The story starts many years ago.
You must have heard the statement that a single table in a database recommends a maximum of 2kw of data. If it exceeds, the performance will drop more severely.
Coincidentally.
I've heard of it too.
But I don't accept its suggestion, it just loads 100 million pieces of data in a single table.
At this time, after the new interns in our group saw it, they asked me innocently: "Isn't it recommended that a single table be at most 20 million? Why is this table 100 million and it is not divided into databases and tables ?"
Can I say I'm lazy ? How did I think that this watch could rise so fast when I designed it. . .
I can not.
To say that is to admit that I am a cancer in the development team , although I am, but I cannot admit it .
I feel like sitting on pins and needles, like a thorn in my back, like a sting in my throat.
A flurry of action started.
"I did it for a reason"
"Although this table is very large, have you noticed that its query is actually very fast"
"This 2kw is a suggested value, we have to see how this 2kw came from"
What is the maximum number of rows in a single table in a database?
Let's first look at the theoretical maximum number of rows in a single table.
The SQL for creating the table is written like this,
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '名字',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=100037 DEFAULT CHARSET=utf8;
where id is the primary key. The primary key itself is unique, which means that the size of the primary key can limit the upper limit of the table.
If the primary key is declared as the intsize, that is, 32 bits, then it can support 2^32-1, which is about 2.1 billion .
If it is bigint, it is 2^64-1, but this number is too large . Generally, the disk can't stand it before this limit is reached .
Get outrageous.
If I declare the primary key as tinyint, one byte, 8 bits, max 2^8-1, that is 255.
CREATE TABLE `user` (
`id` tinyint(2) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '名字',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
If I want to insert a data with id=256, it will give an error .
mysql> INSERT INTO `tmp` (`id`, `name`, `age`) VALUES (256, '', 60);
ERROR 1264 (22003): Out of range value for column 'id' at row 1
That is to say, tinyintthe primary key limits a maximum of 255 pieces of data in the table.
In addition to the primary key, what other factors will affect the number of rows?
index structure
The B+ tree is used inside the index. This is also an old stock of Baguwen, and everyone is probably familiar with it.
In order not to let everyone have too much fatigue of judging ugly, today I try to tell you about this thing from another angle.
page structure
Suppose we have such a user data table.
user table
where id is the unique primary key .
This looks like line by line data, for convenience, we will call them record later .
This table looks like an excel sheet. The data of excel is a xx.excel file on the hard disk.
The above user table data is actually similar on the hard disk, and is placed under the user.ibd file. The meaning is the innodb data file of the user table, professional point, also called table space .
Although in the datasheet, they appear to be next to each other. But actually in user.ibd they are divided into many small data pages , each 16k in size.
Similar to the following.
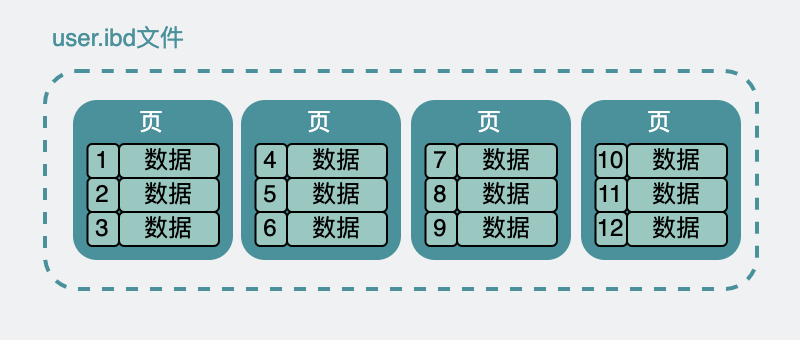
There are a lot of pages inside the ibd file
Let's focus the perspective and put it on the page.
The whole page 16kis not big, but there are so many records that it cannot fit on one page, so it will be divided into many pages. And this 16k can't be used for all records, right?
Because the records are divided into many parts and placed in many pages, in order to uniquely identify which page it is, it is necessary to introduce the page number (in fact, the address offset of a table space). At the same time, in order to associate these data pages, the front and rear pointers are introduced to point to the front and rear pages. These are added to the header .
The page needs to be read and written. 16k is not too small. It is possible that the power cord is pulled out in half of the writing. Therefore, in order to ensure the correctness of the data page, a check code is also introduced. This is added to the footer .
The remaining space is used to put our records. And if the number of lines in record is too large, it is not very efficient to traverse one by one when entering the page, so a page directory is generated for these data , and the specific implementation details are not important. Just know that it can change the search efficiency from O(n) to O(lgn) by means of binary search .
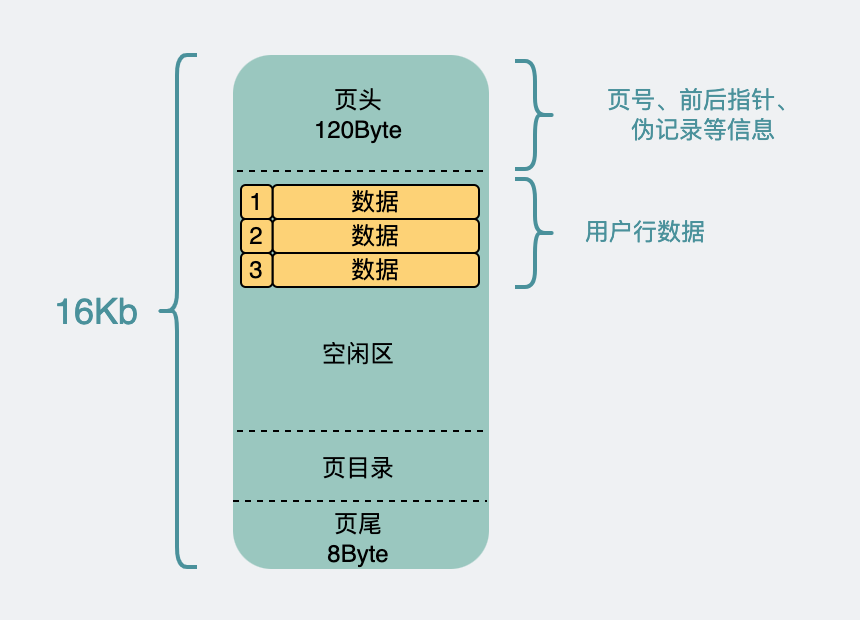
page structure
From page to index
If we want to check a record, we can fish out every page in the tablespace, and then fish out the records in it one by one to determine whether we are looking for it.
When the number of rows is small, this operation is not a problem.
The larger the number of rows, the slower the performance , so in order to speed up the search, we can select the record with the smallest primary key id in each data page , and only need their primary key id and the page number of the page where they are located . Form a new record and put it into a newly generated data page. This new data page is no different from the previous page structure, and the size is still 16k.
But in order to distinguish it from the previous data page. The page level (page level) information is added to the data page , starting from 0 and counting upwards. So there is a concept of upper and lower levels between pages , like the following.
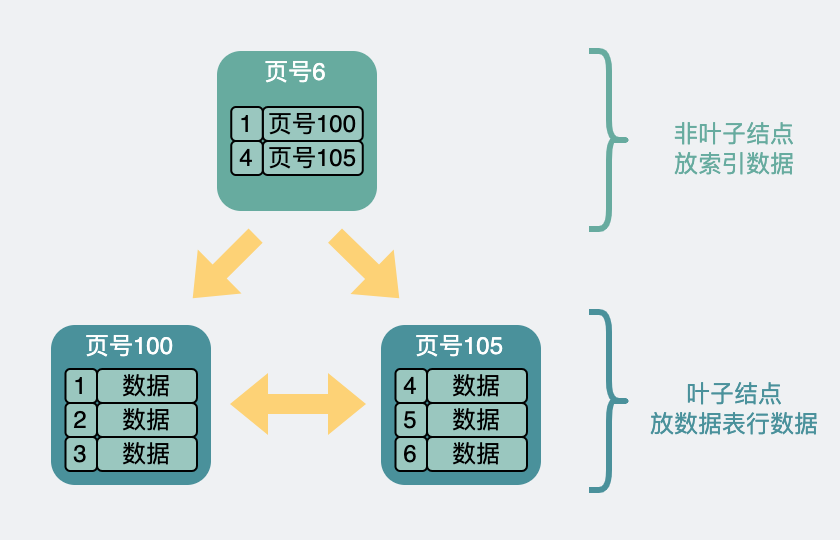
Two-level B+ tree structure
Suddenly it looks like an upside-down tree between pages. That is, we often say B+ tree index.
In the bottom layer, the page level is 0 , which is the so-called leaf node , and the rest are called non-leaf nodes .
The above shows a two-layer tree. If there is more data, we can also build one layer up through a similar method. It's a three-story tree.
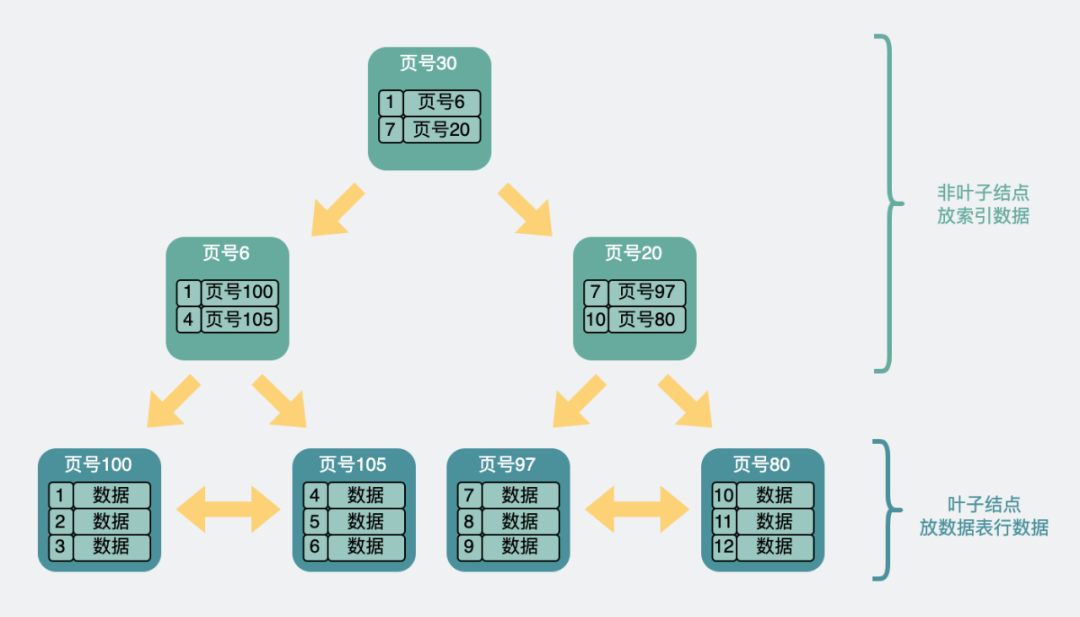
Three-layer B+ tree structure
Now we can speed up the query through such a B+ tree. for example.
Let's say we want to find row data 5. It will start with the records on the top page. The record contains the primary key id and page number (page address) . Look at the yellow arrow in the figure below, the minimum id to the left is 1, and the minimum id to the right is 7. If the data with id=5 exists, it must be on the left arrow. So follow the page address of the record to the 6号data page, and then judge that id=5>4, so it must be in the data page on the right, so load the 105号data page. Find the data row with id=5 in the data page and complete the query.
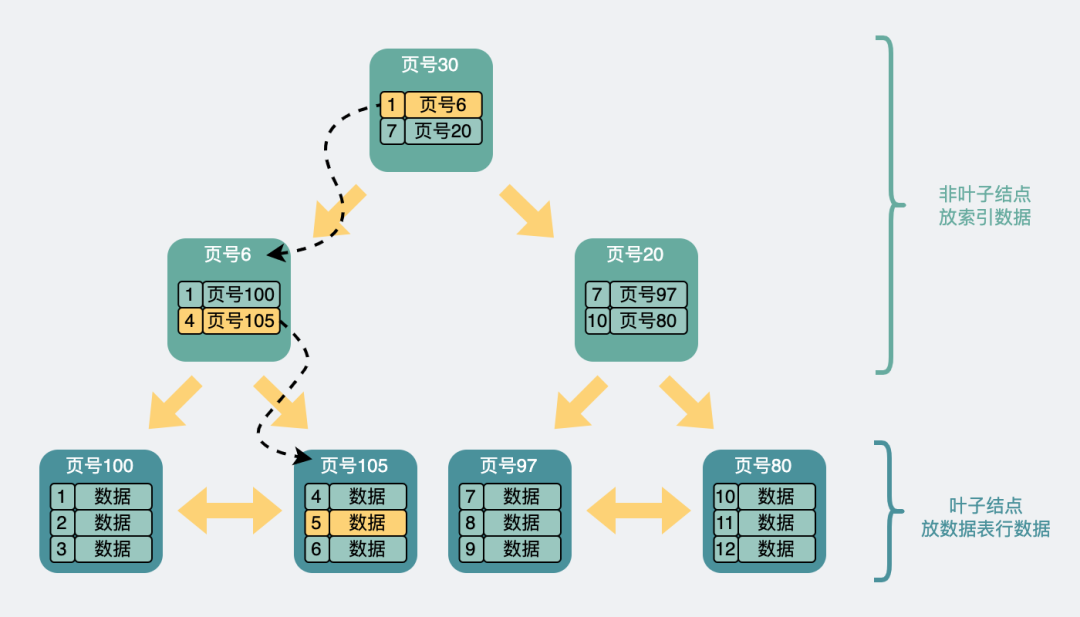
B+ tree query process
Another thing to note is that the page numbers of the above pages are not consecutive, and they are not necessarily next to each other on disk.
In this process, three pages are queried. If these three pages are all on disk (not loaded into memory in advance), it takes up to three disk IO queries before they can be loaded into memory.
The number of records carried by the B+ tree
From the above structure, it can be seen that record data is placed in the last-level leaf node of the B+ tree . The index data used to speed up the query is placed in the non- leaf node .
That is to say
For the same 16k page, each piece of data in the non-leaf node points to a new page, and the new page has two possibilities.
-
If it is the last-level leaf node, then there are rows of record data in it.
-
If it is a non-leaf node, the loop will continue to point to new data pages.
Assumption
-
The number of pointers to other memory pages in the non-leaf node is
x -
The number of records that can be accommodated in a leaf node is
y -
The number of levels of the B+ tree is
z
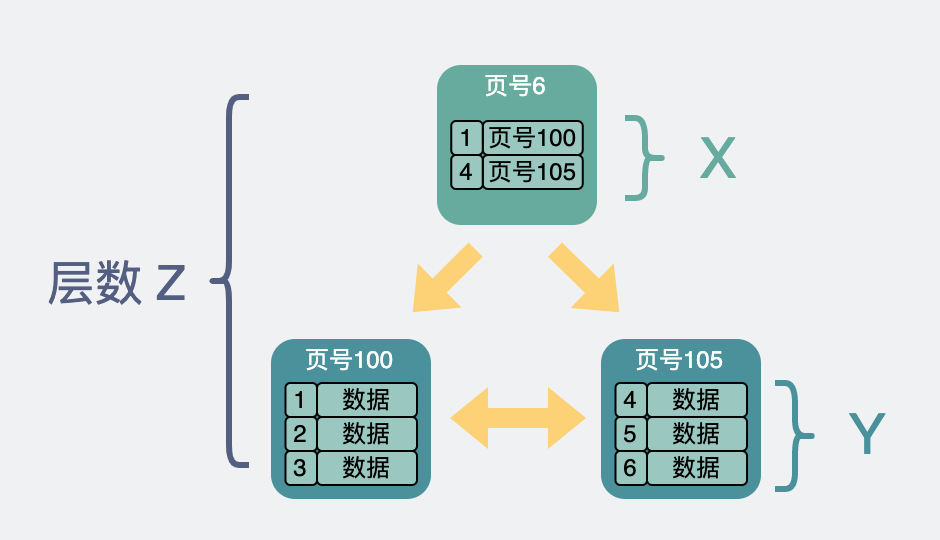
How to calculate the total number of rows
Then the total amount of row data in this B+ tree is equal to (x ^ (z-1)) * y.
how to calculate x
Let's go back and look at the structure of the data page.
page structure
In the non-leaf nodes, the data related to the index query is mainly placed, and the primary key and the pointing page number are placed.
The primary key is assumed to be bigint(8Byte), and the page number is called in the source code FIL_PAGE_OFFSET(4Byte), then a piece of data in the non-leaf node is 12Byteleft and right.
The entire data page 16k, the part of the data at the beginning and end of the page is roughly added up 128Byte, plus the page directory gross estimate 1k. The remaining 15k divided by 12Byte, is equal to 1280, that is, can point to x=1280 pages .
The binary tree we often say refers to a node that can radiate two new nodes. A node in an m-ary tree can point to m new nodes. This operation of pointing to a new node is called fanout .
The B+ tree above, which can point to 1280 new nodes, is so terrifying, it can be said that the fan-out is very high .
y calculation
The data structure of leaf nodes and non-leaf nodes is the same, so it is also assumed that the rest 15kbcan be played.
The real row data is placed in the leaf node. Assume one row of data 1kb, so y=15 rows can be placed on one page .
row total count
Back to (x ^ (z-1)) * y this formula.
known x=1280, y=15.
Assuming the B+ tree is two levels , that z=2. is(1280 ^ (2-1)) * 15 ≈ 2w
Assuming that the B+ tree is three levels , that z=3. is(1280 ^ (3-1)) * 15 ≈ 2.5kw
**This 2.5kw is the origin of the recommended maximum number of rows for a single table that we often say is 2kw. **After all, add another layer, and the data is a bit outrageous. The three-tier data page corresponds to a maximum of three disk IOs, which is also reasonable.
Is it slow when the number of lines exceeds 100 million?
The above assumes that a single row of data uses 1kb, so a data page can hold 15 rows of data.
If I can't use so much for a single row of data, for example, only use it 250byte. Then a single data page can hold 60 rows of data.
It is also a three-level B+ tree, and the number of rows supported by a single table is (1280 ^ (3-1)) * 60 ≈ 1个亿.
Look at my 100 million data, which is actually a three-layer B+ tree. To find a row of data in this B+ tree, it takes up to three disk IOs. So it's not slow.
This is a good explanation for the beginning of the article, why I have a single table of 100 million, but the query performance is not a big problem.
The number of records carried by the B-tree
Now that we've talked about it here, let's talk a little more along this topic.
We all know that the indexes of MySQL are all B+ trees now, and there is a kind of tree, which is very similar to the B+ tree, called the B tree, also called the B-tree .
The biggest difference between it and the B+ tree is that the B+ tree only puts data table row data at the last-level leaf node, while the B tree puts it on both leaf and non-leaf nodes.
Therefore, the structure of the B-tree is similar to this
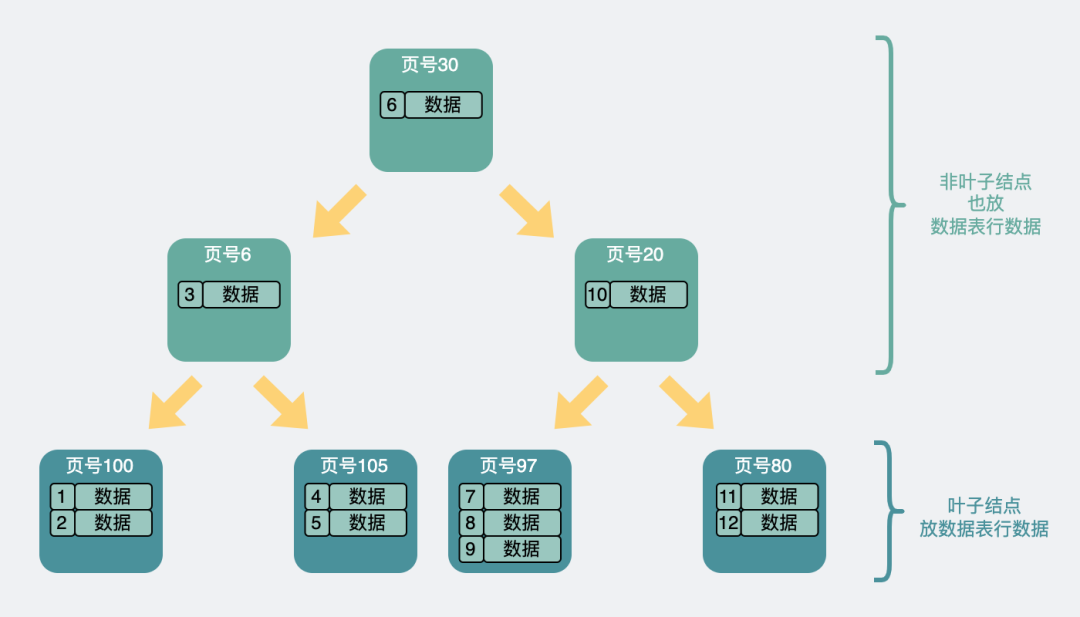
B-tree structure
The B-tree stores all row data on non-leaf nodes. Assuming that each data page is still 16kb, each page is left with 15kb, and a data table row data still occupies 1kb, even if the various page pointers are not considered, Only 15 pieces of data can be placed. The data page fanout is significantly reduced.
The formula for calculating the total number of rows that can be carried also becomes a proportional series .
15 + 15^2 +15^3 + ... + 15^z
Among them, z also means the number of layers.
It is necessary to be able to put 2kwleft and right data z>=6. That is, the tree needs to have 6 layers, and 6 pages are accessed at a time. Assuming that these 6 pages are not consecutive, in order to query one of the data, the worst case requires 6 disk IOs .
In the same case, the B+ tree puts about 2kw of data, and one check is at most 3 times of disk IO.
The more disk IO, the slower it is, and the performance gap between the two is slightly larger.
For this reason, B+ trees are more suitable for mysql indexes than B trees.
Summarize
-
The data pages of the leaf and non-leaf nodes of the B+ tree are both 16k, and the data structure is the same. The difference is that the leaf nodes place the real row data, while the non-leaf nodes place the primary key and the address of the next page.
-
The B+ tree generally has two to three layers. Due to its high fan-out, three layers can support data of more than 2kw, and a query can perform up to 1 to 3 disk IOs at a time, and the performance is also good.
-
To store the same amount of data, the B-tree has a higher level than the B+ tree, so there are more disk IOs, so the B+ tree is more suitable for becoming a MySQL index.
-
The index structure does not affect the maximum number of rows in a single table, and 2kw is only a recommended value. Exceeding this value may lead to a higher B+ tree level and affect query performance.
-
The single table maximum is also limited by the primary key size and disk size.
References
"MYSQL Kernel: INNODB Storage Engine Volume 1"
At last
Although I stuffed 100 million pieces of data in a single table, the premise of this operation is that I know very well that this will not affect performance too much.
This wave of explanations is flawless and impeccable.
At this point, even I was convinced by myself. Presumably so are the interns.
Damn, this damn cancer is actually somewhat "knowledgeable".

Recently, the reading volume of original updates has steadily declined, and after thinking about it, I tossed and turned at night.
I have an immature request.

It's been a long time since I left Guangdong, and no one called me Pretty Boy for a long time.
Can you call me a pretty boy in the comment area ?
Can such a kind and simple wish of mine be fulfilled?
If you really can't speak out, can you help me click the like and watch in the lower right corner ?
Stop talking, let's choke in the ocean of knowledge together
Click on the business card below to follow the official account: [Xiaobai debug]

Xiaobai debug
Promise me, after paying attention, learn techniques well, don't just collect my emojis. .
31 original content
No public
Not satisfied with talking shit in the message area?
Add me, we have set up a group of paddling and bragging. In the group, you can chat about interesting topics with colleagues or interviewers you may encounter next time you change jobs. Just super! open! Heart!