Author: JD Retail Liu Huiqing
I. Introduction
The high availability of software is a common topic. "High Availability" (High Availability) usually describes a system that has been specially designed to reduce downtime while maintaining high availability of its services. The calculation formula is: availability rate = ( total time - unavailable time ) / total time.
This article focuses on the perspective of implementation practice as an entry point, and leads everyone to show the implementation steps and implementation details of high availability from the aspects of collaboration efficiency, technology implementation, and operation specifications. In order to facilitate understanding, let’s unify the language and vocabulary first, and look at the various stages in the software delivery process, as shown in the following figure:
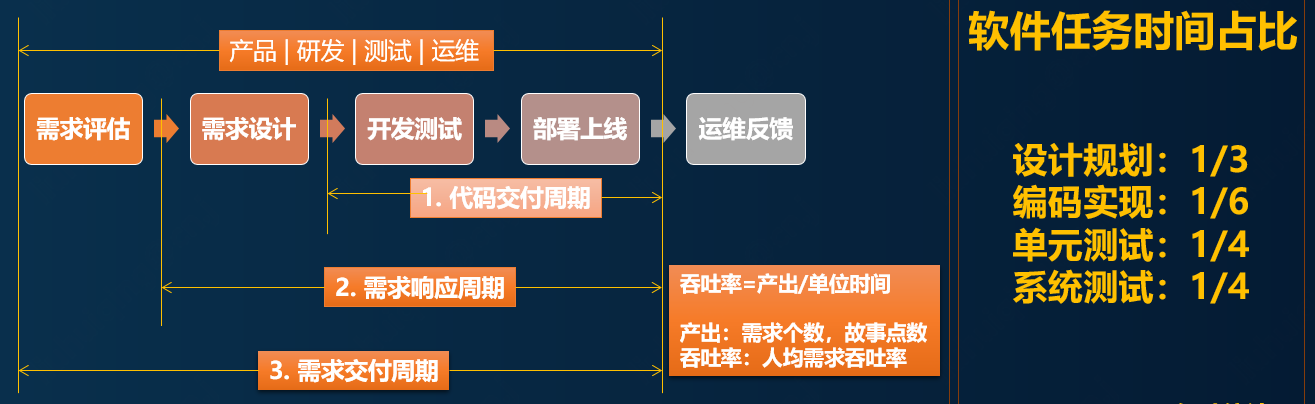
Why do you say that high availability of software faces many challenges?
To sum up, the specific problems we face are as follows:
2. Collaboration Efficiency Guarantee
Cognitive misunderstanding
From the entire demand delivery link, we can find that as the link increases step by step, the more branches of the information transmission link will be, and the deeper the transmission level will be. This causes two problems:
The final result of these two problems is the reduction of collaboration efficiency.
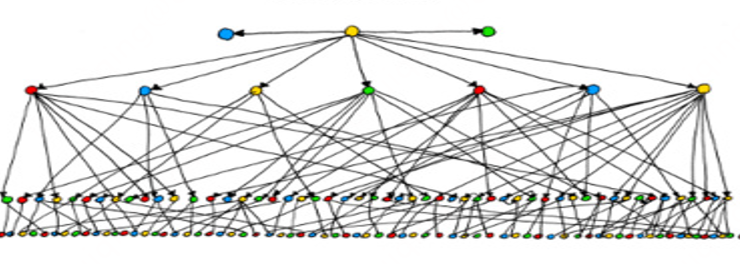
A student with no practical experience will often think that increasing the number of people will improve the efficiency of demand delivery. In fact, this idea is not entirely correct. For the specific relationship, refer to the following figure:
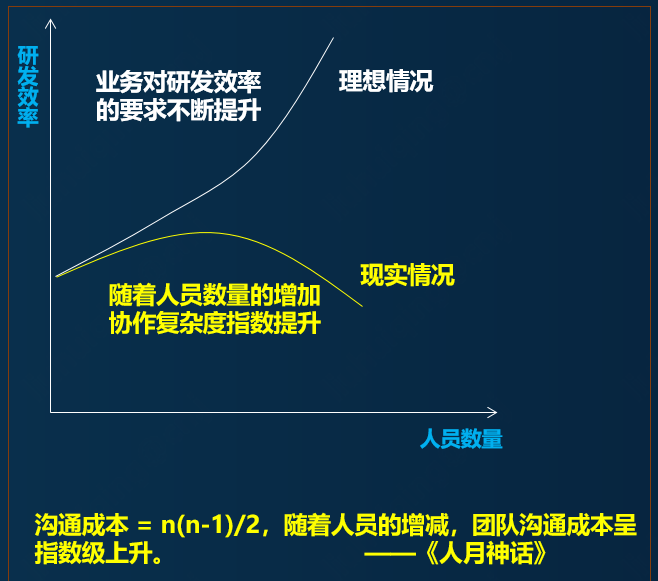
It's like building a building. If one person builds it step by step, it will take 100 days to complete. If 100 people are invited to help, can the house be built in 1 day? the answer is negative.
There are collaboration costs, such as: team understanding (designers, bricklayers, masons, plumbers), job matching, risk control;
There are process dependencies, for example: construction depends on design, and soft decoration always comes after hard decoration;
There are cost budgets, such as: talent gradient and scale of the entire organization (contractors, agents, contractors);
All of the above are not simply solved by laying manpower.
Process specification
The underlying logic of improving collaboration efficiency is to reduce the delivery link level and shorten the information transmission link, thereby ensuring the accuracy and transmission efficiency of information. (The content of the organizational construction level will not be expanded here)
This requires the ability to do today's work and complete today's work. At the organizational level, this is called process specification, and at the personal level, it is called work methods and sense of responsibility.
Try to avoid delaying the current matter to the next link, otherwise it will affect the scheduling and delivery efficiency of subsequent links, and even rework may occur in extreme cases. In short, think clearly and don't bury the hole. Product requirements are for R&D, R&D design is for testing, and test cases are for each delivery node such as products. The deliverables must be reliable.
Three technologies landing guarantee
In the demand response cycle, the high-quality implementation of architecture design, coding implementation, safe launch, deployment and operation and other production stages is the premise and basis for the implementation of high-availability software.
architecture design
Architecture design often affects the early implementation cost (ROI) of the system and the difficulty of subsequent operation and maintenance. It belongs to the top-level design of the software, which includes both the macro design scheme and the paradigm constraints in the implementation details.
Invite architects to participate: Invite architects to participate in core transaction nodes and major demand changes, which is the most direct and effective way to close the pit;
Emphasis on design documents: A clear description of the scheme and the approval of relevant stakeholders are the prerequisites for walking on the right path.
Disaster recovery design: It is necessary to reserve a way out, think clearly in advance, and do a good job in disaster recovery design. Rollback, fuse, retry, and downgrade possible.
Robust design: stateless design, anti-heavy design, idempotent design, data consistency design
Encoding implementation
If the architectural design is the skeleton, then the coding implementation is the nerves, blood vessels and muscles. The former determines how stable and how long you can walk, while the latter determines how fast and how far you can go. Implemented at the coding level, it is the degree of aging and corruption of the code.
Code review mechanism: Code review is not just as simple as finding problems in the system. It is a long-term behavior and a form and carrier for the implementation and inheritance of organizational culture. During the review process, the boundaries of business responsibilities, design and coding consensus, and excellent standard-oriented research and development consensus were clarified. It is equivalent to giving specific guidance through concrete cases, which are the cornerstones of ensuring the combat effectiveness of the team.
Many problems in the R&D process can be discovered and resolved through the code review mechanism, such as:
safe online
70% of online faults are triggered by some kind of change, and a considerable proportion of them are caused by irregular online. So going online safely is very important.
deployment operation
A very important means to achieve high availability is capacity redundancy. The direction and ideas are given below, as well as the specific implementation details and strategies, which can be extended according to specific situations.
Four operation standard guarantee
Operating Specifications
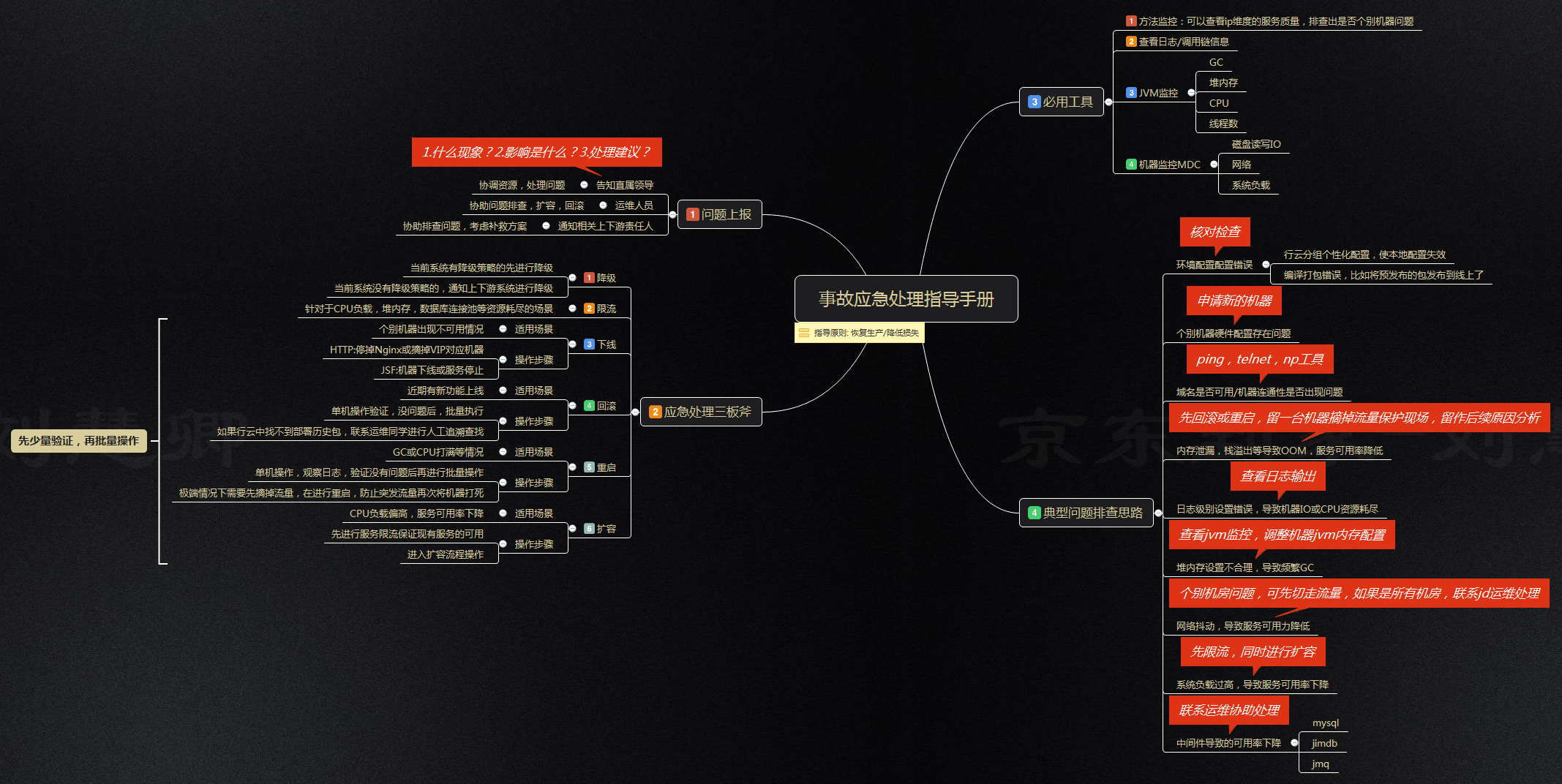
emergency plan
High availability means poor tolerance for downtime, means no time for troubleshooting and repair, and no time to open code for vulnerability troubleshooting. This requires us to have a complete set of emergency plans, which can solve most of the foreseeable failure problems.
For the detailed accident emergency handling manual, please refer to the following figure:
Standard compliance
No matter how good the process and norms are, there must be a corresponding mechanism to implement them. Otherwise, it will be a flower in the mirror, a moon in the water, which looks beautiful but is actually useless. Executable and measurable are the prerequisites for getting better according to the goals. So here is a tool called "High Availability and Compliance Periodic Self-inspection Table" to assist in the implementation of the specification.

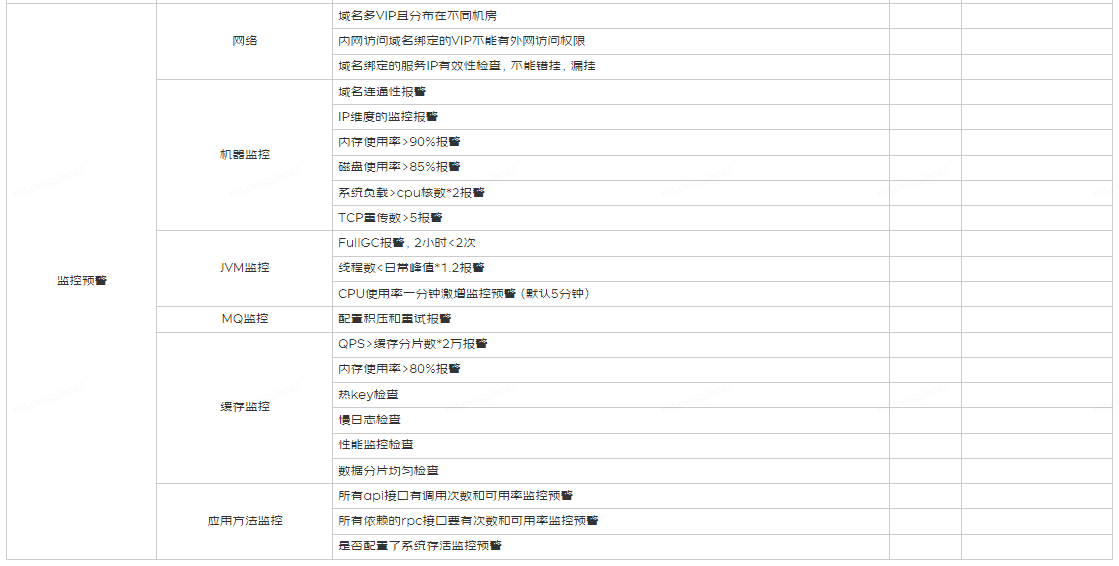
Five Summary
This article discusses the question "Why is there a great challenge in high availability?", emphasizes the importance of collaboration efficiency in the process of demand delivery, and points out why it is necessary to follow the working principle of "Today's work, today's work". From the aspects of architecture design, coding implementation, safe launch, deployment and operation, etc., it introduces in detail the guidelines and implementation details related to technology implementation guarantee. Finally, from the perspective of post-launch operation, it gives practical operation guarantee tools such as emergency plan, regular self-check table and so on. Hope it can help readers.