Interpretation of YOLOX-PAI paper
Interpretation of thesis
foreword
In 2021, Megvii proposed the YOLOX algorithm, which built a new baseline in terms of speed and accuracy. The components are flexible and deployable, and are deeply loved by the industry.
Recently, Alibaba Cloud machine learning platform team PAI reproduced the YOLOX algorithm through the self-developed PAI-EasyCV framework.
1. What is YOLOX-PAI?
YOLOX is one of the most well-known single-stage object detection methods.
YOLOX-PAI is an efficient predictor API obtained by Ali in EasyCV, using the inference optimization framework of PAI to optimize YOLOX.
2. Interpretation of the paper
0. Summary
We have developed a
EasyCVversatile computer vision toolbox called , to facilitate the use of variousSOTAcomputer vision methods. We recently addedYOLOXan improved version of toYOLOX-PAI.EasyCVAn ablation study was performed to investigate
YOLOXthe . We alsoPAI-Bladeprovide a simple usage for to speed up theBladeDISCinference process based on and .TensorRTFinally, on the
COCOdataset, the speed is 1.0 ms and the accuracy is 42.8 mAP on a single NVIDIA V100 GPU, which is slightlyYOLOv6faster than .
EasyCVA simple but efficient predictor API is also designed for end-to-end object detection.
1 Introduction
YOLOX is one of the most famous single-stage object detection methods and has been widely used in various fields such as autonomous driving and defect detection. It introduces the decoupling head and anchor-free method in the YOLO series, and achieves state-of-the-art results between 40 mAP and 50 mAP.
Considering its flexibility and efficiency, we intend to integrate YOLOX into EasyCV, an all-in-one computer vision method that can be easily used even by beginners. Furthermore, the improvement of YOLOX is studied by detecting Backbone, Neck and Head with different enhancements. Users can simply set different configurations according to their own needs to obtain a suitable target detection model.
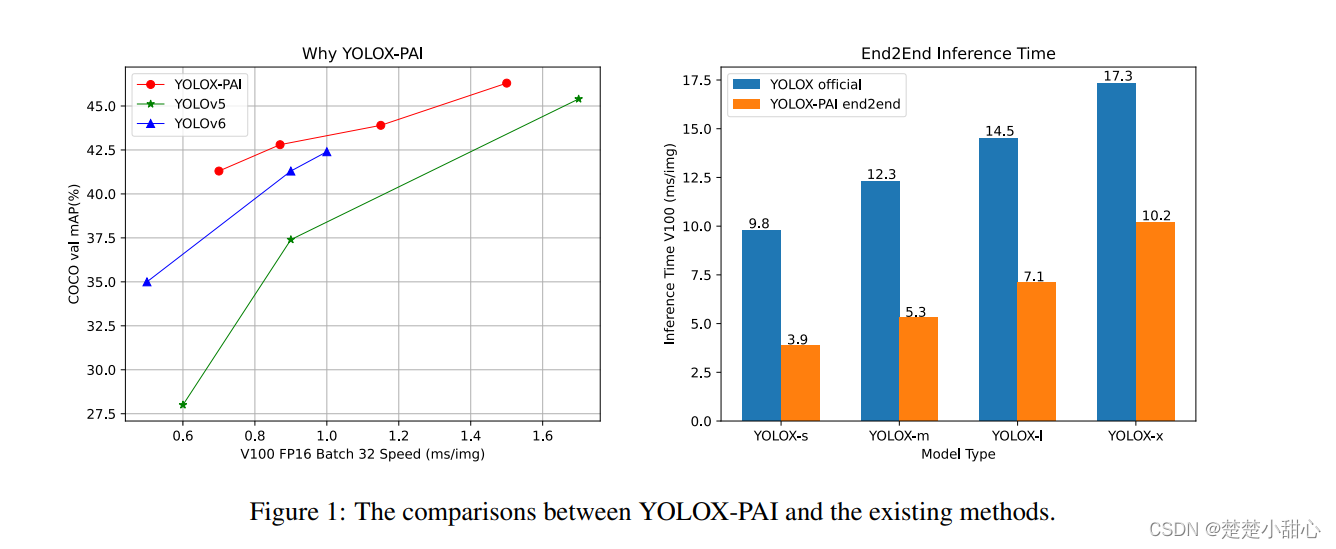
In addition, based on PAI-Blade (PAI's inference optimization framework), the inference process is further accelerated and a simple api is provided to use PAI-Blade in EasyCV. Finally, an efficient predictor API is designed to use YOLOX-PAI in an end-to-end manner, greatly speeding up the original YOLOX. The comparison between YOLOX-PAI and state-of-the-art object detection methods is shown in Figure 1.
In brief, our main contributions are as follows:
EasyCVPublished in asYOLOX-PAIa simple and efficient object detection tool (includingdockerthe process of mirroring, model training, model evaluation and model deployment). We hope that even a beginner can useYOLOX-PAIto complete his object detection task.- An ablation study is performed on existing
YOLOXobject detection methods based on , where only one configuration file is used to build a self-designedYOLOXmodel . With architectural improvementsPAI-Bladeand efficiency, the model runs inference on a single NVIDIA Tesla V100 GPU in 1ms and achieves state-of-the-art object detection results in 40 mAP and 50 mAP.EasyCVA flexible predictor is provided inAPI, which accelerates preprocessing, inference, and postprocessing, respectively. In this way, users can better use αYOLOX-PAIfor end-to-end object detection tasks.
2. Method
2.1、Backbone
Recently,
YOLOv6andPP-YOLOEhave been replacedCSPNetby . In RepVGG, a 3x3 convolutional block is used in the inference process to replace the multi-branch structure, which is beneficial to save inference time and improve the target detection results. Immediately after , we also use a based on .BackboneRepVGGYOLOv6RepVGGBackbone
2.2、neck
We use two methods to
YOLOXimprove performanceYOLOX-PAIinNeck:
- Adaptive spatial feature fusion (
ASFF) and its variants (denoted asASFF_Sim) for feature enhancement;- GSConv, a lightweight convolutional block to reduce computational cost.
The original
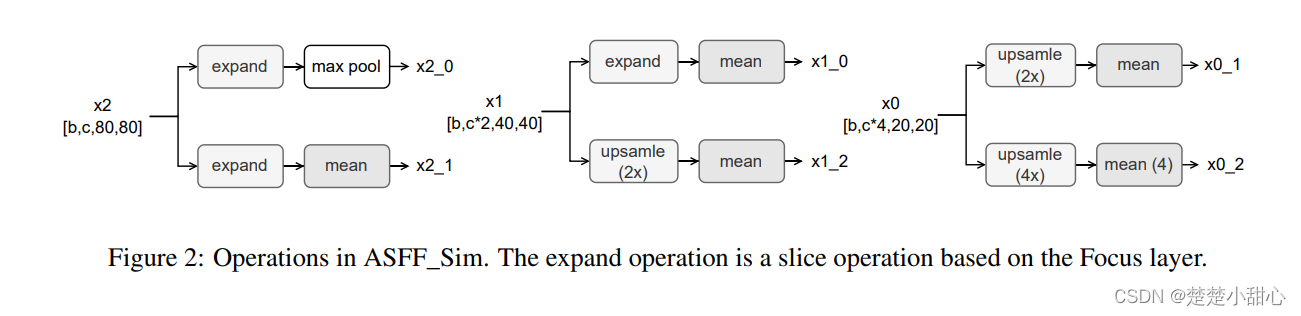
ASFFmethod uses severalvanillaconvolutional blocks to first unify the dimensions of different feature maps. Inspired by theYOLOv5middleFocuslayer, we replace the convolutional blocks by using non-parametric slice operations and mean operations to obtain a unified feature map (denoted asASFF_Sim). Specifically,YOLOXthe output operations for each feature map are defined in Fig. 2.
We also use 2 based
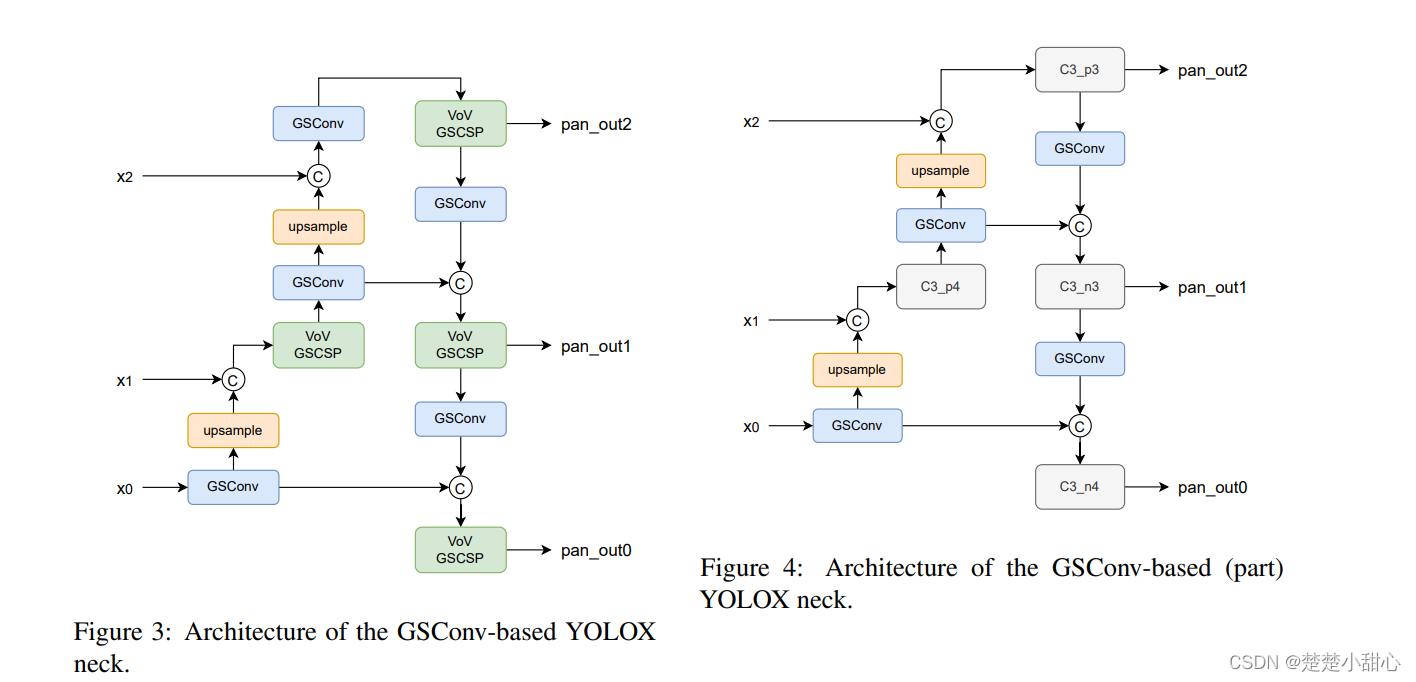
GSConvonNeckto optimizeYOLOX. TheNeckarchitecture shown in Figures 3 and 4. The difference between the two architectures is whether all blocks are replaced withGSConv. As demonstrated by the authors, itGSconvis specificallyNeckdesigned .
2.3、head
The authors augmented it with an attention mechanism
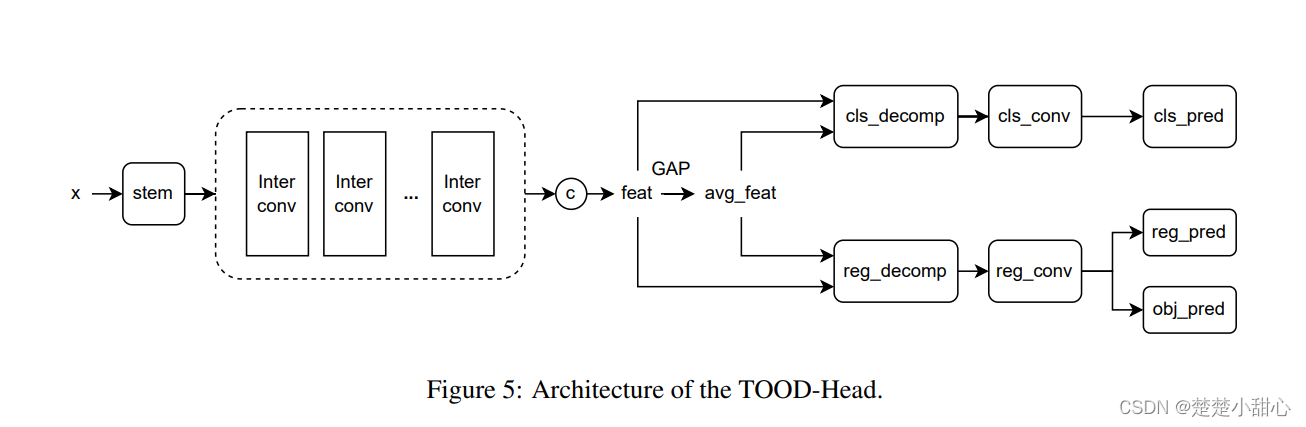
YOLOX-Headto coordinate the task of object detection and classification (denoted asTOOD-Head). The architecture is shown in Figure 5. First, aStemlayer is used for channel compression, and then the middle feature layer is obtained by stacking convolutional layers. Finally, adaptive weights are calculated according to different tasks. The results of using convolution in and convolution based onTOOD-Headare tested separately .vanillarepvgg
2.4、PAI-Blade
PAI-Bladeis a simple yet powerful inference optimization framework for model acceleration. It is based on many optimization techniques, such asBlade Graph Optimizer,TensorRT,PAI-TAO(Tensor Accelerator and Optimizer) and so on.PAI-BladeThe best way to feed automatic search optimization into the model. Therefore, people without model deployment expertise can also usePAI-Bladeto inference process. TheEasyCVauthor integrated thePAI-Bladeuse of in , allowing users to obtain efficient models only by changing the export configuration.
2.5、EasyCV Predictor
Besides model inference, pre-processing and post-processing functions are also important in end-to-end object detection tasks, which are often neglected by existing object detection toolboxes.
EasyCVIn , we allow the user the flexibility to choose whether to export the model with pre/post processing procedures. Then, a predictor is providedapito perform an efficient end-to-end object detection task with only a few lines of code.
3. Experiment
In this section, we will report the ablation research results of the above methods on the COCO dataset, and compare them with YOLOXPAI and SOTA object detection methods.
3.1, SOTA comparison
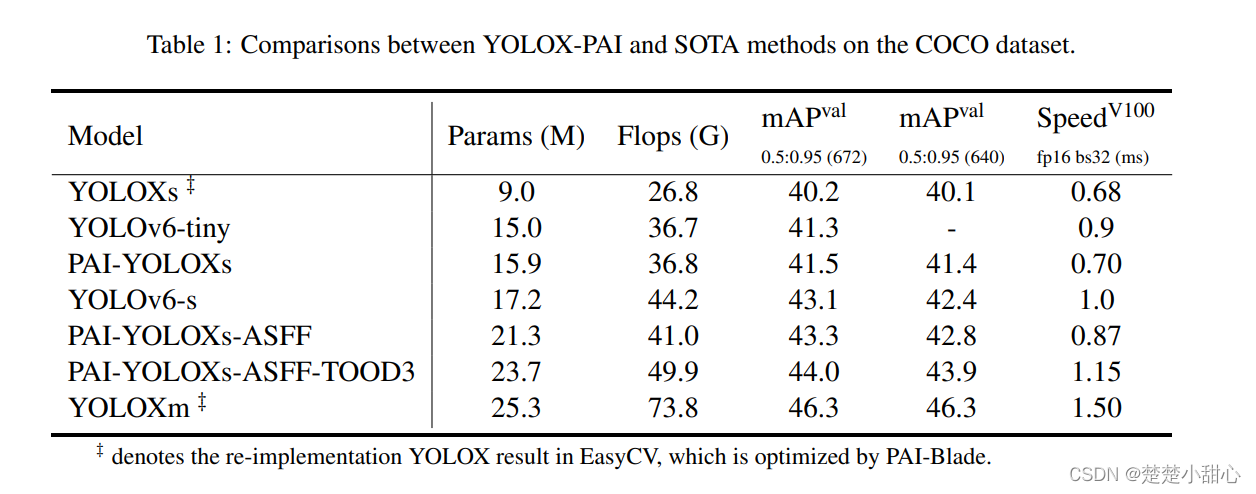
- We selected improvements that are useful in YOLOX-PAI, compared with the SOTA YOLOv6 method in Table 1. It can be seen intuitively that YOLOX-PAI is much faster than the corresponding version of YOLOv6.
- Has better mAP ( 0.2 mAP and 22% speed improvement compared to YOLOv6-tiny , 0.2 mAP and 13% speed improvement compared to YOLOv6-s )
3.2. Ablation research
- The impact of the backbone
As shown in Table 1: YOLOX achieves better mAP with a RepVGG -based backbone, only sacrificing a little bit of speed. It does add more parameters and calculations, requiring more computing resources, but no additional inference time. Considering the performance, we use it as a flexible configuration setting in EasyCV .
- Effects on the neck .
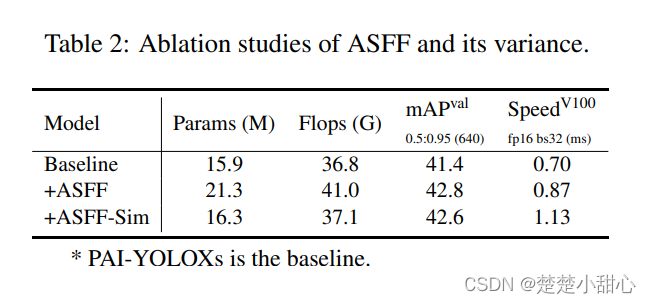
The impact of ASFF and ASFF_Sim is shown in Table 2.
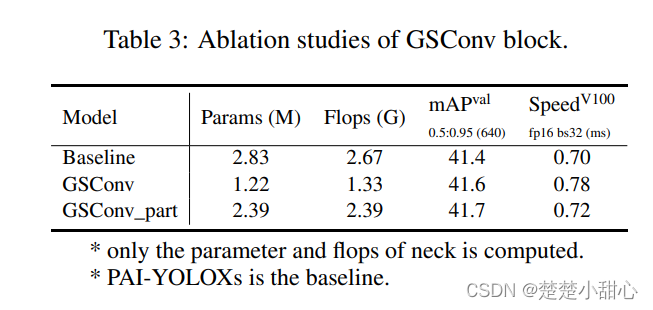
Compared with ASFF, ASFF_Sim only needs to increase some parameters and calculations to improve the detection results. However, there will be an increase in inference time, and we will implement CustomOP to optimize it in the future. The results affecting GSConv are shown in Table 3, GSConv will bring a 0.3 mAP improvement and a 3% speed reduction on a single NVIDIA V100 GPU.
- head impact.
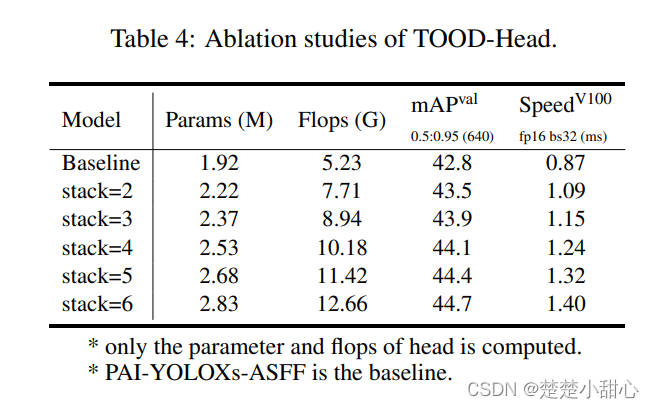
Table 4 shows the impact of TOODHead .
We investigate the effect of different numbers of inner convolutional layers on the model.
Studies have shown that detection results get better when additional convolutional layers are added. A good trade-off in choosing the right hyperparameters is between speed and accuracy. We found that when replacing repconv-based convolutional layers with vanilla convolutions, the results get worse. When the number of stacked layers is relatively small , using the Repconv-based cls_conv/reg_conv layer can slightly improve the results.
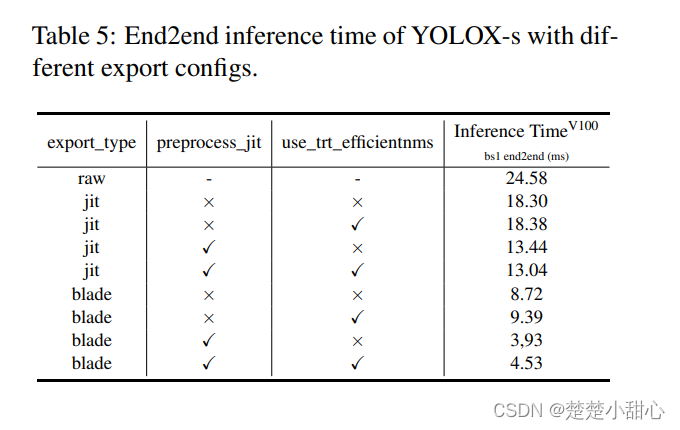
3.3. End-to-end results
Table 5 shows the end-to-end prediction results of YOLOXs models with different export configurations . The keywords in this table are the same as the configuration files in EasyCV. Obviously, blade optimization helps to optimize the inference process . In addition, the preprocessing process can be accelerated by exporting jit models. As for post-processing , we are still working on a better CustomOP, which can be optimized with PAI Blade to get a better boost. On the right side of Figure 1, it can be seen that by optimizing the PAI-blade and EasyCV predictors , we can get satisfactory end-to-end inference time on YOLOX.
4 Conclusion
- In this paper, we introduce YOLOX-PAI, an improved version of YOLOX based on EasyCV.
- By improving the model architecture and PAI blade , it achieves state-of-the-art object detection results in 40mAP to 50mAP .
- We also provide a simple and efficient prediction API to perform end-to-end object detection.
- EasyCV is a versatile toolbox focused on SOTA computer vision methods, especially in self-supervised learning and visual converters . We hope that users can use Easy CV to quickly perform computer vision tasks and fall in love with computer vision.
5. Thanks
We thank the authors of all the algorithms reimplemented in EasyCV, and their contributions in the github community. We also thank Tianyou Guo, Nana Jiang, Haipeng Fang, Jiayu Chen, and many other members of the Alibaba PAI team for their contributions in building the YOLOX-PAI and EasyCV toolkits.