Author: Ma Jingwei
Edit: Dadong BE
Guided reading
The HTAP database that integrates TP and AP is becoming a development trend in the industry. However, due to the complexity of the TP and AP systems themselves in large-scale data scenarios, it is not easy to integrate the functions of the two usage scenarios in one database system. The HTAP database ZNBase launched by Inspur adopts the multi-mode storage engine solution to realize the HTAP feature, and introduces the column storage engine on the basis of OLTP to support the OLAP scenario. This article will focus on the important role of the column storage engine technology in the HTAP database ZNBase.
OLTP 与 OLAP
noun definitionOLTP, the full name of On-Line Transaction Processing, translates to online transaction processingOLAP, the full name of On-Line Analytical Processing, translates to online analytical processing
Computer systems have been used since the 1960s to perform tasks in areas such as payroll, accounting, and billing. At that time, the user entered data, and the computer system processed the data to complete a series of additions, deletions, changes, and search operations, which was the early OLTP. With the further development of computer technology and database technology, OLTP has been widely used in government, bank and enterprise information systems. Today, OLTP is considered a low-latency, high-volume, high-concurrency workload typically used to conduct business, such as taking and fulfilling orders, making shipments, billing customers, collecting payments, and other transactions.
OLAP, on the other hand, is considered an analytical workload. The scenarios faced by OLAP are relatively high latency, low volume and low concurrent workloads, which are often used to improve company performance by analyzing operational, historical and big data, making strategic decisions or taking action to improve Product quality, improving customer experience, making market forecasts, etc. With the rise of big data technology in recent years, enterprises have higher requirements on the timeliness of data analysis scenarios, and OLAP under large-scale data has also become a rigid demand for many enterprises.
After the explosion of Internet traffic, in the face of massive data, the information architecture and infrastructure of OLTP and OLAP systems are different, and at the same time have their own complexity, so these two application scenarios have different products to meet the needs of users. need. During this period, enterprises usually adopted the combination scheme of "transactional database system + analytical database system + ETL tool" to realize the business requirements of large-scale data storage transaction + analysis.
Emergence of HTAP
This solution of using different systems to process data for different scenarios also brings corresponding difficulties. Because the TP and AP is cross-platform, so with the use of the process there will be data transmission, which brings two challenges: data synchronization, data redundancy .
The core of data synchronization is the issue of data timeliness, and expired data often loses value. In the past, the data changes in the OLTP system were exposed in the form of logs; the transmission was decoupled through the message queue; the back-end ETL consumption was pulled, and the data was synchronized to the OLAP to form a TP-AP data transmission chain . Since the entire chain is long, this poses a test for scenarios with high timeliness requirements.
On the other hand, data flows in the chain, and multiple copies of data are stored redundantly. In a conventional high-availability environment, the data will be further saved in multiple copies. Therefore, it brings greater technology, labor costs, and data synchronization costs. At the same time, it spans so many technology stacks and database products, and each technology stack needs a separate team to support and maintain, such as DBA, big data, infrastructure, etc., which bring huge manpower, technology, time, operation dimension cost.
In 2014, Gartner proposed a new database model HTAP with hybrid transaction/analytical processing, aiming to break the gap between OLTP and OLAP systems and integrate the two into one database system to avoid the high cost of ETL cross-platform data transmission. cost.
With the continuous development of software and hardware infrastructure and database technology, the trend of gradually replacing the traditional "transactional database system + analytical database system + ETL tool" solution by HTAP database systems that take into account both OLTP and OLAP loads has taken shape.
ZNBase and column storage engine
ZNBase is an HTAP distributed database recently open sourced by Inspur, and it is also the first domestic database project to be accepted by the Open Atomic Open Source Foundation. The database system was developed to cope with the increasing number of mixed load scenarios. It can mix transaction and analysis scenarios, and is suitable for more data application requirements. In order to realize the characteristics of HTAP, the column storage engine subsystem in the database system plays an important role in the whole system architecture.
The HTAP function of ZNBase is supported by a multi-mode storage engine. In the processing of structured data, the storage can be divided into row storage and column storage, which are optimized for OLTP and OLAP scenarios respectively, and the column storage engine supports OLAP scenarios. .
The column storage engine is the core component of the HTAP form of the ZNBase database system. It is used to store and manage the column storage copy of data. It is an extension of the row storage engine. The column storage engine provides good isolation and also takes into account the strong read consistency. . The column-stored copy is asynchronously replicated through the Raft Learner protocol, but the synchronization between the Learner and the Leader is achieved through the Raft proofreading index method during reading. This architecture solves the problem of isolation and column-store synchronization in HTAP scenarios well.
Column Storage Engine Architecture Introduction
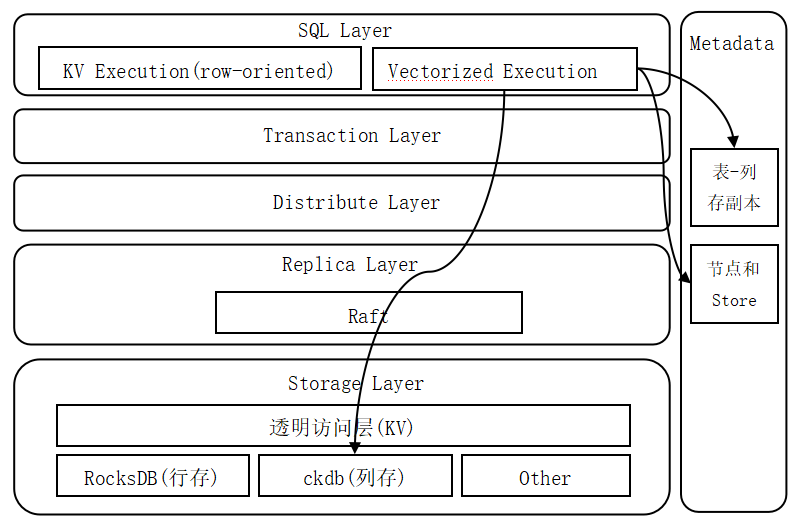
The logical architecture of the column storage engine consists of four parts:
1) DDL module;
2) SQL layer vector calculation module;
3) Copy layer Raft protocol module;
4) Transparent access module and column storage database module of storage layer.
- The DDL module is responsible for managing the column-stored copy of the table, and it drives the metadata module, the Raft protocol module and the column-store database model to work together.
- The vector calculation module is responsible for reading data from the column-store copy and performing vector calculations. It reads the metadata module, reads the data from the appropriate column-store copy, completes the calculation and returns the result.
- The Raft protocol module is responsible for dealing with row-column replica consistency.
- The transparent access module is responsible for providing a unified storage access interface for the upper layer, shielding the differences of the lower layer heterogeneous storage engines, and realizing the decoupling of the upper layer and the storage engine; the column storage database is the bottom storage component of the column storage engine, and is responsible for the actual storage in the column storage format. Column store replica data.
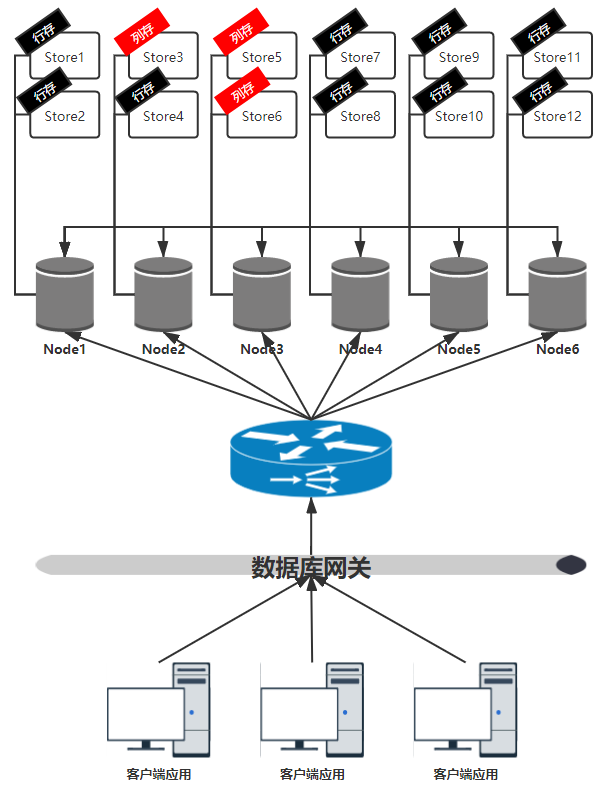
The physical architecture of the column storage engine is divided into three layers:
1) Application layer: including all client applications that call database services;
2) Gateway layer: The database gateway is responsible for improving the overall execution performance of the cluster by optimizing SQL routing. The database cluster adopts a full peer-to-peer network topology. Any node instance in the cluster can process SQL. The database gateway optimizes SQL routing according to the node instance load and data distribution, and sends SQL to more appropriate node instances, such as pure OLAP loads are sent to a group of column storage nodes.
3) Cluster layer: The cluster consists of multiple node instances with the same roles and functions. The instance node that receives SQL temporarily acts as the Master role, and is responsible for driving the SQL execution process, interacting with other node instances, and returning calculation results. Each node instance can have multiple stores, and each store can be marked as a different type. Currently, it can be marked as row-stored store or column-stored store. The bottom layer of the column store store uses a column store database, which can only store column store copies. If all stores owned by a node instance are column storage, it becomes a column storage node instance. From the perspective of resource isolation, all column storage node instances can be formed into a virtual OLAP database cluster, which is specially responsible for handling OLAP load without causing excessive impact on other row storage node instances.
Features of the column storage engine
The column storage engine has several major features, vector computing, computing pushdown, columnar storage and asynchronous replication.

In terms of specific implementation, the column storage engine adopts Clickhouse and performs absorption optimization on its basis. ClickHouse itself is an efficient columnar storage engine, and implements rich functions such as data ordered storage, primary key index, sparse index, data sharding, data partitioning, and TTL.
Summarize
As a new type of HTAP distributed database system, ZNBase can satisfy transaction and analysis scenarios at the same time, avoiding cumbersome and expensive ETL operations. The column storage engine technology plays an important role in this.
As a key technology for implementing HTAP, the column storage engine can achieve a quasi-real-time effect of analysis scenarios on the basis of ensuring transaction processing performance, meet user needs, and optimize user experience. The column storage engine is rooted in the ZNBase database and inherits its powerful product features, enabling it to enhance the processing capabilities of OLAP scenarios and enrich product functions based on the original high-performance OLTP capabilities.
For most database users, the best product experience is out-of-the-box. Whether it is a TP or an AP scenario, if all operations can be completed in the same black-box system, it can reduce the user's mental burden and operation and maintenance costs. So it is not difficult to understand why the unified TP and AP processing HTAP database can become a product trend sought after by the market and users.
More details about ZNBase can be found at:
Official code repository: https://gitee.com/ZNBase/zn-kvs
ZNBase official website: http://www.znbase.com/
If you have any questions about related technologies or products, please submit an issue or leave a message in the community for discussion. At the same time, developers who are interested in distributed databases are welcome to participate in the construction of the ZNBase project.