1. Introduction to the dataset
Data source: Today's headline client
The data format is as follows:
6551700932705387022_!_101_!_news_culture_!_京城最值得你来场文化之旅的博物馆_!_保利集团,马未都,中国科学技术馆,博物馆,新中国
6552368441838272771_!_101_!_news_culture_!_发酵床的垫料种类有哪些?哪种更好?_!_
6552407965343678723_!_101_!_news_culture_!_上联:黄山黄河黄皮肤黄土高原。怎么对下联?_!_
6552332417753940238_!_101_!_news_culture_!_林徽因什么理由拒绝了徐志摩而选择梁思成为终身伴侣?_!_
6552475601595269390_!_101_!_news_culture_!_黄杨木是什么树?_!_Each row is a piece of data, separated by _!_ fields, from front to back are news ID, category code (see below), category name (see below), news string (title only), news keywords
Classification code and name:
100 民生 故事 news_story
101 文化 文化 news_culture
102 娱乐 娱乐 news_entertainment
103 体育 体育 news_sports
104 财经 财经 news_finance
106 房产 房产 news_house
107 汽车 汽车 news_car
108 教育 教育 news_edu
109 科技 科技 news_tech
110 军事 军事 news_military
112 旅游 旅游 news_travel
113 国际 国际 news_world
114 证券 股票 stock
115 农业 三农 news_agriculture
116 电竞 游戏 news_gamegithub address: https://github.com/fate233/toutiao-text-classfication-dataset
The experimental results for classification are given in the data resource:
Test Loss: 0.57, Test Acc: 83.81%
precision recall f1-score support
news_story 0.66 0.75 0.70 848
news_culture 0.57 0.83 0.68 1531
news_entertainment 0.86 0.86 0.86 8078
news_sports 0.94 0.91 0.92 7338
news_finance 0.59 0.67 0.63 1594
news_house 0.84 0.89 0.87 1478
news_car 0.92 0.90 0.91 6481
news_edu 0.71 0.86 0.77 1425
news_tech 0.85 0.84 0.85 6944
news_military 0.90 0.78 0.84 6174
news_travel 0.58 0.76 0.66 1287
news_world 0.72 0.69 0.70 3823
stock 0.00 0.00 0.00 53
news_agriculture 0.80 0.88 0.84 1701
news_game 0.92 0.87 0.89 6244
avg / total 0.85 0.84 0.84 54999
Let's use deeplearning4j to implement a convolutional structure to classify the dataset to see if we can get better results.
2. Reasons why convolutional networks can be used for text processing
CNN is very suitable for processing image data. The previous article "deeplearning4j - Convolutional Neural Network Recognition of Verification Codes" introduced CNN's recognition of verification codes. This blog will use CNN to classify text. Before we start, let's intuitively talk about what the essential thing the convolution operation is doing. The convolution operation can be regarded as the dot product of two vectors in essence. The more the two vectors are in the same direction, the larger the dot product. After relu and MaxPooling, the structure that is most in the same direction as the convolution kernel is essentially extracted. This "structure" is actually some lines on the picture.
So can text be processed with CNN? The answer is yes. After each word in the text is represented by a vector, it becomes a two-dimensional image when it is arranged in turn, as shown in the figure below. Looking in the direction of the red arrow (that is, the direction of the text), two sentences use one image. After the graph representation, the same unit will appear, which can be processed by CNN.
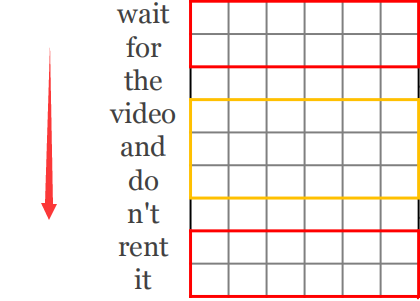
Third, the convolution structure of text processing
So, how to design this CNN network structure? As shown below: (paper address: https://arxiv.org/abs/1408.5882 )
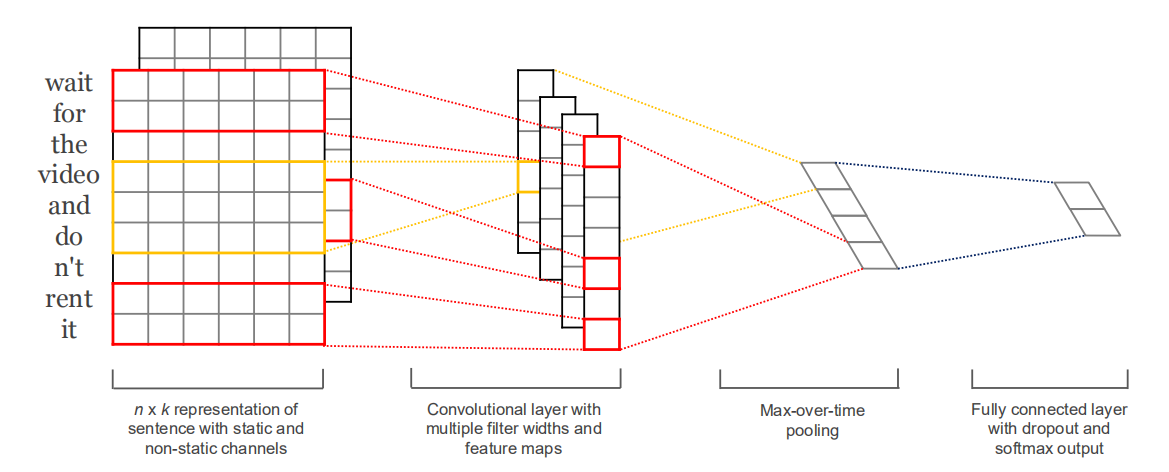
important point:
1. The direction in which the convolution kernel moves must be the direction of the sentence
2. The feature extracted by each convolution kernel is a vector of N rows and 1 column
3. The object of MaxPooling operation is each Feature Map, that is, select a maximum value from each vector of N rows and 1 column
4. Connect all the selected maximum values, go through several Fully Connected layers, and classify them
4. Data preprocessing and word vector
1. Word segmentation tool: HanLP
2. The data format after processing is as follows: (category code_!_ words, where words are separated by spaces, and _!_ is the separator)

The data preprocessing code is as follows:
public static void main(String[] args) throws Exception {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(
new FileInputStream(new File("/toutiao_cat_data/toutiao_cat_data.txt")), "UTF-8"));
OutputStreamWriter writerStream = new OutputStreamWriter(
new FileOutputStream("/toutiao_cat_data/toutiao_data_type_word.txt"), "UTF-8");
BufferedWriter writer = new BufferedWriter(writerStream);
String line = null;
long startTime = System.currentTimeMillis();
while ((line = bufferedReader.readLine()) != null) {
String[] array = line.split("_!_");
StringBuilder stringBuilder = new StringBuilder();
for (Term term : HanLP.segment(array[3])) {
if (stringBuilder.length() > 0) {
stringBuilder.append(" ");
}
stringBuilder.append(term.word.trim());
}
writer.write(Integer.parseInt(array[1].trim()) + "_!_" + stringBuilder.toString() + "\n");
}
writer.flush();
writer.close();
System.out.println(System.currentTimeMillis() - startTime);
bufferedReader.close();
}5. Vector representation of words
1、one-hot
Each word is represented by an orthogonal vector, which means that the relationship between words cannot be reflected. Then, in order to reuse the same convolution kernel in two sentences, the exact same word must appear. In fact, , we require that the model can draw inferences from one case, and even similar structures can be extracted, then word2vec can solve this problem.
2、word2vec
word2vec can fully consider the relationship between words. Similar words must have certain dimensions that are relatively close. Then the relationship between words and sentences is also considered. There are two types of word2vec training, skipgram and cbow. Next, we use cbow to train word vectors, and the result will persist, and we will get the toutiao.vec file, which will be changed next time. The file can be reloaded to obtain the vector representation of the word, the code is as follows:
String filePath = new ClassPathResource("toutiao_data_word.txt").getFile().getAbsolutePath();
SentenceIterator iter = new BasicLineIterator(filePath);
TokenizerFactory t = new DefaultTokenizerFactory();
t.setTokenPreProcessor(new CommonPreprocessor());
VocabCache<VocabWord> cache = new AbstractCache<>();
WeightLookupTable<VocabWord> table = new InMemoryLookupTable.Builder<VocabWord>().vectorLength(100)
.useAdaGrad(false).cache(cache).build();
log.info("Building model....");
Word2Vec vec = new Word2Vec.Builder()
.elementsLearningAlgorithm("org.deeplearning4j.models.embeddings.learning.impl.elements.CBOW")
.minWordFrequency(0).iterations(1).epochs(20).layerSize(100).seed(42).windowSize(8).iterate(iter)
.tokenizerFactory(t).lookupTable(table).vocabCache(cache).build();
vec.fit();
WordVectorSerializer.writeWord2VecModel(vec, "/toutiao_cat_data/toutiao.vec");6. CNN network structure
The CNN network structure is as follows:
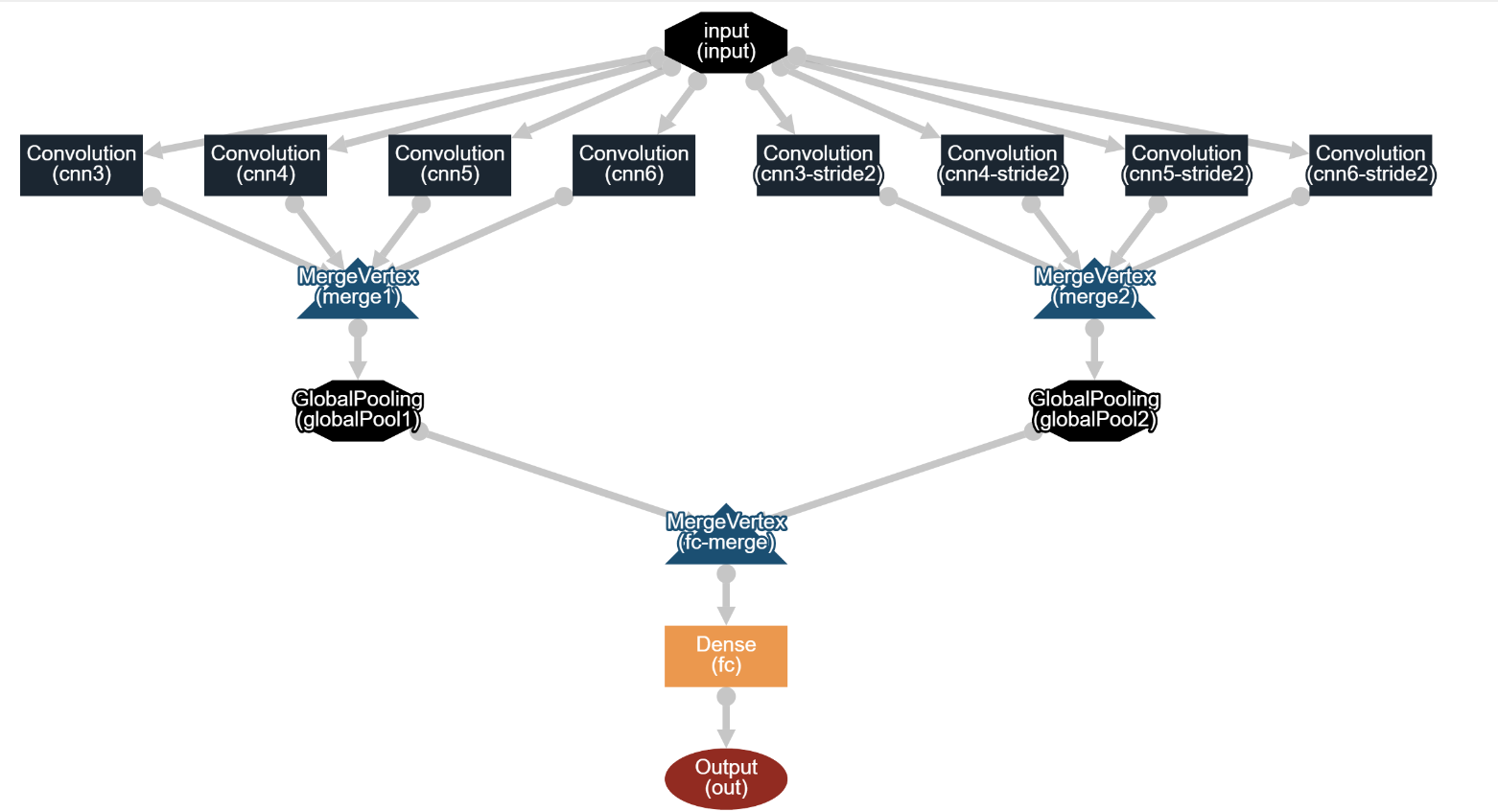
illustrate:
1. The convolution kernel sizes of cnn3, cnn4, cnn5, and cnn6 are (3, vectorSize), (4, vectorSize), (5, vectorSize), (6, vectorSize), and the stride is 1, that is, read 3, 4, 5, 6 words, extract features
2, cnn3-stride2, cnn4-stride2, cnn5-stride2, cnn6-stride2 convolution kernel size is (3, vectorSize), (4, vectorSize), (5, vectorSize), (6, vectorSize), the stride is 2
3. The results of the convolution of the two groups of convolution kernels are merged, and merge1 and merge2 are obtained respectively, which are 4-dimensional tensors with shapes (batchSize, depth1+depth2+depth3, height/1,1), (batchSize, depth1+) depth2+depth3, height/2,1), special note: the convolution mode here is ConvolutionMode.Same
4. Merge1 and 2 pass through MaxPooling respectively. The GlobalPoolingLayer is used here, which is different from the Pooling layer of the platform. Here, a maximum value will be taken from the specified dimension. Therefore, after the GlobalPoolingLayer, merge1 and 2 become 2-dimensional tensors respectively. The shape is (batchSize, depth1+depth2+depth3), so how does GlobalPoolingLayer find Max? The source code is as follows:
private INDArray activateHelperFullArray(INDArray inputArray, int[] poolDim) {
switch (poolingType) {
case MAX:
return inputArray.max(poolDim);
case AVG:
return inputArray.mean(poolDim);
case SUM:
return inputArray.sum(poolDim);
case PNORM:
//P norm: https://arxiv.org/pdf/1311.1780.pdf
//out = (1/N * sum( |in| ^ p) ) ^ (1/p)
int pnorm = layerConf().getPnorm();
INDArray abs = Transforms.abs(inputArray, true);
Transforms.pow(abs, pnorm, false);
INDArray pNorm = abs.sum(poolDim);
return Transforms.pow(pNorm, 1.0 / pnorm, false);
default:
throw new RuntimeException("Unknown or not supported pooling type: " + poolingType + " " + layerId());
}
}5. The results of the GlobalPoolingLayer on both sides are connected again, thrown to the fully connected network, and classified by the softmax classifier
6. For the fc layer, a dropout of 0.5 is used to prevent overfitting, as you can see in the code below.
The complete code is as follows:
public class CnnSentenceClassificationTouTiao {
public static void main(String[] args) throws Exception {
List<String> trainLabelList = new ArrayList<>();// 训练集label
List<String> trainSentences = new ArrayList<>();// 训练集文本集合
List<String> testLabelList = new ArrayList<>();// 测试集label
List<String> testSentences = new ArrayList<>();//// 测试集文本集合
Map<String, List<String>> map = new HashMap<>();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(
new FileInputStream(new File("/toutiao_cat_data/toutiao_data_type_word.txt")), "UTF-8"));
String line = null;
int truncateReviewsToLength = 0;
Random random = new Random(123);
while ((line = bufferedReader.readLine()) != null) {
String[] array = line.split("_!_");
if (map.get(array[0]) == null) {
map.put(array[0], new ArrayList<String>());
}
map.get(array[0]).add(array[1]);// 将样本中所有数据,按照类别归类
int length = array[1].split(" ").length;
if (length > truncateReviewsToLength) {
truncateReviewsToLength = length;// 求样本中,句子的最大长度
}
}
bufferedReader.close();
for (Map.Entry<String, List<String>> entry : map.entrySet()) {
for (String sentence : entry.getValue()) {
if (random.nextInt() % 5 == 0) {// 每个类别抽取20%作为test集
testLabelList.add(entry.getKey());
testSentences.add(sentence);
} else {
trainLabelList.add(entry.getKey());
trainSentences.add(sentence);
}
}
}
int batchSize = 64;
int vectorSize = 100;
int nEpochs = 10;
int cnnLayerFeatureMaps = 50;
PoolingType globalPoolingType = PoolingType.MAX;
Random rng = new Random(12345);
Nd4j.getMemoryManager().setAutoGcWindow(5000);
ComputationGraphConfiguration config = new NeuralNetConfiguration.Builder().weightInit(WeightInit.RELU)
.activation(Activation.LEAKYRELU).updater(new Nesterovs(0.01, 0.9))
.convolutionMode(ConvolutionMode.Same).l2(0.0001).graphBuilder().addInputs("input")
.addLayer("cnn3",
new ConvolutionLayer.Builder().kernelSize(3, vectorSize).stride(1, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn4",
new ConvolutionLayer.Builder().kernelSize(4, vectorSize).stride(1, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn5",
new ConvolutionLayer.Builder().kernelSize(5, vectorSize).stride(1, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn6",
new ConvolutionLayer.Builder().kernelSize(6, vectorSize).stride(1, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn3-stride2",
new ConvolutionLayer.Builder().kernelSize(3, vectorSize).stride(2, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn4-stride2",
new ConvolutionLayer.Builder().kernelSize(4, vectorSize).stride(2, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn5-stride2",
new ConvolutionLayer.Builder().kernelSize(5, vectorSize).stride(2, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addLayer("cnn6-stride2",
new ConvolutionLayer.Builder().kernelSize(6, vectorSize).stride(2, vectorSize)
.nOut(cnnLayerFeatureMaps).build(),
"input")
.addVertex("merge1", new MergeVertex(), "cnn3", "cnn4", "cnn5", "cnn6")
.addLayer("globalPool1", new GlobalPoolingLayer.Builder().poolingType(globalPoolingType).build(),
"merge1")
.addVertex("merge2", new MergeVertex(), "cnn3-stride2", "cnn4-stride2", "cnn5-stride2", "cnn6-stride2")
.addLayer("globalPool2", new GlobalPoolingLayer.Builder().poolingType(globalPoolingType).build(),
"merge2")
.addLayer("fc",
new DenseLayer.Builder().nOut(200).dropOut(0.5).activation(Activation.LEAKYRELU).build(),
"globalPool1", "globalPool2")
.addLayer("out",
new OutputLayer.Builder().lossFunction(LossFunctions.LossFunction.MCXENT)
.activation(Activation.SOFTMAX).nOut(15).build(),
"fc")
.setOutputs("out").setInputTypes(InputType.convolutional(truncateReviewsToLength, vectorSize, 1))
.build();
ComputationGraph net = new ComputationGraph(config);
net.init();
System.out.println(net.summary());
Word2Vec word2Vec = WordVectorSerializer.readWord2VecModel("/toutiao_cat_data/toutiao.vec");
System.out.println("Loading word vectors and creating DataSetIterators");
DataSetIterator trainIter = getDataSetIterator(word2Vec, batchSize, truncateReviewsToLength, trainLabelList,
trainSentences, rng);
DataSetIterator testIter = getDataSetIterator(word2Vec, batchSize, truncateReviewsToLength, testLabelList,
testSentences, rng);
UIServer uiServer = UIServer.getInstance();
StatsStorage statsStorage = new InMemoryStatsStorage();
uiServer.attach(statsStorage);
net.setListeners(new ScoreIterationListener(100), new StatsListener(statsStorage, 20),
new EvaluativeListener(testIter, 1, InvocationType.EPOCH_END));
// net.setListeners(new ScoreIterationListener(100),
// new EvaluativeListener(testIter, 1, InvocationType.EPOCH_END));
net.fit(trainIter, nEpochs);
}
private static DataSetIterator getDataSetIterator(WordVectors wordVectors, int minibatchSize, int maxSentenceLength,
List<String> lableList, List<String> sentences, Random rng) {
LabeledSentenceProvider sentenceProvider = new CollectionLabeledSentenceProvider(sentences, lableList, rng);
return new CnnSentenceDataSetIterator.Builder().sentenceProvider(sentenceProvider).wordVectors(wordVectors)
.minibatchSize(minibatchSize).maxSentenceLength(maxSentenceLength).useNormalizedWordVectors(false)
.build();
}
}
Code description:
1. The code is divided into two parts. The first part is data preprocessing. 20% of the test set and 80% of the training set are divided.
2. The second part is the basic structure code of the network
The network parameters are detailed as follows:
===============================================================================================================================================
VertexName (VertexType) nIn,nOut TotalParams ParamsShape Vertex Inputs
===============================================================================================================================================
input (InputVertex) -,- - - -
cnn3 (ConvolutionLayer) 1,50 15050 W:{50,1,3,100}, b:{1,50} [input]
cnn4 (ConvolutionLayer) 1,50 20050 W:{50,1,4,100}, b:{1,50} [input]
cnn5 (ConvolutionLayer) 1,50 25050 W:{50,1,5,100}, b:{1,50} [input]
cnn6 (ConvolutionLayer) 1,50 30050 W:{50,1,6,100}, b:{1,50} [input]
cnn3-stride2 (ConvolutionLayer) 1,50 15050 W:{50,1,3,100}, b:{1,50} [input]
cnn4-stride2 (ConvolutionLayer) 1,50 20050 W:{50,1,4,100}, b:{1,50} [input]
cnn5-stride2 (ConvolutionLayer) 1,50 25050 W:{50,1,5,100}, b:{1,50} [input]
cnn6-stride2 (ConvolutionLayer) 1,50 30050 W:{50,1,6,100}, b:{1,50} [input]
merge1 (MergeVertex) -,- - - [cnn3, cnn4, cnn5, cnn6]
merge2 (MergeVertex) -,- - - [cnn3-stride2, cnn4-stride2, cnn5-stride2, cnn6-stride2]
globalPool1 (GlobalPoolingLayer) -,- 0 - [merge1]
globalPool2 (GlobalPoolingLayer) -,- 0 - [merge2]
fc-merge (MergeVertex) -,- - - [globalPool1, globalPool2]
fc (DenseLayer) 400,200 80200 W:{400,200}, b:{1,200} [fc-merge]
out (OutputLayer) 200,15 3015 W:{200,15}, b:{1,15} [fc]
-----------------------------------------------------------------------------------------------------------------------------------------------
Total Parameters: 263615
Trainable Parameters: 263615
Frozen Parameters: 0
===============================================================================================================================================
The UIServer interface of DL4J is as follows. The port number I have given here is 9001. Open the web interface to see the details of the average loss, the details of the gradient update, etc.
http://localhost:9001/train/overview
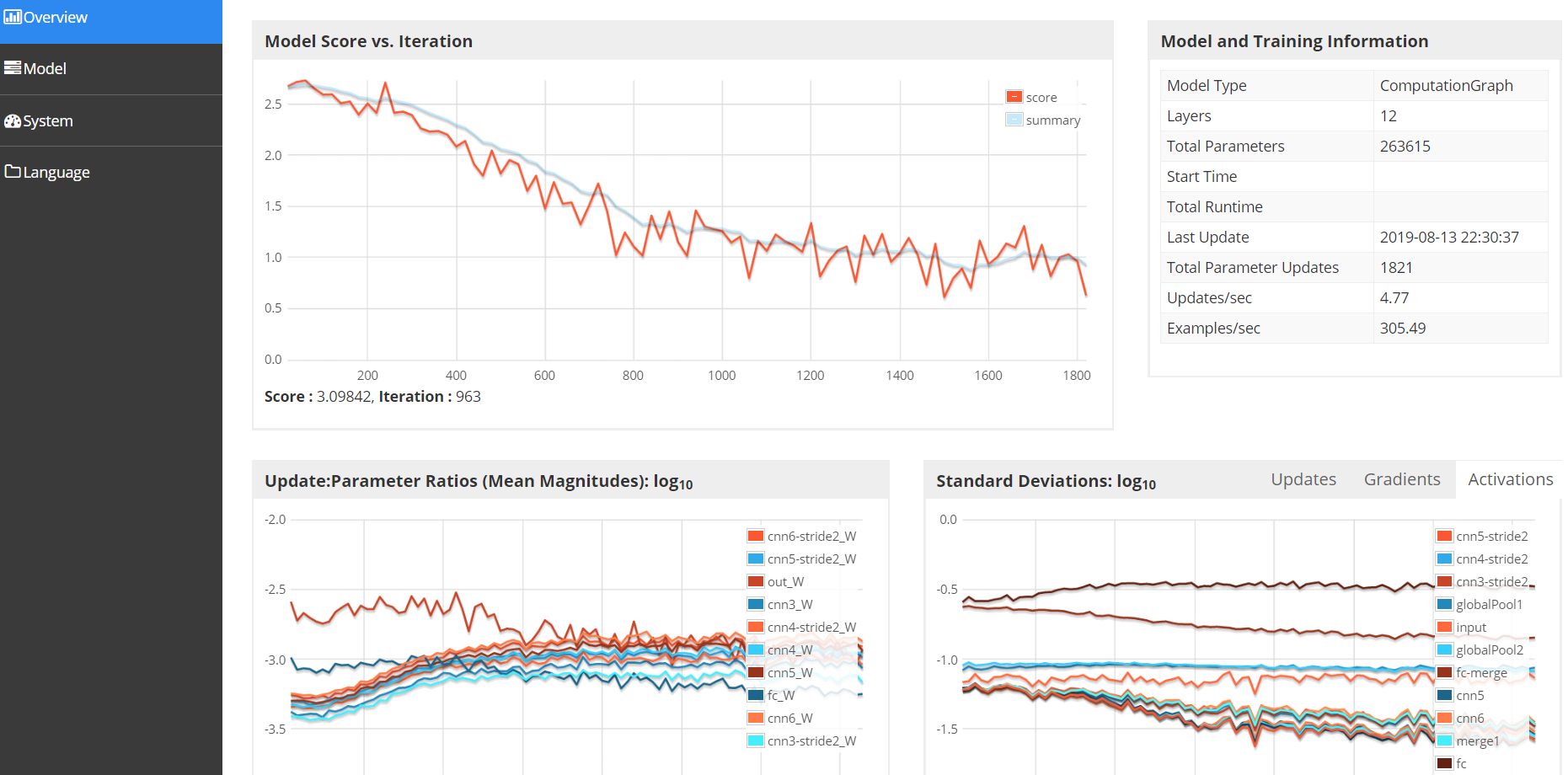
7. Mask
Sentences are long or short, how will CNN handle them?
The processing method is actually very violent. Find the longest sentence in a minibatch, create a new tensor with the maximum length, and mask the excess value with a mask. Not much nonsense, just go to the code
if(sentencesAlongHeight){
featuresMask = Nd4j.create(currMinibatchSize, 1, maxLength, 1);
for (int i = 0; i < currMinibatchSize; i++) {
int sentenceLength = tokenizedSentences.get(i).getFirst().size();
if (sentenceLength >= maxLength) {
featuresMask.slice(i).assign(1.0);
} else {
featuresMask.get(NDArrayIndex.point(i), NDArrayIndex.point(0), NDArrayIndex.interval(0, sentenceLength), NDArrayIndex.point(0)).assign(1.0);
}
}
} else {
featuresMask = Nd4j.create(currMinibatchSize, 1, 1, maxLength);
for (int i = 0; i < currMinibatchSize; i++) {
int sentenceLength = tokenizedSentences.get(i).getFirst().size();
if (sentenceLength >= maxLength) {
featuresMask.slice(i).assign(1.0);
} else {
featuresMask.get(NDArrayIndex.point(i), NDArrayIndex.point(0), NDArrayIndex.point(0), NDArrayIndex.interval(0, sentenceLength)).assign(1.0);
}
}
}Why is there an if here? When generating a sentence tensor, the direction of the sentence can be arbitrarily specified, which can be along the direction of the height in the matrix, or the direction of the width. The direction of the mask is different, and the dimension of the mask is also different.
8. Results
After running 10 Epochs, the results are as follows:
========================Evaluation Metrics========================
# of classes: 15
Accuracy: 0.8420
Precision: 0.8362 (1 class excluded from average)
Recall: 0.7783
F1 Score: 0.8346 (1 class excluded from average)
Precision, recall & F1: macro-averaged (equally weighted avg. of 15 classes)
Warning: 1 class was never predicted by the model and was excluded from average precision
Classes excluded from average precision: [12]
=========================Confusion Matrix=========================
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
----------------------------------------------------------------------------
973 35 114 2 9 8 11 19 14 6 19 11 0 22 13 | 0 = 0
17 4636 250 37 51 16 14 151 47 29 232 36 0 82 44 | 1 = 1
103 176 6980 108 16 8 31 62 83 41 53 77 0 36 163 | 2 = 2
9 78 244 6692 37 9 52 59 33 27 57 54 0 10 96 | 3 = 3
7 52 36 31 4072 96 101 107 581 20 64 108 0 135 37 | 4 = 4
12 18 22 8 150 3061 27 36 53 2 100 16 0 56 2 | 5 = 5
17 38 71 26 94 13 6443 43 174 31 121 39 0 32 34 | 6 = 6
17 157 93 49 62 20 34 4793 85 14 58 36 0 49 31 | 7 = 7
1 45 71 21 436 30 195 138 7018 48 54 49 0 45 148 | 8 = 8
24 74 84 47 24 1 57 50 68 3963 45 431 0 9 65 | 9 = 9
9 165 90 21 40 37 61 40 42 21 3428 111 0 78 30 | 10 = 10
47 78 173 52 114 20 48 67 93 320 140 4097 0 48 29 | 11 = 11
0 0 0 0 60 0 1 0 5 0 0 0 0 0 0 | 12 = 12
35 105 31 6 139 37 34 61 79 11 153 35 0 3187 12 | 13 = 13
14 36 210 128 31 2 19 20 164 44 38 15 0 19 5183 | 14 = 14The average accuracy rate is 0.8420, which is slightly better than the results given in the original resource, and the F1 score is slightly worse. In the confusion matrix, there is a category that cannot be predicted, because the amount of changed category data in the sample itself is very small and difficult to catch. Common features. If the parameters here are carefully adjusted and iterate more times, theoretically, there will be better performance.
9. Postscript
Reading Deeplearning4j is a pleasure, elegant architecture, clear logic, multiple design patterns, and strong scalability. There will be follow-up blogs to analyze the dl4j source code.
Happiness comes from sharing.
This blog is original by the author, please indicate the source for reprinting