CeresDB is a high-performance, distributed cloud-native time-series database written in Rust. Its development team recently announced that after nearly a year of open source research and development, the time-series database CeresDB 1.0 is officially released, reaching production availability standards .
CeresDB 1.0 official Chinese documentation: https://docs.ceresdb.io/cn/
Introduction to the core features of CeresDB 1.0
storage engine
-
Support columnar hybrid storage
-
Efficient XOR filter
Cloud Native Distributed
-
Realize the separation of computing and storage (support OSS as data storage, WAL implementation supports OBKV, Kafka)
-
Support HASH partition table
Deployment and O&M
-
Support stand-alone deployment
-
Support distributed cluster deployment
-
Support Prometheus + Grafana to build self-monitoring
read-write protocol
-
Support SQL query and write
-
Implemented CeresDB's built-in high-performance read and write protocol, and provided multilingual SDK
-
Support Prometheus, can be used as remote storage of Prometheus
Multilingual reading and writing SDK
- Implemented client SDKs in four languages: Java, Python, Go, Rust
Introduction to CeresDB Architecture
CeresDB is a time-series database. Compared with classic time-series databases, CeresDB's goal is to be able to process data in both time-series and analytical modes at the same time, and provide efficient read and write.
In a classic time-series database, Tagcolumns ( InfluxDBcalled Tag, Prometheuscalled Label) usually generate inverted indexes for them, but in actual use, Tagthe cardinality of is different in different scenarios——— in some In the scenario, Tagthe cardinality is very high (the data in this scenario is called analytical data), and the reading and writing based on the inverted index will pay a high price for this. On the other hand, the scanning + pruning method commonly used in analytical databases can process such analytical data more efficiently.
Therefore, the basic design concept of CeresDB is to adopt a hybrid storage format and corresponding query methods, so as to efficiently process time-series data and analytical data at the same time.
The figure below shows the architecture of the stand-alone version of CeresDB
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
Performance optimization and experimental results
CeresDB uses a combination of columnar hybrid storage, data partitioning, pruning, and efficient scanning to solve the problem of poor write query performance under massive timelines (high cardinality).
write optimization
CeresDB adopts the LSM-like (Log-structured merge-tree) writing model, which does not need to process complex inverted indexes when writing, so the writing performance is better.
query optimization
The following technical means are mainly used to improve query performance:
Pruning:
-
min/max pruning: the construction cost is relatively low, and the performance is better in specific scenarios
-
XOR filter: Improve the filtering accuracy of row group in parquet file
Efficient scanning:
-
Concurrency among multiple SSTs: scan multiple SST files at the same time
-
Internal concurrency of a single SST: Supports Parquet layer to pull multiple row groups in parallel
-
Merge small IO: For files on OSS, merge small IO requests to improve pull efficiency
-
Local cache: cache files pulled by OSS, support memory and disk cache
performance test results
Performance tests were performed using TSBS. The pressure measurement parameters are as follows:
-
10 Tags
-
10 Fields
-
Timeline (Tags combination number) 100w level
Pressure test machine configuration: 24c90g
InfluxDB version: 1.8.5
CeresDB version: 1.0.0
Write performance comparison
InfluxDB write performance degrades more over time. After the writing of CeresDB is stable, the writing rate tends to be stable, and the overall writing performance is more than 1.5 times that of InfluxDB (the gap can be more than 2 times after a period of time)
In the figure below, a single row contains 10 Fields.
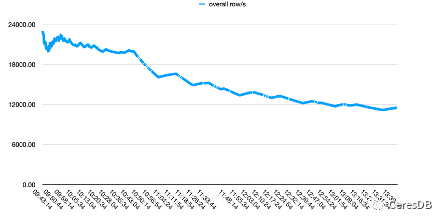
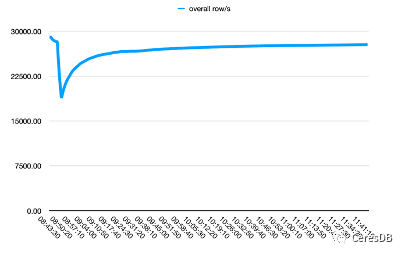
The picture above is Influxdb, and the picture below is CeresDB
Query performance comparison
Low screening condition (condition: os=Ubuntu15.10), CeresDB is 26 times faster than InfluxDB, the specific data is as follows:
-
CeresDB query time: 15s
-
InfluxDB query time: 6m43s
High screening conditions (fewer data hits, condition: hostname=[8], at this time the traditional inverted index will be more effective in theory), this is a scenario where InfluxDB has more advantages, and at this time under the condition that the warm-up is completed , CeresDB is 5 times slower than InfluxDB.
-
CeresDB:85ms
-
InfluxDB:15ms
2023 roadmap
The development team said that in 2023, after the release of CeresDB 1.0, most of their work will focus on performance, distribution, and surrounding ecology. In particular, the docking support of the surrounding ecology hopes to make it easier for various users to use CeresDB:
Surrounding ecology
-
Ecological compatibility, including compatibility with common time series database protocols such as PromQL, InfluxdbQL, and OpenTSDB
-
Operation and maintenance tool support, including k8s support, CeresDB operation and maintenance system, self-monitoring, etc.
-
Developer tools, including data import and export, etc.
performance
-
Explore new storage formats
-
Enhance different types of indexes to enhance the performance of CeresDB under different workloads
distributed
-
automatic load balancing
-
Improve availability, reliability