24 hours a day into multiple time slices; for each service, we count its historical data (for example, in the past N days in each time slice corresponding traffic data) and predict the traffic situation of a certain time slice in the future based on historical data. For example, 24 hours are divided into 24 time slices, and each time slice corresponds to 1 hour. We want to predict the traffic situation of a certain service in the corresponding time slice from 2:00 pm to 3:00 pm, then according to the past 7 days (N=7 ) The service predicts traffic data from 2:00 to 3:00 p.m. Among them, the size of the time slice is configurable. The smaller the time slice configuration, the smaller the corresponding time range. For services with large traffic changes per unit time, a smaller time slice can be configured, and for services with small traffic fluctuations, a smaller time slice can be configured. Big time slice.
-
Monitoring collection: For each service, periodically collect the load data of all its instances (including cpu usage, etc.) and aggregate them into service data, and smooth the data in the corresponding time window (window size is configurable). For example, the cpu usage of an instance is collected every 10 seconds and aggregated into the cpu usage of the service, and the average value of the cpu usage of the service within a time window of 1 minute is used as the data corresponding to the time window. In the process of monitoring collection and data processing, the absolute median difference algorithm is used to eliminate all kinds of abnormal and outlier data points.
-
Portrait construction: For each service, calculate the cpu usage corresponding to each time window in each time slice in the past N days. For a time slice, use a sliding window to take the mean value of the largest K window data as the time slice cpu usage, so that the cpu usage data of each service in each time slice in the past N days can be obtained; at the same time, the traffic growth rate of two adjacent time slices is calculated, that is (next time slice traffic - current time slice traffic )/current time slice traffic. In the follow-up forecasting elasticity, the traffic of a certain time slice in the future will be predicted based on the time slice traffic and the traffic growth rate.
4.3 Capacity portrait
Target:
To characterize the capacity requirements of a service, it is generally replaced by the peak cpu utilization of the service. For example, if a service has a peak cpu utilization rate of 60% when it is stable, it means that at least 40% of the cpu buffer is reserved for the service to ensure its stability.
Capacity portrait construction:
-
Capacity and delay: Assuming that the service throughput and traffic are constant, the delay of the service is often inversely proportional to the remaining cpu buffer, that is, the less the remaining cpu buffer, the more the delay increases. In the Baidu Feed business line, even if the service on the non-core link has a small increase in delay, it will not have a direct impact on the system egress delay. Therefore, compared with the core link, the service on the non-core link can be reserved Less cpu buffer.
-
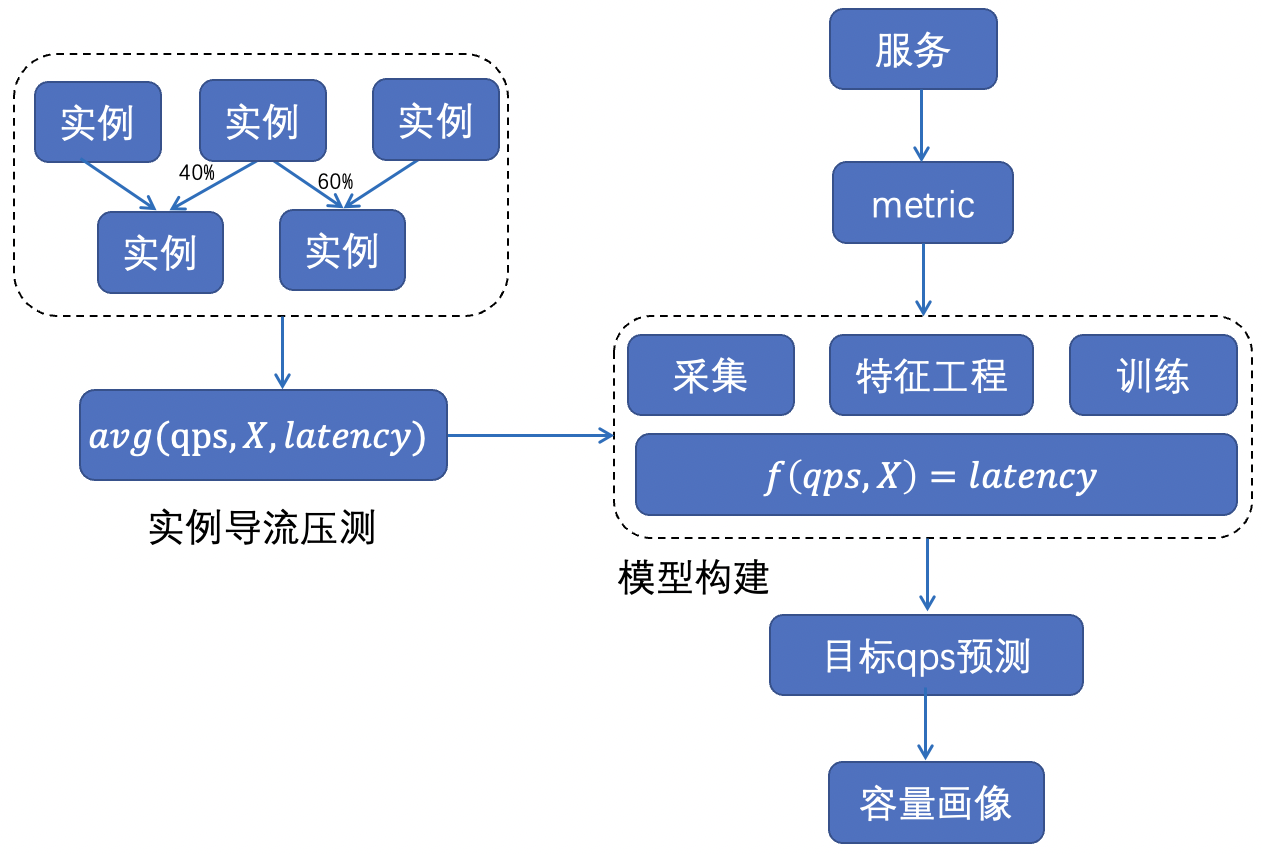
Overall method: The limit throughput of different services and the corresponding peak cpu utilization are different. On the whole, machine learning methods are used to construct performance curves for each service to describe the appropriate amount of cpu buffer for each service. The overall method is shown in the figure below.
-
Feature acquisition: Obtain delay data of services under different loads through instance monitoring and collection + instance diversion pressure measurement.
-
Model construction: Model the relationship between a series of container and machine monitoring indicators and service delays such as service qps, cpu utilization, and machine load: f(qps, X)=latency.
-
Profile calculation: Based on the delay model, evaluate the ultimate throughput and corresponding cpu utilization of each service within the acceptable range of delay (the delay of core services is not allowed to increase, and the delay of non-core services is allowed to increase by a certain threshold).
05 Flexible strategy
In order to cope with different business scaling scenarios, we construct the following three types of elastic policies to support business elastic scaling:
Predictive elasticity : For services with low elasticity, according to the traffic fluctuations in each time slice, predict the future traffic and plan and adjust the service capacity in advance.
Load feedback elasticity : For services with high elasticity, according to near-real-time service load changes, the service capacity is scaled in time to ensure service stability.
Timing flexibility : Some services change greatly during peak traffic periods, but change less during off-peak periods. During peak periods, maximum capacity needs to be provided to ensure stability. During off-peak periods, capacity does not need to be adjusted frequently. Timing flexibility comes during peak periods. Scale up before the peak period, scale down after the peak period, and maintain the same capacity during peak and off-peak periods.
5.1 Predictive Elasticity
Target:
According to the time slice configured by the service, the traffic of the future time slice is predicted within the current time slice, and the service is expanded in advance and delayed in capacity according to the predicted traffic to cope with different traffic changes.
Traffic Forecast:
-
For the current time, it is calculated by combining the previous time slice traffic, the current time slice traffic, and the next time slice traffic in the traffic profile, where the previous time slice traffic, the current time slice traffic, and the next time slice traffic are all corresponding to the past N days The maximum traffic of the time slice, recorded as prev, cur and next respectively.
-
According to the relationship between prev, cur, and next, the flow trend is divided into four cases as shown in the figure below.

-
case-1: prev < cur < next, the overall traffic is in an upward trend; currently, we should prepare for the traffic increase in the next time slice and expand capacity in advance
-
case-2: prev > cur < next, the overall traffic has reversed from a downward trend to an upward trend; at present, we should prepare for the traffic increase in the next time slice and carry out expansion in advance
-
case-3: prev < cur > next, the overall traffic has reversed from an upward trend to a downward trend, the current time slice is in the peak traffic state, and no action is taken
-
case-4: prev > cur > next, the overall traffic is in a downward trend, and the scaling action is performed
Expansion/shrinkage strategy:
-
For scenarios that require scaling (such as case-1, case-2, and case-4 above), calculate the target traffic, where target traffic = max (target traffic 1, target traffic 2).
-
The target capacity 1 is calculated based on the traffic of the above four types of cases:
-
For case-1 and case-2, target traffic 1 is equal to next (equivalent to expansion in advance).
-
For case-4, the target traffic 1 is equal to cur (this is not to scale down according to the traffic of the next time slice, otherwise the capacity may not be able to support the current time slice, here only scale down according to the current time slice traffic, which is equivalent to delay shrinking ).
-
Target traffic 2 = current traffic * (the maximum growth rate between the current time slice and the next time slice in the past N days), where the current traffic collects the cpu usage corresponding to the latest K time windows.
-
Calculate the target capacity based on the target traffic and the capacity profile of the service (that is, how much cpu buffer the service needs to reserve), calculate the target number of instances of the service based on the target capacity, and link PaaS to scale the service horizontally.
5.2 Load Feedback Elasticity
Target:
According to the near-real-time load conditions of the service, the service capacity is adjusted in time to cope with sudden changes in traffic.
Expansion/shrinkage strategy:
-
data collection:
-
General monitoring: collect near-real-time general load of services, such as cpu usage, cpu usage, etc.
-
Custom monitoring: Support custom business monitoring indicators in Prometheus metric mode, such as service delay indicators, throughput indicators, etc.
-
The collection period is configurable, and the sliding window method is usually used to aggregate and judge the monitoring indicators.
-
Expansion/shrinkage decision: According to the general load data and custom load data of the service, combined with the capacity portrait of the service, calculate the target number of instances required by the service and perform horizontal expansion and contraction operations.
5.3 Timing flexibility
Target:
The traffic of some services fluctuates less during off-peak periods. Frequent capacity adjustments are not necessary, and fixed but different capacities are expected during peak and off-peak periods.
Expansion/shrinkage strategy:
-
Calculate the maximum flow of the corresponding time slice during the peak period and non-peak period in the traffic profile.
-
Calculate the target capacity corresponding to the peak and off-peak periods of the service based on the maximum traffic and capacity profile.
-
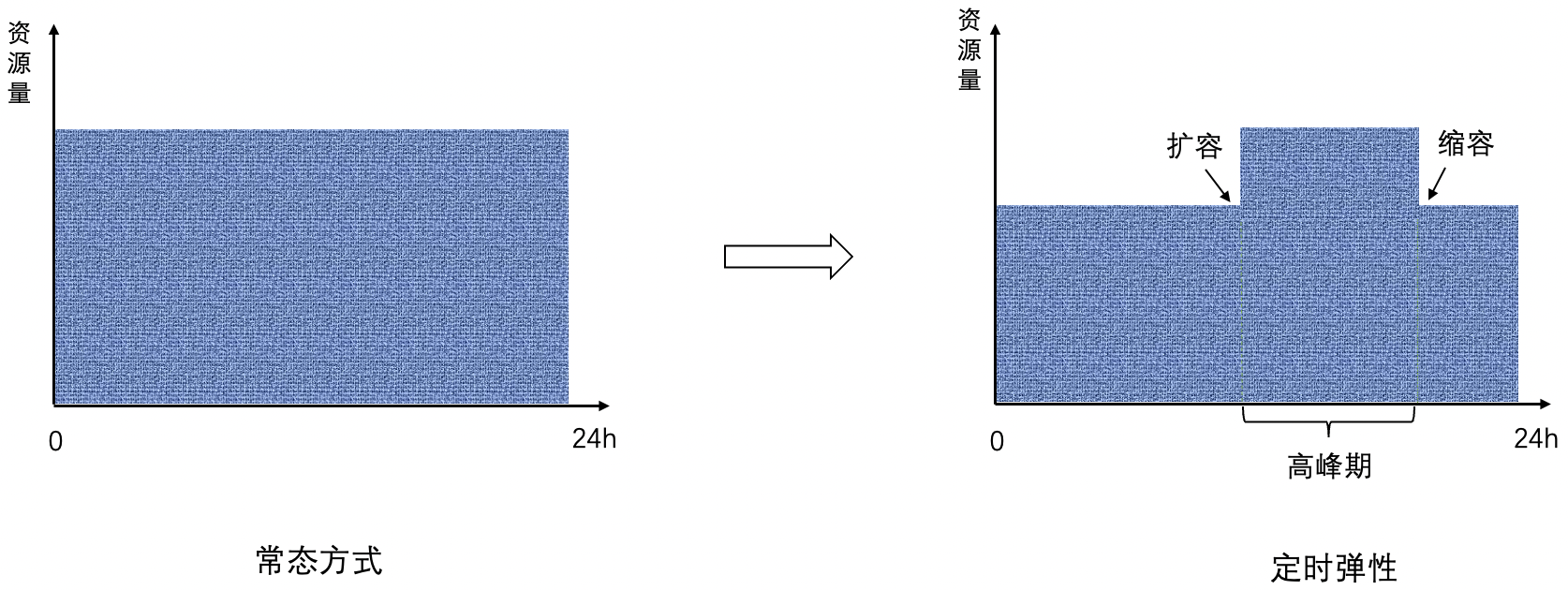
According to the target capacity, the expansion action (horizontal expansion) is triggered regularly before the peak period, and the scaling action (horizontal scaling) is triggered regularly after the peak period. The overall effect is shown in the figure below.
5.4 Resilience Practices
-
The above three types of elastic policies can be used independently according to the configuration, or can be used in combination as needed:
-
For functional computing with high elasticity, load feedback elasticity can be used to achieve the FaaS effect. For back-end recomputing services with low elasticity, three types of elasticity can be used in combination;
-
When the three types of strategies are used in combination, since they all adjust the number of service instances and take effect at the same time, there is a priority among the three types of strategies, timing elasticity > prediction elasticity > load feedback elasticity;
-
When load feedback elasticity is used in combination with predictive elasticity or timing elasticity, load feedback elasticity can only perform expansion actions and cannot shrink capacity, and capacity scaling is performed by predictive elasticity or timing elasticity. Because when the cpu load of a service is relatively low, it may be caused by the expansion of the predicted elasticity to prepare for the traffic of the next time slice in advance. At this time, the capacity cannot be scaled down according to the load feedback elasticity, and the same is true for the timing elasticity.
-
Retry mechanism:
-
The execution frequency of predictive elasticity and timing elasticity is low, involving some policy calculations and calling PaaS to modify the number of service instances. The overall operation is not atomic, and a retry mechanism is required;
-
Load feedback is elastically executed at high frequency, and can be retried on demand according to service requirements.
-
Target capacity verification: Each of the above elastic policies needs to be verified to modify the number of service target instances.
-
Limit the number of target instances within a reasonable range: compare the target number of instances with the upper and lower limits of instances configured in each service capacity profile, and if it exceeds, it will smooth to the upper and lower limit thresholds;
-
Limit the step size of a single expansion and contraction: compare the target number of instances with the current number of instances, limit the ratio of each expansion and contraction, prevent too much single expansion from causing insufficient resources, and prevent too much shrinkage from causing single-instance traffic to soar A memory oom appears.
06 Stability Guarantee
How to ensure service stability while frequently and dynamically adjusting service capacity on a large scale is very important. We build corresponding stability capabilities from the perspective of inspection and intervention stop loss, prevent problems before they happen through inspection, and quickly stop them through one-click intervention damage.
Elasticity inspection : Periodically trigger service instance migration, test the elasticity of the service, and expose scaling failures caused by dictionary file dependency exceptions in advance.
Capacity inspection : Configure alarm policies for various services, periodically inspect the resource capacity of each service, and trigger an alarm or one-click plan when the capacity is insufficient.
Status inspection : Check whether the status of each service rotates normally to prevent abnormal service status. For example, peak and off-peak periods correspond to different service capacity states.
One-click intervention : Provide quick stop loss capability, regular online drills to prevent capacity degradation, including one-click exit from the serverless plan, one-click open/close instance soft and hard limit plan, etc.
07 Summary
The overall work is carried out around Serverless. The personalized characteristics of each service are described through service portraits of elasticity, traffic, and capacity. Based on the portraits, multiple types of elastic policies are constructed to meet various service expansion scenarios and effectively realize the on-demand use of service resources. At present, Serverless has landed on the Baidu Feed business line with a scale of 100,000 service instances, effectively reducing business operating costs.
Next, Serverless will focus on two directions: capacity guarantee for hot events and application of machine learning to improve the accuracy of traffic profile prediction, and continuous access to larger-scale services to create value for the business!
——END——
Recommended reading:
Action decomposition method in image animation application
Performance Platform Data Acceleration Road
Editing AIGC Video Production Process Arrangement Practice
Baidu engineers talk about video understanding
Baidu engineers take you to understand Module Federation
Clever use of Golang generics to simplify code writing