1. Background
Natural language processing is to let the computer understand human language. As for whether the computer really understands the human language, this is an unknown number. My understanding is that it has not understood human language so far, just look up the table to give Just come up with the most probable response. So what fields does Natural Language Processing (NLP) include? Text classification (such as spam classification, sentiment analysis), machine translation, summarization, grammar analysis, word segmentation, part-of-speech tagging, entity recognition (NER), speech recognition, etc., are all problems to be solved by NLP. So after solving these problems, whether the computer really understands the meaning of human language is still unknown, and this article does not discuss too much. The unit of language is a word, so how does a computer represent a word, and what technology is used to represent a word so that the computer can understand the meaning of the word? This blog will discuss in detail, from bool model, to vector space model, to various word embedding (word2vec, elmo, GPT, BERT)
The primitive age
Before Deeplearning, there was no conventional way to represent a word. How to represent it depends on the task you want to solve.
1. Bool model
There are two sentences below to find text similarity.
I like Leslie Cheung
do you like Andy Lau
Then, the Boolean model is relatively simple and rude. The dimension of the word that appears is 1, and the dimension of the word that does not appear is 0, as shown below:

Then find the cosine of the two vectors.
In the bool model, since the feature value has only two values, 1 and 0, it cannot reflect the importance of the feature item in the text well.
2. VSM (Vector Space Model)
The Bool model can actually be regarded as a special case of VSM, but the value filled in each dimension of VSM is processed by some special rules. VSM is as follows:
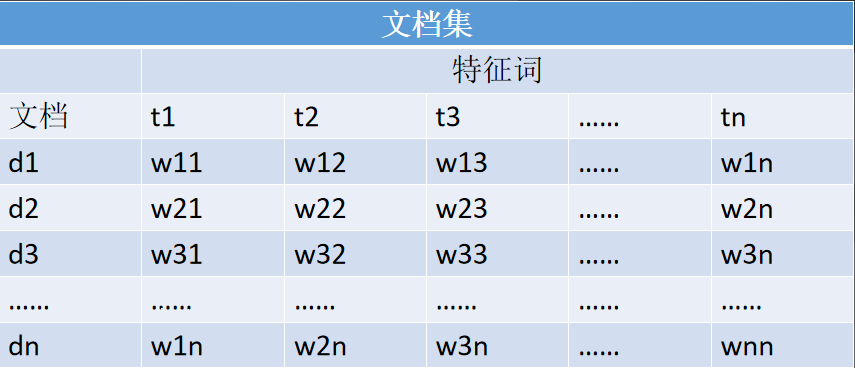
t represents a feature item, d represents a Document, then D can be represented as an N-dimensional vector of D={t1, t2, t3...tN}, how to fill in the value of w? The only way is TF*IDF, TF means word frequency, IDF means inverse word frequency, the formula is as follows:
TF(t) = the number of occurrences of the feature word in the document / the total number of words in the document
IDF(t)=log(N/(n+1)), where N is the total number of texts in the text set, and n is the number of documents containing the feature word t
Of course, TF*IDF also has its flaws, ignoring the distribution in the class and ignoring the distribution between classes, then there are some improvements, for example: TF*IDF*IG, IG means information gain.
The representation of these words/documents is very mechanical and cannot reflect the contextual relationship between words, similar relationships, and so on.
3. The era of deep learning
First of all, we have to mention the language model. The language model is estimating the probability of a sentence appearing. The higher the probability, the more reasonable it is.
P(w1,w2,w3,……wn)=P(w1)*P(w2|w1)*P(w3|w1,w2)...P(wn|w1,w2....wn-1)
Usually the above formula cannot be estimated, so a Markov assumption is made. Assuming that the following word is only related to the previous word, then it is simplified to the following formula:
P(w1,w2,w3,……wn)=P(w1)*P(w2|w1)*P(w3|w2)...P(wn|wn-1)
Of course, it can also be assumed that the following words are related to the preceding N words, which is often referred to as N-gram. Language models are of great use in elmo and gpt.
1、word2vec
word2vec, is actually a single hidden layer neural network, the idea is very simple, please see the figure below
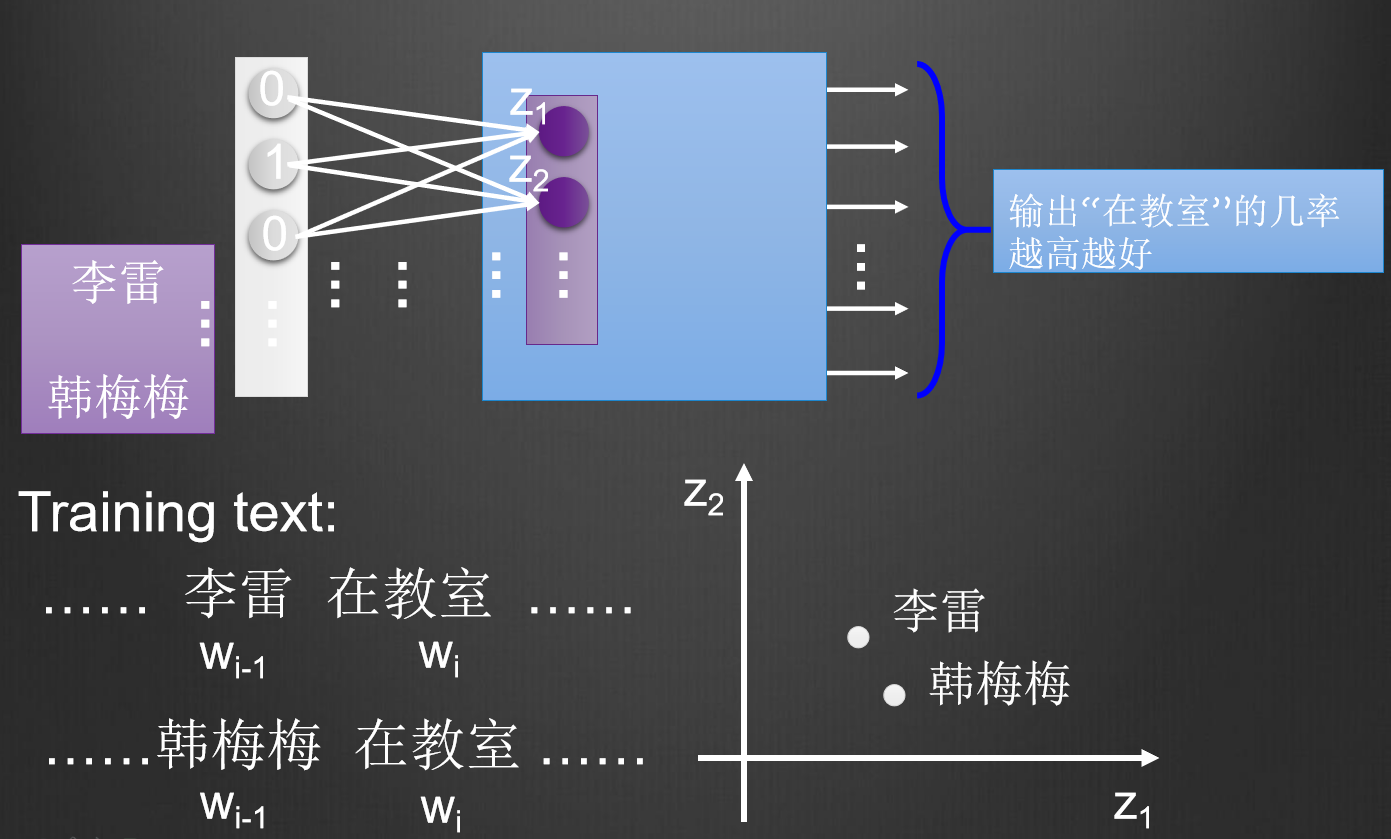
In the above picture, Li Lei and Han Meimei follow the word "in the classroom". When inputting Li Lei or Han Meimei to the neural network, it is hoped that the probability of the neural network outputting the word "in the classroom" is as high as possible, then the weight of the neural network will be Adjustment, mapping two different words to the same space, then it shows that there is some connection between Li Lei and Han Meimei, which is the idea of word2vec. There are two types of word2vec, cbow and skip-gram, cbow is a word derived from the context, and skip-gram is derived from a word context, as shown in the following figure. The result of my practice is that the effect of cbow is better.
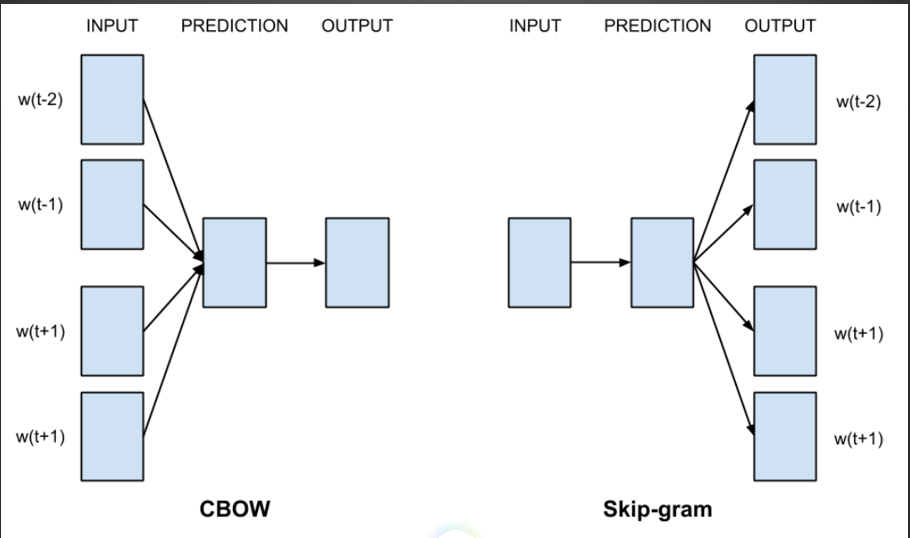
How to implement this code? In fact, it is enough to implement a neural network with a single hidden layer. The activation function of the output layer is softmax, and you can use cross entropy Loss and gradient descent. In fact, we don't have to be so troublesome at all. DL4J has provided a complete set of solutions, which can be done with a few lines of code. The code is as follows:
Word2Vec vec = new Word2Vec.Builder()
.minWordFrequency(5)
.iterations(1)
.layerSize(100)
.seed(42)
.windowSize(5)
.iterate(iter)
.tokenizerFactory(t)
.build();
vec.fit();2、ELMO
ELMO takes the initials of Embeddings from Language Model, the paper address: https://arxiv.org/abs/1802.05365
Embeddings are derived from language models. Before talking about ELMO, let's talk about the problem with word2vec. Although word2vec can represent the semantics and relationships between words, but word2vec is completely static, that is, all information is compressed into a fixed in a vector of dimensions. So for the multi-meaning word, the expressive power is relatively limited. Please see the example below,
In "want to believe in the righteousness in the world", "faith" is a verb, and "extend" means
In "Faith in the Four Seas", "faith" is a noun, and "credit" means
If the word "letter" is compressed into a 100-dimensional vector, it will be difficult to distinguish the difference between the two meanings, then this requires Contextualized Word Embedding to encode words according to different contexts, so ELMO comes.
The structure of EMLO is very simple, using a bidirectional LSTM to train a language model. As shown below (the picture is from the ppt of Li Hongyi of National Taiwan University)
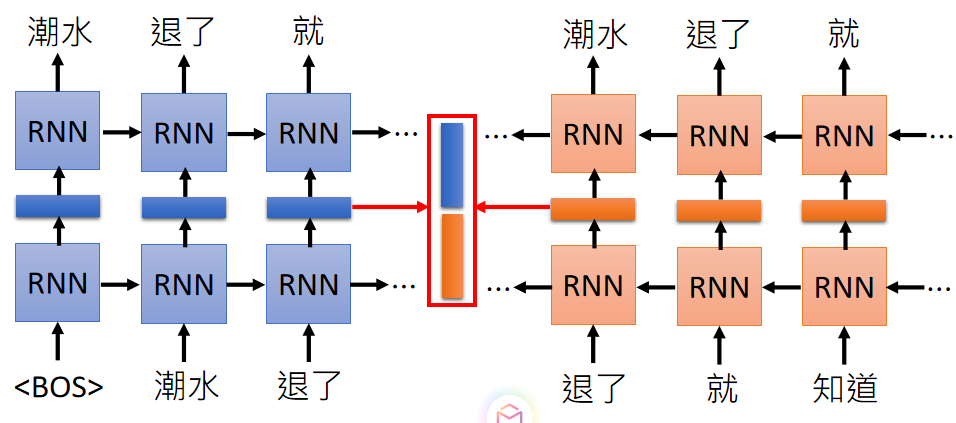
The process of model training is very simple, read in a word, read a word in reverse, predict the previous word, and continue to train until convergence. The blue and orange vectors in the red box in the middle are the vectors of Embedding, and finally the vectors we want are connected. Of course, this bi-lstm can also be stacked in many layers. Each layer gets an Embedding vector.
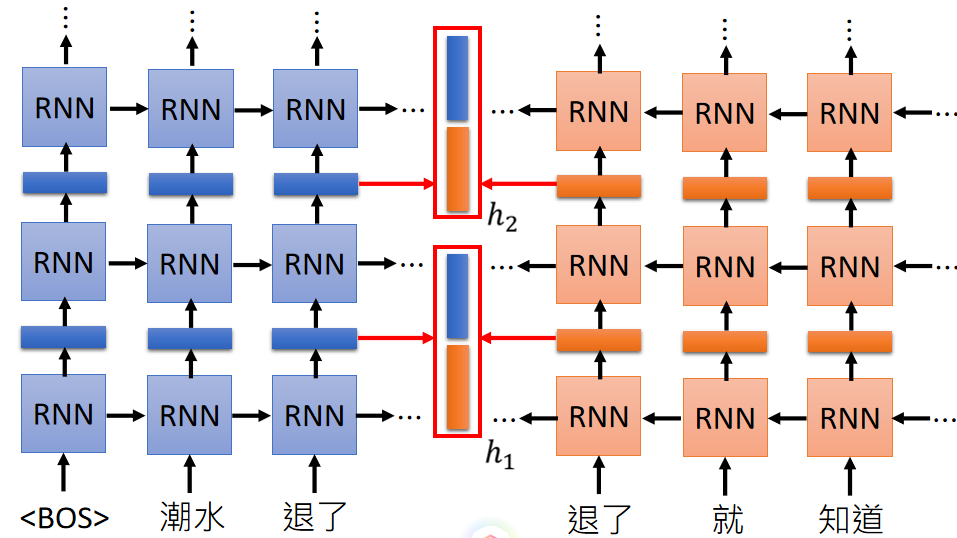
So, how to use this encoded value when using it? This depends on the downstream task. For example, the Embedding vector of each layer can be summed and averaged, or weighted summation, etc. This weight can be trained along with the task.
3、GPT
ELMO implements dynamic encoding of words, but he uses LSTM, which cannot remember long information and is not conducive to parallel computing. GPT uses self attention to change this result, of course, all this thanks to Google's masterpiece "Attention Is All You Need" paper address: https://arxiv.org/pdf/1706.03762.pdf
How does GPT work? In fact, it is to train a language model with self attention. Please see the following figure:
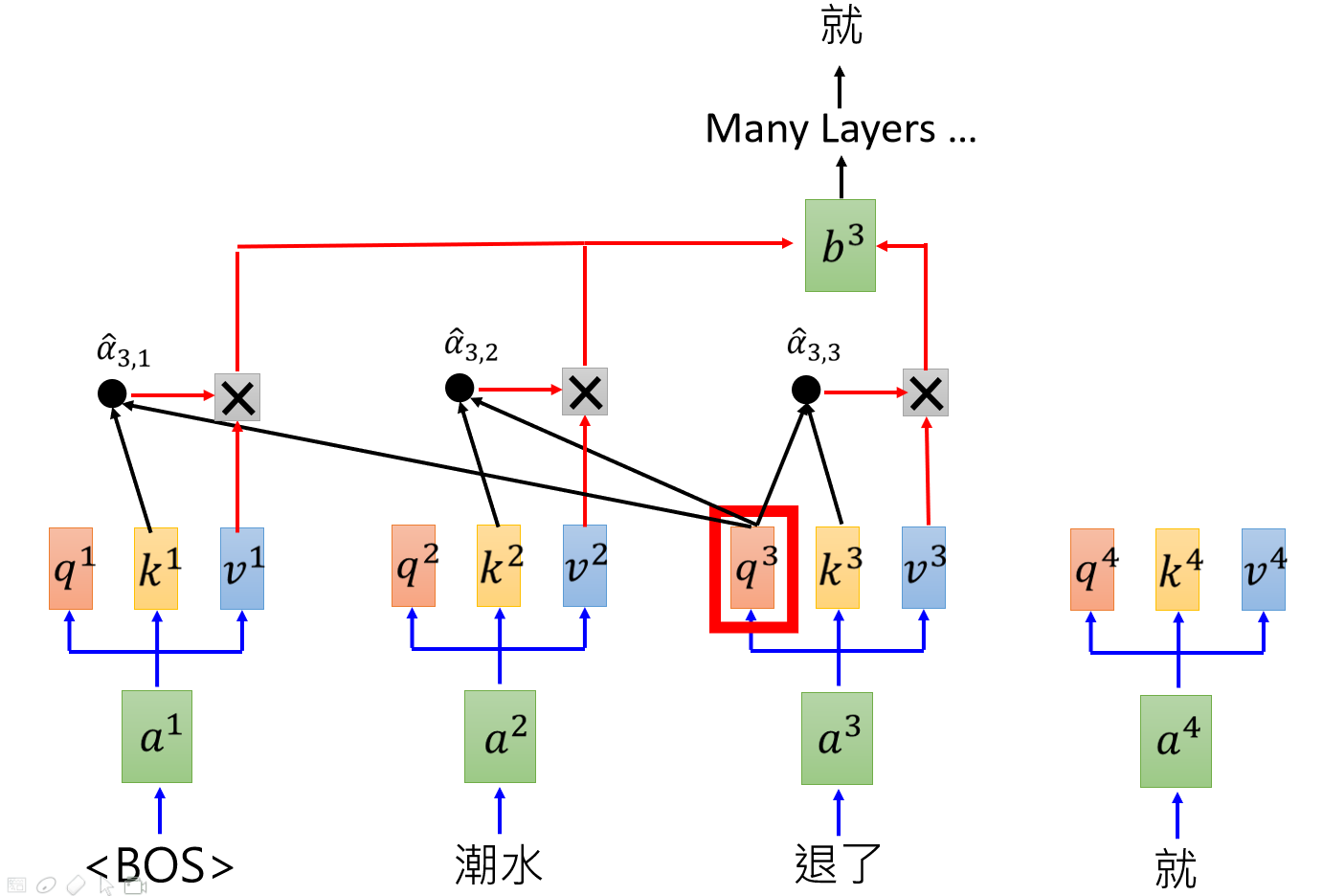
The sum of each word and the previous word is used as attention, and the next word is predicted. For example, read the start mark BOS, then make attention with yourself, predict the "tide", read in BOS, tide, and then make attention with BOS and tide to predict "Retired", and so on, until the end. After training on many corpora, a very powerful language model is obtained, which can be dynamically encoded. When using, you can fix the parameters of these attention layers, and then train other downstream tasks, such as doing sentiment classification problems, you can put these attention layers in front of several fully connected layers, fix the parameters, and only train the fully connected layers behind, Classification by softmax or sigmoid.
4、Bidirectional Encoder Representations from Transformers (BERT)
GPT has a flaw, that is, the encoding only depends on the above information and does not add the following information, so BERT solves this problem very well. BERT is actually the encoder part of the transformer, as shown below
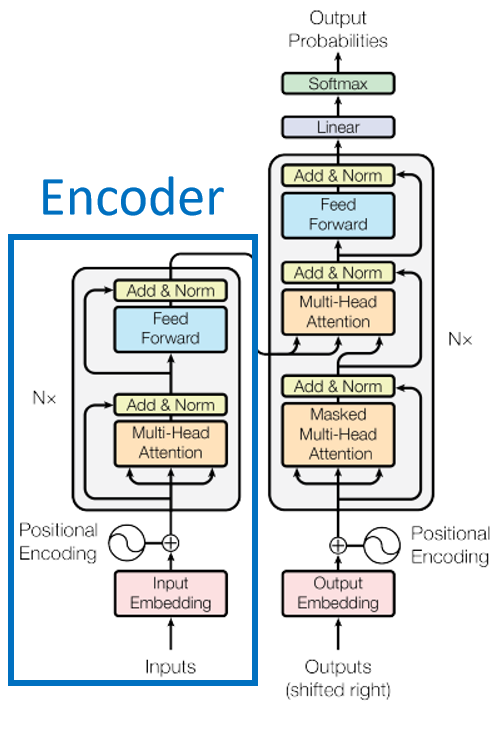
There are two methods for train BERT, Masked LM and Next Sentence Prediction. Masked LM randomly covers some words, and lets BERT guess what the covered words are. Next Sentence Prediction is to let BERT infer whether two sentences are contextually related.
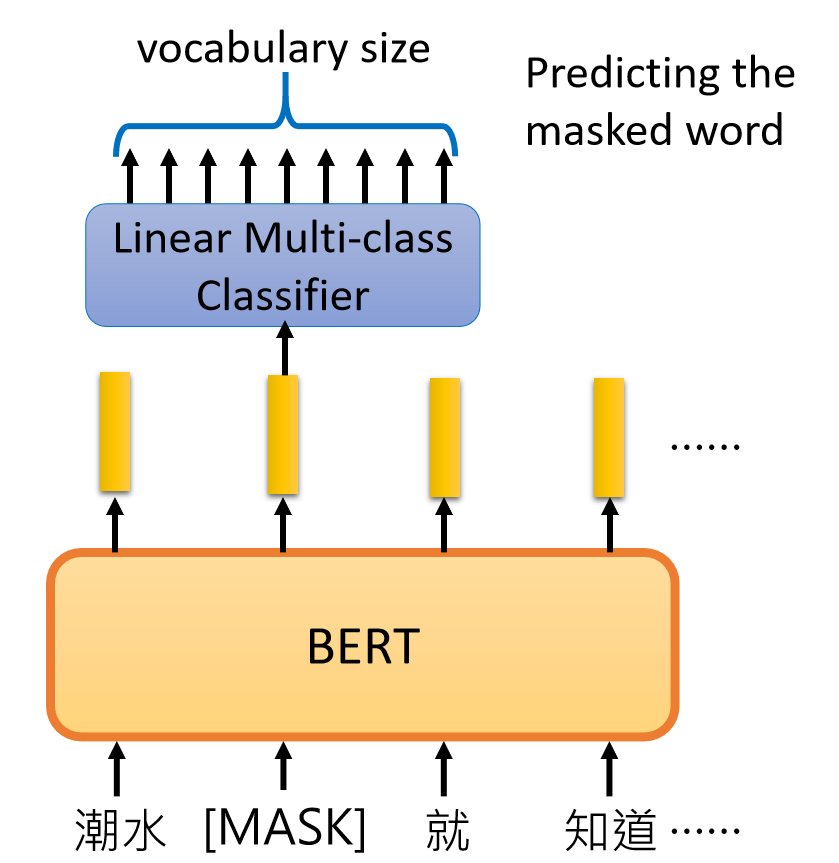
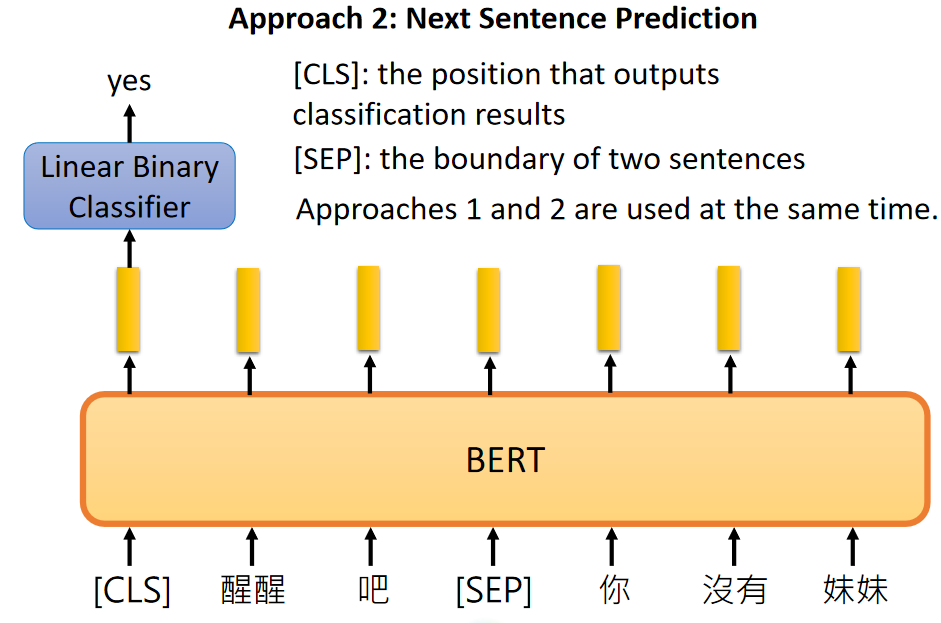
BERT fully considers the context and encodes the word, so it can well reflect the relationship between semantics and context, and is far ahead in many competitions.
4. Summary
Natural language processing from the original Boolean model, to the vector space model, to word2vec, to ELMO, to GPT, to BERT, along the way, technology replacement. So far, BERT is still the leading word Embedding method. In most natural language processing tasks, as a pre-training task, it is the first method we should try. Maybe, it won't be long before new technologies come out to refresh the results, we will wait and see. But even now, whether machines actually understand human language is an open question. The road is a long way to go, and I will go up and down to search for it.
Happiness comes from sharing.
This blog is original by the author, please indicate the source for reprinting
P(1 , each