Authors: Gu Rong , Wu Tongyu , Nanjing University
background
A public cloud is a platform that provides users with economical and convenient computing resources. With the rapid development of cloud computing technology and the increasing demand for big data query, more and more OLAP engine services on the cloud have appeared in the cloud computing application market of many public clouds. In order to be able to select a suitable OLAP engine according to their own business requirements and run the engine in the best state through suitable configuration, users need to evaluate the performance of the currently used query engine.
The current OLAP engine performance evaluation framework faces three main challenges when deployed on the cloud:
1. The ability to adapt to the cloud environment is weak. When the traditional performance evaluation framework was born, it did not have the unique PaaS, IaaS, and SaaS features on the cloud, nor did it have the adaptation support for the separation of storage and computing. When using OLAP on the cloud, you need to make full use of cloud computing features to analyze the performance of the OLAP engine.
2. It does not have the ability to reproduce complex workloads. A workload consists of datasets, query sets, and query sequences. Traditional performance evaluation frameworks usually use fixed datasets and query levels, and the query sequences are mainly linear sequences. The complexity of modern OLAP query scenarios puts forward higher requirements for the characterization of data sets and query sets in specific scenarios, and the support of high-concurrency and complex scenarios.
3. It is difficult to comprehensively evaluate query performance and cloud access costs. Traditional evaluation systems (such as TPC-H and TPC-DS) do not reflect the cost factor, and in a large environment with nearly unlimited resources on the cloud, evaluation without considering cost will cause great bias and even come to wrong conclusions. Cloud computing has the characteristics of customizing the scale of rented servers, so the cost on the cloud is variable and can be set, and its unit price also fluctuates over time. Users not only want OLAP queries to be executed at the fastest speed, but also want to save costs as much as possible. Therefore, a performance evaluation framework is required to comprehensively evaluate query performance and cloud access costs, and provide the most cost-effective cloud server and OLAP engine combination according to user needs. Way.
In response to the above problems, teachers such as Nanjing University Gu Rong, Dr. Wu Tongyu and others have jointly researched with the Apache Kylin community team to design and develop a query performance evaluation framework for OLAP engines on the cloud, named Raven.
Raven is designed to help users answer some practical and important questions facing the cloud on OLAP engines:
- For a real workload (data loading + querying) on a real production data set, which OLAP engine runs on the cloud with lower IT costs?
- Given a query speed target, which OLAP engine can give lower IT costs on the cloud under the premise of achieving the speed target?
- What if you factor in the speed of data loading?
This article will introduce the problems encountered by the team in designing and implementing Raven, the corresponding solutions, and the current preliminary research results.
Design of performance evaluation framework adapted to cloud architecture
When the OLAP engine query performance evaluation framework adapts to the cloud architecture, it is actually adapting to the PaaS, IaaS, and SaaS features on the cloud. Specifically, many functions of cloud servers are presented to users in the form of services. Users only need to call the interface of the corresponding service to achieve different purposes, such as cloud server creation, file operation, performance index acquisition, application execution, etc. . In file operations, because the cloud server adopts the architecture of separation of computing and storage, some data may need to be pulled from the remote cloud storage service through the service.
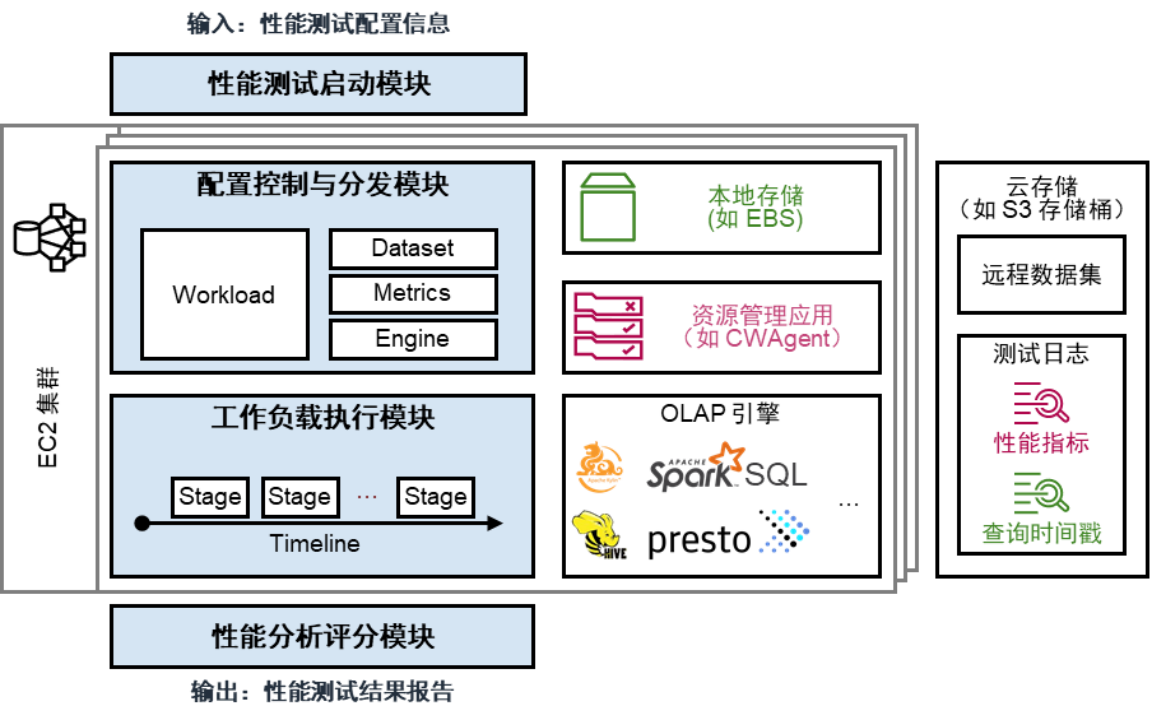
Figure 1: Raven performance evaluation framework based on public cloud platform
Combining the above requirements, Raven's framework is shown in Figure 1. Its execution steps are as follows:
1. The user enters the performance test configuration information to trigger the performance test startup module, which is responsible for creating the cloud server and computing environment required to start the OLAP performance test on the cloud according to the user configuration.
2. The performance test startup module transmits the workload, data sets, performance indicators, engine parameters and other information to the configuration control and distribution module, which is responsible for distributing the above information to the corresponding service interface or module.
3. The configuration control and distribution module triggers the workload execution module, and the workload execution module starts the configured OLAP engine, and sends query requests to the OLAP engine over time according to the workload settings.
4. The OLAP engine pulls data sets from local storage or cloud storage and executes queries. During the query execution process, the workload execution module records the timestamps of the start and end of the query, and starts the resource management service to monitor the performance indicators during the query period of the OLAP engine. At the end of the query, the workload execution module outputs the timestamp and performance indicator information to cloud storage.
5. Start the performance analysis scoring module, pull the timestamp and performance index information from the remote cloud storage, import the user-defined scoring model, and obtain the final performance evaluation result.
The advantages of the above design are:
1. Make full use of the number and configuration of customizable cloud servers, allowing users to customize the cluster environment they wish to create.
2. It supports reading and writing data to remote cloud storage services, and adapts to the storage-computing separation architecture of the cloud environment.
3. Using the resource management service of the cloud service provider, it is possible to obtain a large amount of information on the usage of system resources.
4. Support pluggable engine interface, users can arbitrarily specify the OLAP engine and its configuration to be tested.
In actual use, the user's input is presented in a .yaml file, which can be modeled as follows:
engine: Kylin
workload: tpc-h
test_plan: one-pass
metrics: all
The number of cloud servers required by users, the configuration of each machine, different engines, etc., can be configured through JSON files.
Workload design based on events and timestamps
Traditional OLAP query engines usually use fixed datasets and query sets, and execute a series of queries to check the query performance of the OLAP engine. However, today's workloads in many industries are becoming more complex.
1. More and more enterprises realize that their data and business have distinct characteristics, and hope to obtain the best OLAP query solution under the given data characteristics.
2. In addition to traditional OLAP queries, more and more pre-computing technologies, such as ETL, indexing, Kylin's Cube, etc., need to be included in the investigation of OLAP engine performance.
3. The rapid growth of data volume has led to more and more scenarios of high concurrent queries and variable QPS queries. It is difficult for traditional linear query methods to accurately evaluate the above new scenarios.
Raven uses a timeline-based event mechanism to describe complex OLAP work scenarios. Under this mechanism, a workload consists of multiple stages, and a stage consists of multiple events. On the timeline, a workload is described as a sequential execution of several stages. Each stage is divided into two types: online stage and offline stage: the online stage executes the actual query request, and the offline stage executes operations such as pre-computation. An event is an abstraction of each atomic execution unit in a workload, which can be a query request, a shell command, or a script written in a programming language such as Python.
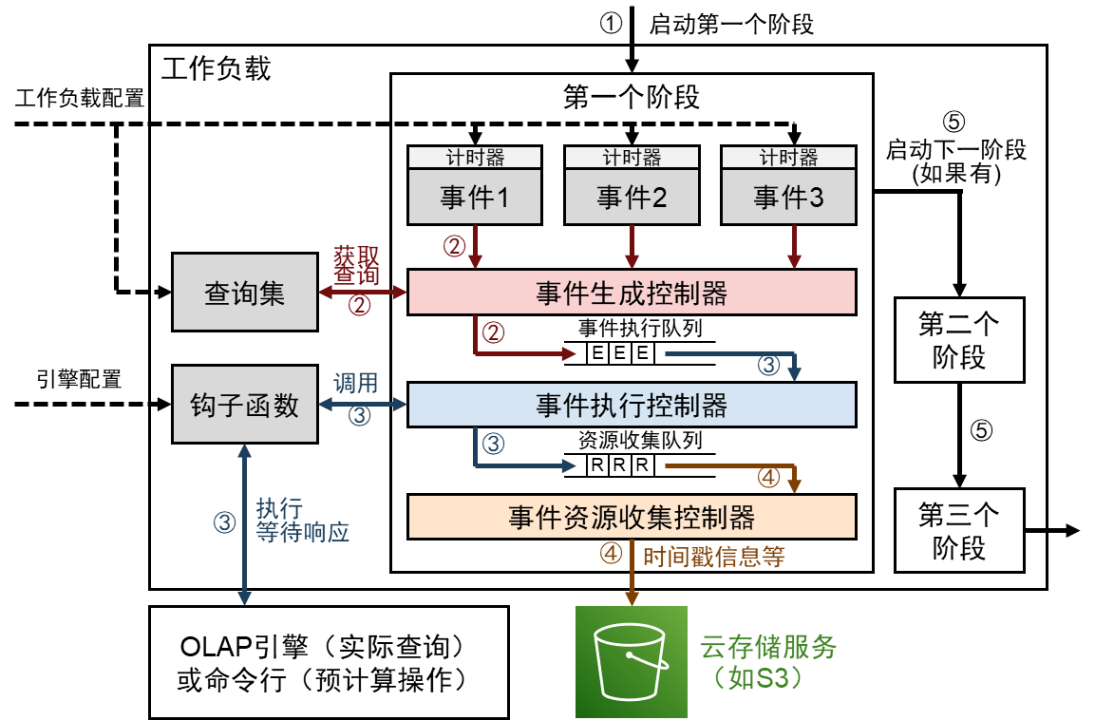
Figure 2: Execution of a Raven workload
The Raven workload is shown in Figure 2. Its execution steps are as follows:
1. Start the first stage, load workload configuration, engine configuration, etc.;
2. When the event timer is triggered, the time event is generated into a controller, the query statement or script content corresponding to the event is read, and the event execution queue is entered to wait for execution.
3. After exiting the event execution queue, enter the event execution controller, start the thread execution hook function, perform interactive operations with the OLAP engine or command line, and wait for the response, and insert the event into the resource collection queue after getting the response.
4. After exiting the resource collection queue, enter the event resource collection controller, and output the timestamp information of the operation to the cloud storage service.
5. When all time in that stage is complete, start the next stage, and then execute each stage in sequence until the entire workload finishes.
The advantages of the above design are:
1. Support custom data sets and query sets, allowing users to make full use of their business characteristics for performance evaluation.
2. Supports precomputing, allowing users to evaluate the overall performance of precomputing and actual queries.
3. Time-stamped execution methods and thread management strategies support high concurrent queries and allow simulation of workloads with QPS fluctuating over time.
For example, you can use the following .yaml configuration file to start an EC2 cluster with one master and four slaves on AWS, deploy the Presto engine, specify the dataset as SSB (SF=100) and the workload satisfies the Poisson distribution (λ= 3.0) with a workload duration of 600 seconds:
Cloud:
Name: AWS
Description: Amazon Web Service.
Properties:
Region: ap-southeast-1
Ec2KeyName: key_raven
MasterInstaceCount: 1
MasterInstanceType: m5.xlarge
CoreInstanceCount: 4
CoreInstanceType: m5.4xlarge
Engine:
Name: soon
Description: Presto.
Properties:
host: localhost
port: 8080
user: hive
catalog: hive
concurrency: 1
Test plan:
Name: Timeline template.
Properties:
Type: Timeline
Path: config/testplan/template/timeline_template.yaml
Workload:
Name: SSB
Type: QPS
Parameters:
database: ssb_100
distribution: poisson
duration: 600
lam: 3.0
Raven presets some common workloads for users to use, such as uniform distribution, burst high concurrency distribution, etc.
Performance Evaluation Model Based on Custom Multivariate Function
In terms of performance evaluation, a feature of the machine on the cloud is that the size and configuration can be customized and adjusted. Therefore, if only query performance is considered, performance can theoretically be improved by renting a large number of high-performance devices. However, this will also lead to soaring computing costs on the cloud. Therefore, a mechanism is needed to achieve a balance and comprehensive consideration of performance and cost.
Raven's performance evaluation method is highly customizable, allowing users to combine functional expressions to obtain an evaluation score based on available parameter metrics.
The parameter indicators available in Raven mainly include the following categories:
1. Query quality indicators: including the total query time, average query time, 95% quantile of query time, and maximum query time of all queries;
2. Resource utilization efficiency: the average utilization rate of memory and CPU, load balancing, and the proportion of time when the resource occupancy rate exceeds 90% to the total time;
3. The cost of money on the cloud: It can be obtained directly through the application services provided by the cloud service provider, which mainly includes four parts of overhead: storage, computing, service invocation, and network transmission.
The ratings given by Raven are relative and can only be compared between ratings from the same model. The performance evaluation score is the product of the cost on the cloud and the overhead on the cloud. The lower the score, the better the performance of the OLAP engine. The cloud overhead can be calculated using a linear model to give weights to the above parameters; or a nonlinear model can be used to substitute the above parameters into a function expression.
Raven also provides users with a series of template functions:
1. Comprehensive model: \(PTO=10 \times \ln \left(P o C \times\left(r_{avg}+q_{avg}\right)\right)\) .
2. Speed priority model: \(PTO=10 \times \ln \left(r_{avg}+q_{avg}\right) \)
3. Budget priority model: \(PTO=\frac{1}{1+e^{8(bP o C)}} \times\left(r_{avg}+q_{avg}\right) \)
4. Query efficiency model: \(PTO=P o C \times \frac{q_{\max }+5 q_{95 \%}+94 q_{avg}}{100}\)
5. Query blocking model: \(PTO=P o C \times \ln \left(r_{\text {max }}\right) \)
Among them, PTO represents the performance score, PoC represents the cost on the cloud, \(r_{avg}\) , \(q_{avg}\) represent the average response time and average execution time, respectively, \(r_{max}\) , \ ( q_{max}\) represents the maximum response time and maximum execution time, respectively, b![]() represents the budget amount, and \(q_{95\%}\) represents the 95% quantile of the query time. Here, we review the previous issues that users need to pay attention to. It is not difficult to see that the budget-first model is mainly used to evaluate and answer: Which OLAP engine runs on the cloud with lower IT costs? The speed priority model, the query efficiency model, and the query blocking model are mainly used to evaluate and answer: which OLAP engine has a lower running cost on the cloud under the condition of satisfying constraints such as different query responses? The comprehensive model is a cloud performance model that evaluates the OLAP engine by setting different weights to comprehensively consider the cost budget and query response efficiency.
represents the budget amount, and \(q_{95\%}\) represents the 95% quantile of the query time. Here, we review the previous issues that users need to pay attention to. It is not difficult to see that the budget-first model is mainly used to evaluate and answer: Which OLAP engine runs on the cloud with lower IT costs? The speed priority model, the query efficiency model, and the query blocking model are mainly used to evaluate and answer: which OLAP engine has a lower running cost on the cloud under the condition of satisfying constraints such as different query responses? The comprehensive model is a cloud performance model that evaluates the OLAP engine by setting different weights to comprehensively consider the cost budget and query response efficiency.
Implementation and effect verification
We implemented the above design of Raven on Amazon AWS, and used the performance evaluation framework to execute the OLAP engine to see the query effect of different engines.
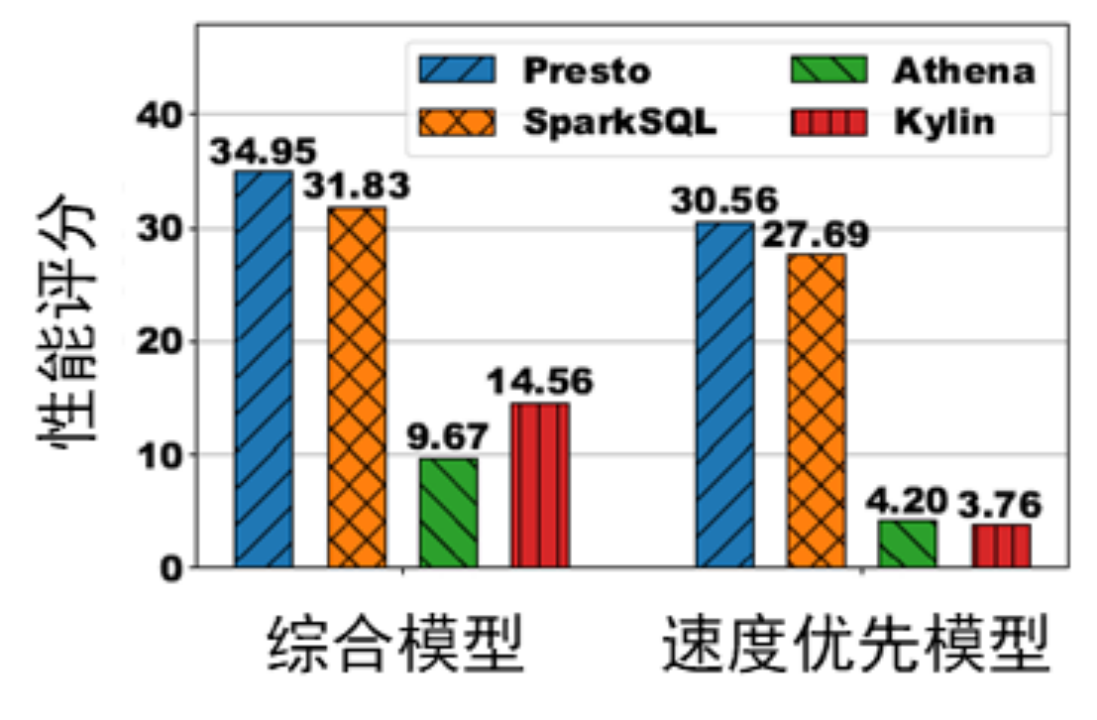
Figure 3: Performance scores of different engines running an average query for 10 minutes under different scoring models
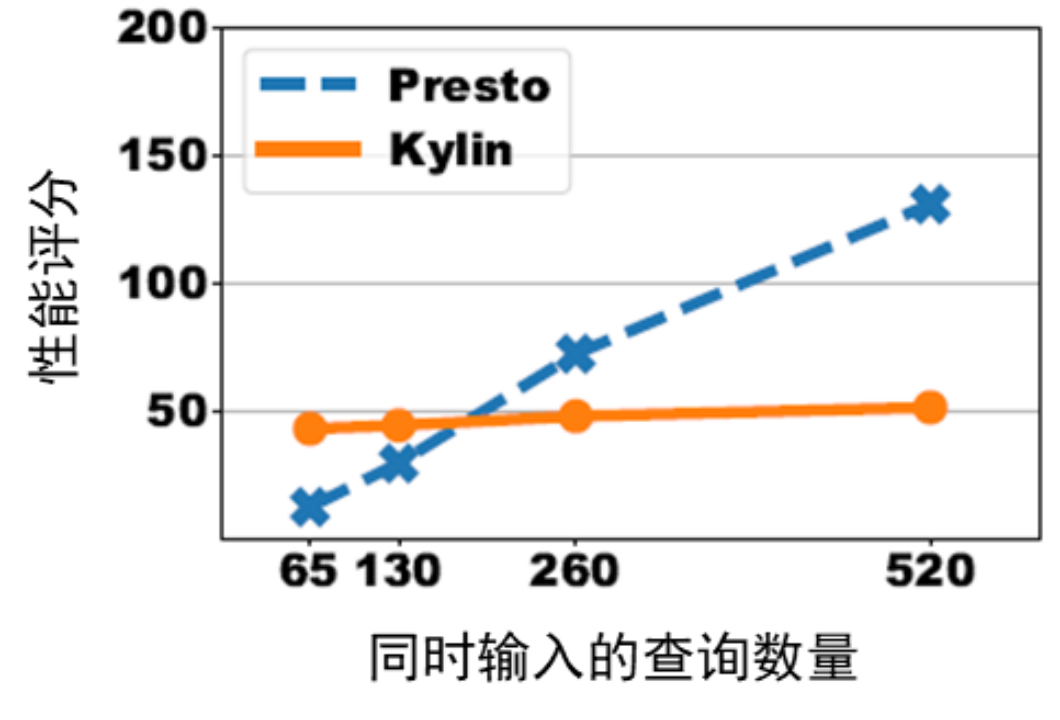
Figure 4: Performance scores for running burst high concurrency distributions on Presto and Kylin
As can be seen in Figure 3, Athena and Kylin are the better solutions when running uniform queries. However, using different models will lead to different evaluation conclusions. When comprehensively considering the on-cloud cost of query speed, since Athena executes the query directly by calling the service, the on-cloud cost is lower and the score is also lower. However, when speed is a priority, because Kylin uses precomputing techniques to achieve high-speed queries, Kylin scores lower when using a speed-first model.
As can be seen from Figure 4, when running the burst high concurrency distribution, if the query blocking model is used, as the number of simultaneous input queries increases, the performance score of Presto increases linearly with the increase in the number of queries; however, Kylin is not affected by the increase in the number of queries. , the performance score remains stable. This is because Kylin's pre-computing technology improves computing efficiency. When a large number of queries are influx, Kylin can process these queries with higher efficiency, reduce the blocking of queries in the queue, and make the performance score better. Of course, if the number of queries in the user set is small, Presto's performance score is more advantageous because it has no associated overhead of precomputing.
future outlook
Future research will mainly consider the following aspects:
1. The application implements more engines and tries to be compatible with cloud native engines for performance evaluation.
2. Optimize the expression of workloads, so that users can more easily develop diverse and representative workloads according to their own business needs.
3. Form more standardized scoring models for horizontal comparison between different workloads.
4. Combined with the current scoring results, further analyze the performance advantages and disadvantages of different OLAP engines.