Transformer models are the foundation of AI systems. There are already countless diagrams of the core structure of "how Transformer works".
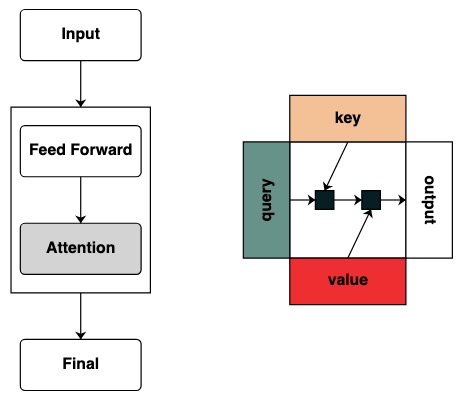
But these diagrams do not provide any intuitive representation of the framework for computing this model. When a researcher is interested in how a Transformer works, it becomes very useful to have an intuition about how it works.
In the paper Thinking Like Transformers , a computing framework of the transformer class is proposed, which directly calculates and imitates Transformer calculations. Using the RASP programming language, each program is compiled into a special Transformer.
In this blog post, I reproduced a variant of RASP (RASPy) in Python. The language is roughly the same as the original, but with a few more changes that I think are interesting. With these languages, author Gail Weiss' work offers a challenging set of interesting and correct ways to help understand how they work.
!pip install git+https://github.com/srush/RASPy
Before we talk about the language itself, let's look at an example of what coding with Transformers looks like. Here's some code that calculates a flip, i.e. reverses the input sequence. The code itself uses two Transformer layers to apply attention and mathematical calculations to arrive at this result.
def flip():
length = (key(1) == query(1)).value(1)
flip = (key(length - indices - 1) == query(indices)).value(tokens)
return flip
flip()
Article Directory
- Part 1: Transformers as code
- Part II: Writing Programs with Transformers
Transformers as code
Our goal is to define a set of computational forms that minimize the representation of Transformers. We will describe each language construct and its counterpart in Transformers by analogy. (For the official language specification, please see the link to the full text of the paper at the bottom of this article).
The core unit of the language is the sequence operation that transforms one sequence into another sequence of the same length. I'll call them transforms later on.
enter
In a Transformer, the base layer is a feed-forward input to a model. This input usually contains raw token and location information.
In the code, the features of tokens represent the simplest transform, which returns the tokens after the model, and the default input sequence is "hello":
tokens

If we want to change the input in the transform, we use the input method to pass the value.
tokens.input([5, 2, 4, 5, 2, 2])

As Transformers, we cannot directly accept the positions of these sequences. But to simulate location embeddings, we can get the index of the location:
indices

sop = indices
sop.input("goodbye")

feedforward network
After passing through the input layer, we reach the feedforward network layer. In Transformer, this step applies mathematical operations independently to each element of the sequence.
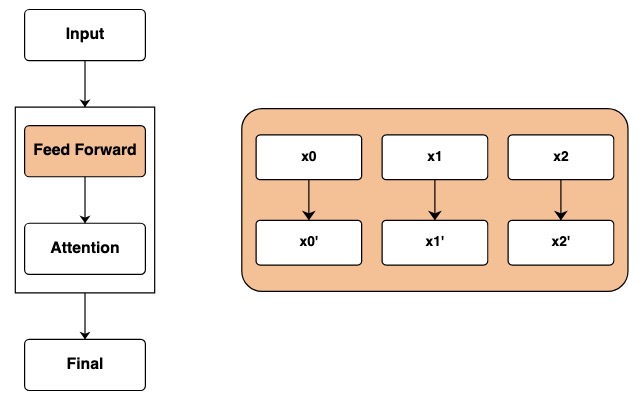
In the code, we represent this step by computing on transforms. Independent mathematical operations are performed on each element of the sequence.
tokens == "l"

The result is a new transform that is computed as refactored once the new input is reconstructed:
model = tokens * 2 - 1
model.input([1, 2, 3, 5, 2])

This operation can combine multiple Transforms. For example, take the above-mentioned token and indices as an example, here you can class Transformer to track multiple pieces of information:
model = tokens - 5 + indices
model.input([1, 2, 3, 5, 2])

(tokens == "l") | (indices == 1)

We provide some helper functions to make writing transforms easier, for example, whereto provide a structure with similar iffunctionality .
where((tokens == "h") | (tokens == "l"), tokens, "q")

mapAllows us to define our own operations, such as intconverting . (Users should be careful with operations computed by simple neural networks that can be used)
atoi = tokens.map(lambda x: ord(x) - ord('0'))
atoi.input("31234")

Functions (functions) can easily describe the cascade of these transforms. For example, the following is the operation where and atoi are applied and 2 is added
def atoi(seq=tokens):
return seq.map(lambda x: ord(x) - ord('0'))
op = (atoi(where(tokens == "-", "0", tokens)) + 2)
op.input("02-13")

attention filter
Things start to get interesting when you start applying the attention mechanism. This will allow the exchange of information between the different elements of the sequence.
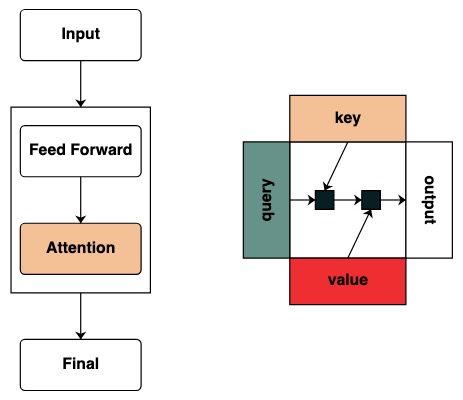
We start to define the concept of key and query, Keys and Queries can be created directly from the above transforms. For example, if we want to define a key we call it key.
key(tokens)

querysame for
query(tokens)

Scalars can keybe queryused as or , and they broadcast to the length of the underlying sequence.
query(1)

We create filters to apply operations between key and query. This corresponds to a binary matrix indicating which key each query is concerned with. Unlike Transformers, no weights are added to this attention matrix.
eq = (key(tokens) == query(tokens))
eq
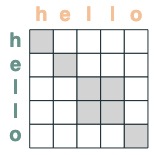
Some examples:
- The match position of the selector is offset by 1:
offset = (key(indices) == query(indices - 1))
offset
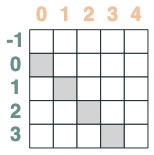
- A selector whose key is earlier than query:
before = key(indices) < query(indices)
before
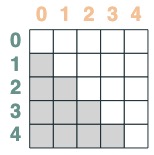
- A selector whose key is later than query:
after = key(indices) > query(indices)
after
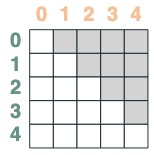
Selectors can be combined via boolean operations. For example, this selector combines before and eq, and we show this by including a key and value pair in the matrix.
before & eq
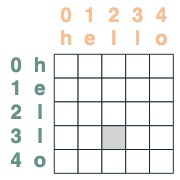
use attention mechanism
Given an attention selector, we can provide a sequence of values for aggregation. We aggregate by accumulating the truth values selected by those selectors.
(Note: In the original paper, they use an average aggregation operation and show a clever structure in which the average aggregation can represent the sum calculation. RASPy uses accumulation by default to keep it simple and avoid fragmentation. In fact, This means that raspy may underestimate the number of layers needed. Average based models may need twice this number of layers)
Note that aggregation operations allow us to compute features like histograms.
(key(tokens) == query(tokens)).value(1)
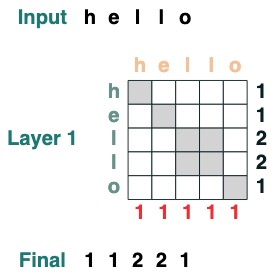
Visually we follow the graph structure with Query on the left, Key on top, Value on the bottom, and output on the right
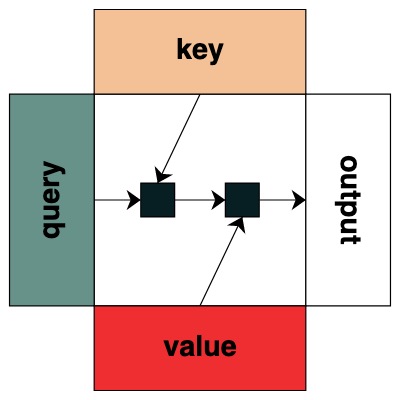
Some attention mechanism operations don't even require an input token. For example, to calculate the sequence length, we create a "select all" attention filter and assign it a value.
length = (key(1) == query(1)).value(1)
length = length.name("length")
length
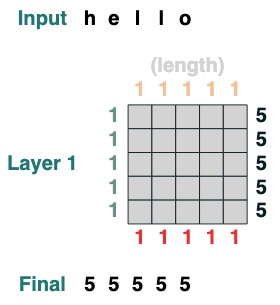
Here are more complex examples, shown step by step below. (It's kind of like doing an interview)
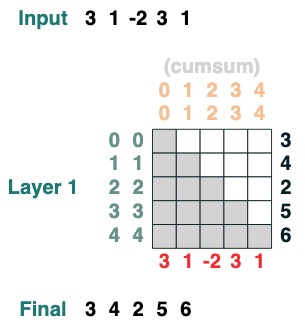
We want to compute the sum of adjacent values of a sequence, first we truncate forward:
WINDOW=3
s1 = (key(indices) >= query(indices - WINDOW + 1))
s1
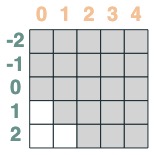
Then we truncate backwards:
s2 = (key(indices) <= query(indices))
s2
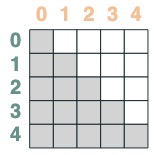
Both intersect:
sel = s1 & s2
sel
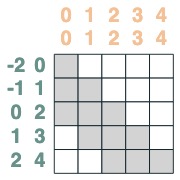
Final aggregation:
sum2 = sel.value(tokens)
sum2.input([1,3,2,2,2])
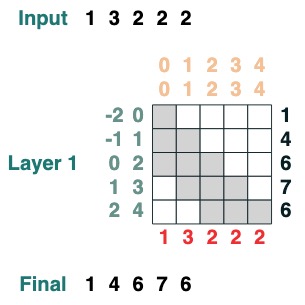
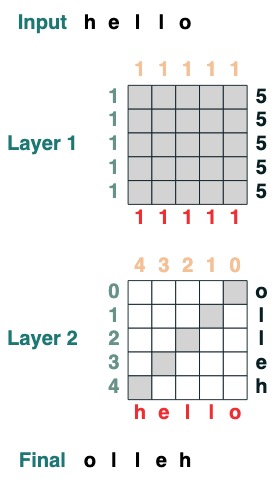
Here is an example that can calculate the cumulative sum. Here we introduce the ability to name the transform to help you debug.
def cumsum(seq=tokens):
x = (before | (key(indices) == query(indices))).value(seq)
return x.name("cumsum")
cumsum().input([3, 1, -2, 3, 1])
layer
The language supports compiling more complex transforms. It also computes layers by keeping track of each operation.
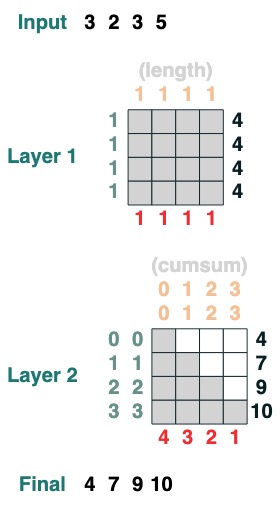
Here is an example of a 2-layer transform, the first corresponding to computing the length and the second corresponding to the cumulative sum.
x = cumsum(length - indices)
x.input([3, 2, 3, 5])
Programming with transformers
Using this function library, we can write a complex task. Gail Weiss gave me an extremely challenging question to break down this step: Can we load a Transformer that adds numbers of any length?
For example: Given a string "19492+23919", can we load the correct output?
If you want to try it yourself, we provide a version you can try yourself.
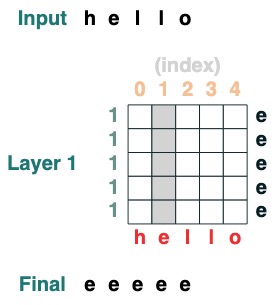
Challenge 1: Choose a given index
loads a sequence with all elements iat
def index(i, seq=tokens):
x = (key(indices) == query(i)).value(seq)
return x.name("index")
index(1)
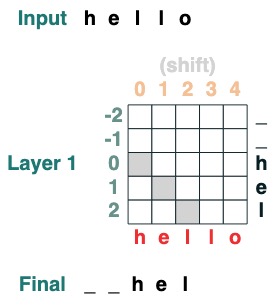
Challenge Two: Conversion
Move all tokens to the right by iposition .
def shift(i=1, default="_", seq=tokens):
x = (key(indices) == query(indices-i)).value(seq, default)
return x.name("shift")
shift(2)
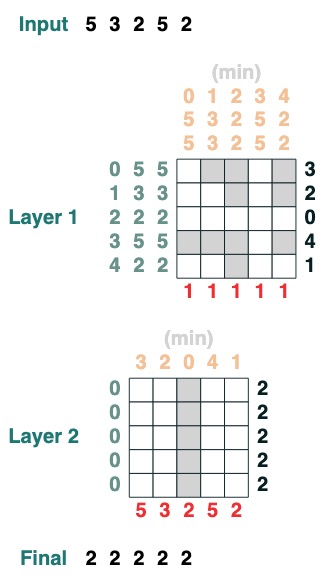
Challenge Three: Minimize
Computes the minimum value of a sequence. (This step becomes difficult, our version uses a 2-layer attention mechanism)
def minimum(seq=tokens):
sel1 = before & (key(seq) == query(seq))
sel2 = key(seq) < query(seq)
less = (sel1 | sel2).value(1)
x = (key(less) == query(0)).value(seq)
return x.name("min")
minimum()([5,3,2,5,2])
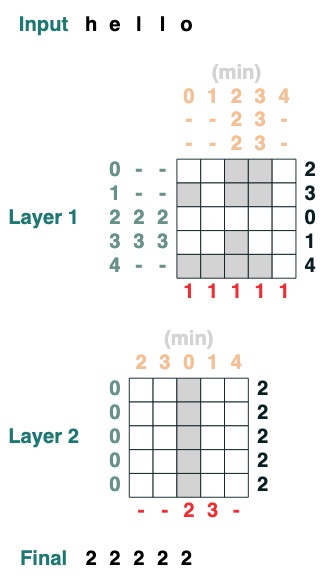
Challenge Four: First Index
Calculate the first index with token q (2 layers)
def first(q, seq=tokens):
return minimum(where(seq == q, indices, 99))
first("l")
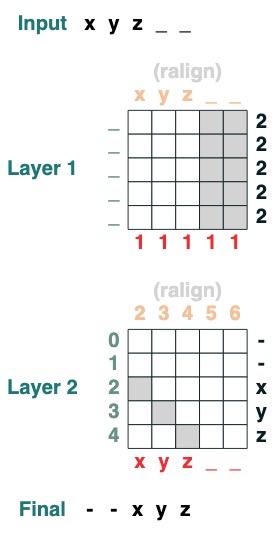
Challenge Five: Right Alignment
Right aligns a padding sequence. Example: " ralign().inputs('xyz___') ='—xyz'" (2 layers)
def ralign(default="-", sop=tokens):
c = (key(sop) == query("_")).value(1)
x = (key(indices + c) == query(indices)).value(sop, default)
return x.name("ralign")
ralign()("xyz__")
Challenge Six: Separation
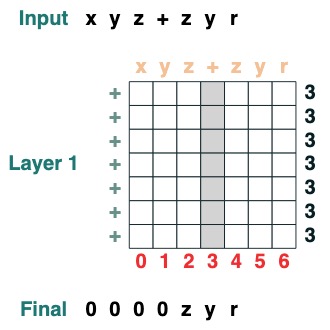
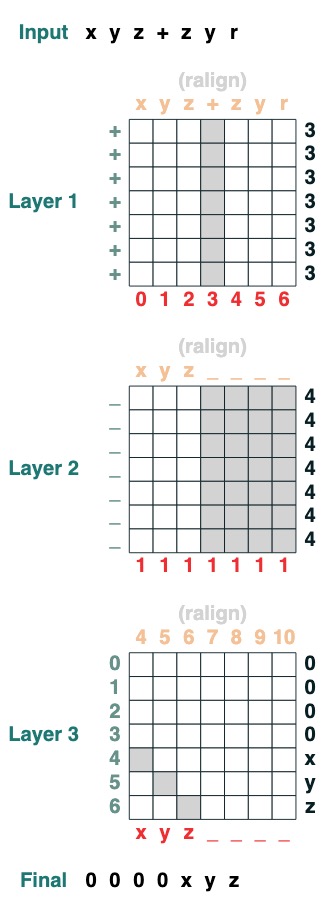
Split a sequence into two parts at token "v" and right-align (2 levels):
def split(v, i, sop=tokens):
mid = (key(sop) == query(v)).value(indices)
if i == 0:
x = ralign("0", where(indices < mid, sop, "_"))
return x
else:
x = where(indices > mid, sop, "0")
return x
split("+", 1)("xyz+zyr")
split("+", 0)("xyz+zyr")
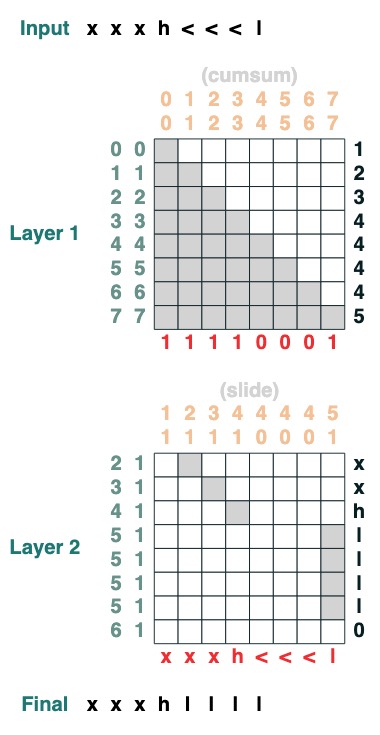
Challenge Seven: Swipe
Replace the special token "<" with the closest "<" value (2 layers):
def slide(match, seq=tokens):
x = cumsum(match)
y = ((key(x) == query(x + 1)) & (key(match) == query(True))).value(seq)
seq = where(match, seq, y)
return seq.name("slide")
slide(tokens != "<").input("xxxh<<<l")
Challenge Eight: Increase
You want to perform the addition of two numbers. Here are the steps.
add().input("683+345")
- Divide into two parts. Convert to plastic. join in
“683+345” => [0, 0, 0, 9, 12, 8]
- Calculate the carry clause. Three possibilities: 1 carries, 0 does not carry, < maybe carries.
[0, 0, 0, 9, 12, 8] => “00<100”
- Sliding Carry Coefficient
“00<100” => 001100"
- complete addition
These are 1 line of code. The complete system is 6 attention mechanisms. (Though Gail says you can do it in 5 if you're careful enough!).
def add(sop=tokens):
# 0) Parse and add
x = atoi(split("+", 0, sop)) + atoi(split("+", 1, sop))
# 1) Check for carries
carry = shift(-1, "0", where(x > 9, "1", where(x == 9, "<", "0")))
# 2) In parallel, slide carries to their column
carries = atoi(slide(carry != "<", carry))
# 3) Add in carries.
return (x + carries) % 10
add()("683+345")
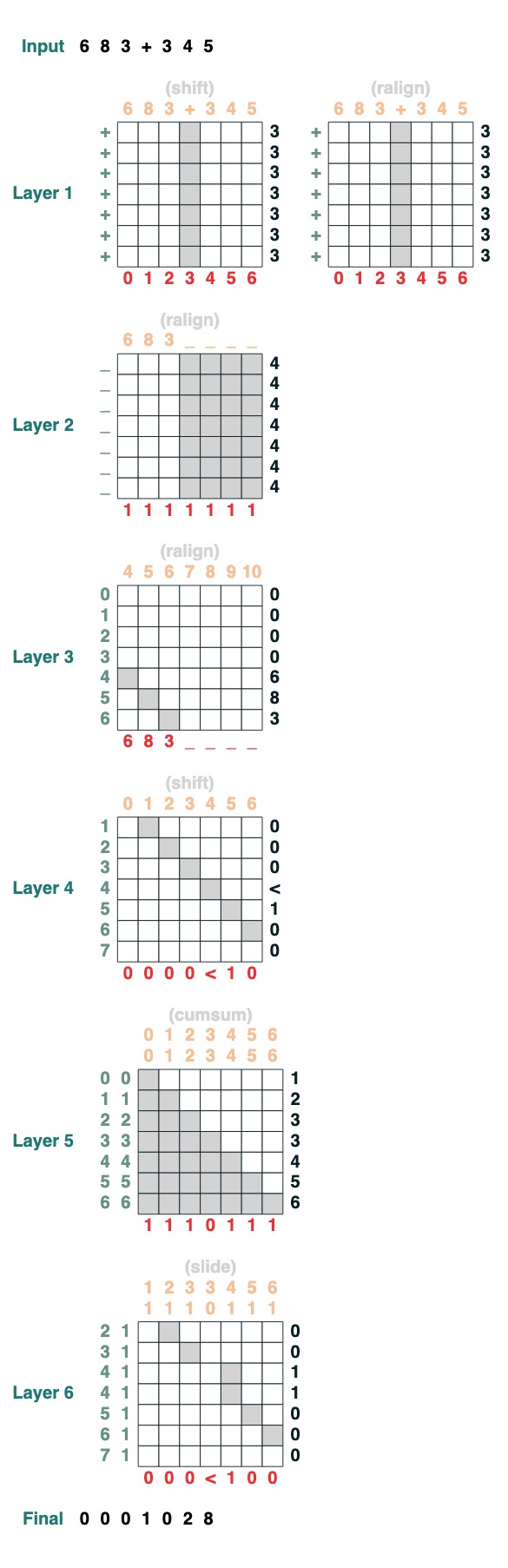
683 + 345
1028
Done perfectly!
References & In-text Links:
- If you are interested in this topic and want to know more, check out the paper: Thinking Like Transformers
- and learn more about the RASP language
- If you are interested in "Formal Languages and Neural Networks" (FLaNN) or know someone who is interested, welcome to invite them to join our online community !
- This blog post contains the content of the library, notebook and blog post
- This blog post was co-authored by Sasha Rush and Gail Weiss
<hr>
Original English text: Thinking Like Transformers
Translator: innovation64 (Li Yang)