Abstract : Meteorological data is a typical type of big data, which has the characteristics of large data volume, high timeliness, and rich data types. The amount of data generated every day is often in the scale of tens of terabytes to hundreds of terabytes, and it is growing explosively. How to store and efficiently query these meteorological data has become more and more difficult. In this paper, aiming at the storage and query of massive pattern data in the meteorological field, this paper introduces the traditional scheme and the scheme using TableStore respectively, and discusses the advantages and disadvantages of the scheme. Some summaries are made.
foreword
Meteorological data is a typical type of big data, which has the characteristics of large data volume, high timeliness, and rich data types. A large amount of data in meteorological data is spatiotemporal data, which records the observed or simulated quantities of various physical quantities at various points in time and space. increase. How to store and efficiently query these meteorological data has become more and more difficult.
Traditional solutions often use relational databases and file systems to store and query such meteorological data in real time. This solution has some shortcomings in scalability, maintainability and performance. With the increase of data scale The shortcomings are becoming more and more obvious. In recent years, academia and industry have begun to use distributed NoSQL storage to solve the storage and real-time query of massive meteorological data. Compared with the previous solution, it can support a larger amount of data and provide better query performance. And in terms of stability, manageability, etc., it has also been significantly improved.
On the other hand, the use of cloud computing resources to solve the analysis, storage, query and analysis of meteorological big data has also become a trend and direction. There are abundant products and services and flexible computing resources on the cloud, and a complete set of meteorological data processing workflows can be completed on the cloud: use the distributed storage on the cloud to store and query meteorological data in real time, and use big data computing services for meteorological data. Data analysis and processing, using various application services to build meteorological platforms and applications.
Therefore, today, more and more researchers in the field of meteorology, as well as researchers in the fields of ocean and earthquake, are beginning to understand cloud computing, understand distributed storage, and think about how to store and query massive meteorological data based on these services. design. Based on the exploration of TableStore (formerly OTS) solutions in the field of meteorology, this article will introduce how to use TableStore to solve the storage and real-time query problems of massive meteorological data.
Characteristics and query methods of meteorological data
This chapter will introduce the characteristics of meteorological data (mainly pattern data), as well as several query methods, and thus lead to what problems we need to solve in order to realize the storage and real-time query of massive meteorological data.
schema data
A very important part of meteorological data is model data, which is used for numerical model forecasting. Model data is calculated by high-performance computers through physical equations based on real-time observation data from sensors on the ground, high-altitude, and satellites. The system that generates model data is a huge set of computing systems. own model system.
The model system will calculate several times a day, and each time generate a series of longitude and latitude grid forecast data of hundreds of physical quantities at different altitudes in the future (such as 240 hours), each point on the grid represents this altitude, this longitude and latitude The forecast value of a physical quantity at a certain time in the future.
Schema data is multidimensional
Pattern data has obvious multi-dimensional characteristics. Taking the data generated by the pattern system each time as an example, it includes the following five dimensions:
Physical quantities, or elements: temperature, humidity, wind direction, wind speed, etc.
Forecast aging: the next 3 hours, 6 hours, 9 hours, 72 hours, etc.
high.
longitude.
latitude.
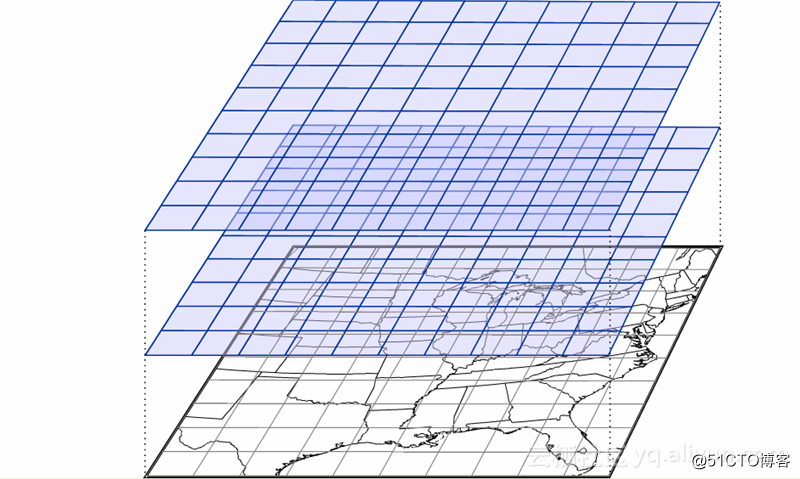
When we fix a certain element and a certain forecast time, then the altitude, longitude, and latitude constitute a three-dimensional grid data, as shown in the following figure (the picture is from the Internet). Each grid point represents a point in a three-dimensional space, and the value above is the predicted value of a physical quantity (such as temperature) at a certain forecast period (such as the next three hours) at the point.
Suppose a three-dimensional grid point space contains 10 planes of different heights, each plane is a 2880 x 570 grid point, and each grid point stores a 4-byte data, then the three-dimensional data volume is 2880 x 570 x 4 x 10, about 64MB. This is only a prediction of a certain physical quantity under a certain time period by a certain model system, and the total amount of visible model data is very large.
How to query schema data
Forecasters will browse various model data in the form of pages and make numerical model forecasts. This page needs to provide query methods for multiple schema data, such as:
查询一个经纬度平面的格点数据:比如未来三小时全球地面温度的格点数据,或者未来三小时浙江省地面温度数据。
查询某个格点的时间序列数据:比如阿里云公司所在地未来3小时、未来6小时、一直到未来72小时的温度。
查询不同物理量的数据:比如查询某一预报时效、某一高度、某一点的全部物理量的预报数据。
查询不同模式系统产生的数据:比如同时查询欧洲中心的某一模式数据和中国气象机构产生的对应数据等。
查询方式不限于以上几种,本文重点分析前两种较为典型的查询方式,即“查询一个经纬度平面的格点数据”和“查询某个格点的时间序列数据”。
方案要解决哪些问题
首先是存储方面的问题。海量的气象数据必须采用多台服务器进行存储,问题在于如何选择或者构建一个分布式存储系统来保障数据可靠性、可管理性和系统可维护性。
然后是查询的问题。预报员在进行气象预报时,需要快速的浏览大量的气象数据,才能高效准确的进行气象预报。因此,各种查询操作的延迟要很低,必须在毫秒级。上面提到,数据是分布在多台机器之中的,为了实现毫秒级的延迟,必须满足以下两点:
能够根据查询条件,高效的定位到要查询的数据。
定位到数据之后,需要高效的筛选出本次查询所需的数据。比如查询某个点的时间序列数据,需要只筛选出该点的数据。
下面我们来看传统方式和分布式NoSQL方式分别如何解决该问题。
传统的气象数据存储查询方案
由于多维气象数据具有数据量大的特点,所以传统的存储方式是文件系统,而非数据库。在文件系统中,每个维度作为一个目录,形成一个树形的目录结构,数据文件作为树的叶子节点,如下图所示。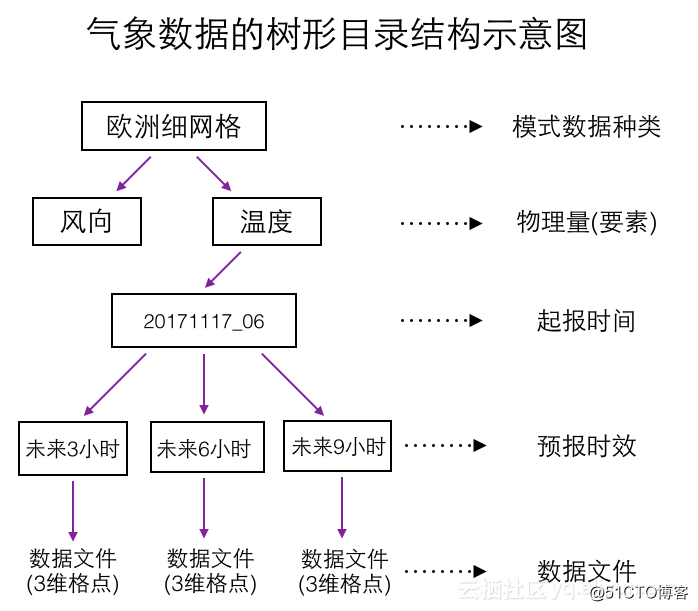
上图只是一个示意图,实际存储时数据的层次关系和目录结构设计会因地而异,不同的研究机构会采用不同的目录结构设计。一个需要考虑的问题是,一个数据文件需要控制在多大,即一个数据文件要保存多少维度信息的数据。如果每个文件都很小,文件系统中就会有大量的小文件,导致定位文件的延迟增加,维护这些小文件的负担也较大。如果每个文件都较大,那么就要避免在查询时读取整个文件,导致延迟很高。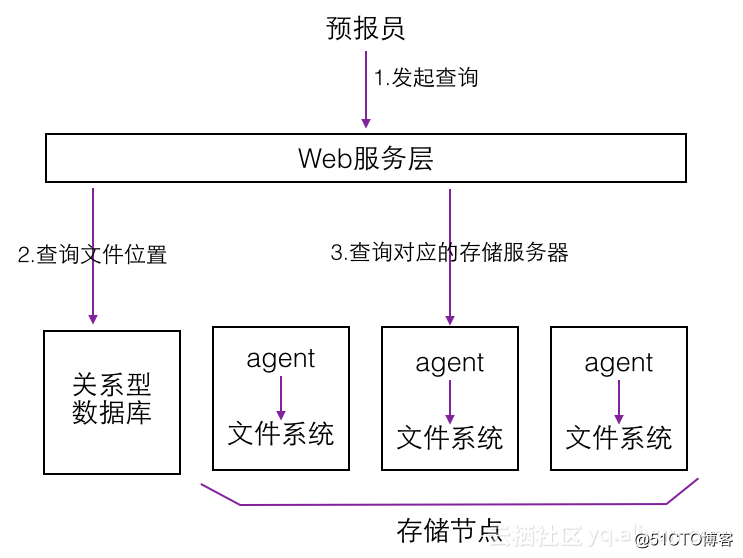
下面我们来看这种方案分别如何解决存储和查询问题。对于存储,这种方案会人为的将不同类型的数据划分到不同的服务器上,实现数据的分布式保存,每台机器的目录结构都如上图所示。为了维护某种类型的数据对应哪台机器,常采用关系型数据库进行记录,或者使用配置文件的方式。
对于数据的查询,这种方案常会先从关系型数据库中获取要查询的数据文件所在的机器和文件系统路径,然后访问对应机器上的agent进行查询。这个agent会访问本地文件系统,读取数据文件,并筛选和处理出用户所需的数据。这个agent是必不可少的,其作用是在本地先对数据进行一遍筛选和处理,以减少传输的网络流量。
这里我们可以举一个例子,假设我们要获取某个点在某一高度的未来72小时的时间序列数据,预报时效间隔3小时,那么其实只是获取24个数值。问题在于这24个数值涉及的数据文件可能很大,可能达到几百MB的级别,因为其中的冗余数据太多了,其他的经纬度格点,其他高度的数据我们都是不关心的。本地agent在读取数据时,如果数据采用特定的文件格式,比如NetCDF,可以只读取一个大文件中的一部分,起到优化效果。
这种模式的缺点也很明显: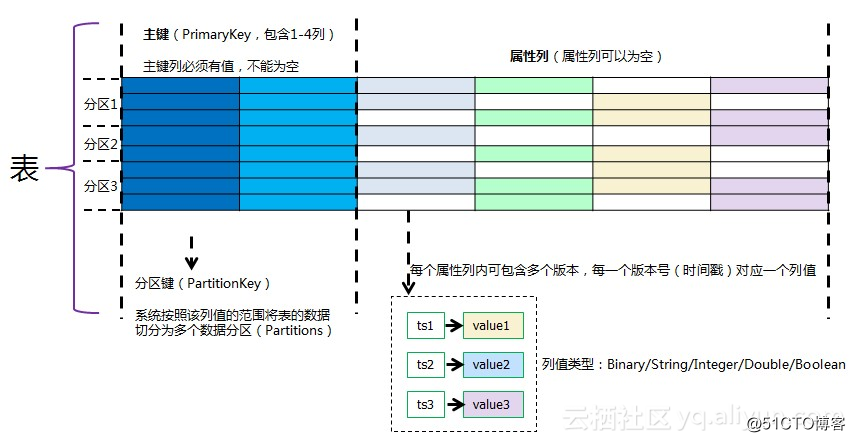
人为的将不同类型的数据存储在不同机器上,需要解决数据可靠性和可用性的问题,带来很大的维护负担。
数据种类和存储节点的对应关系是确定好的,在新增或者删减数据时需要人为进行调整,可扩展性较差。
为了优化查询性能,必须开发一个agent程序图片描述,启动在存储节点上。这个程序负责从数据文件中筛选出符合条件的一小部分数据,假设数据文件采用NetCDF格式存储,本地agent可以只读取文件中的一部分内容,减少读盘的延迟。这种定制化的方案带来了一些开发维护成本,同时这个agent也难以集成到现有的成熟的分布式存储系统中,即这是一种基于本地文件系统和NetCDF文件格式的特定优化。
使用表格存储进行气象数据存储和查询的方案
表格存储(TableStore)是一款云上的分布式NoSQL数据存储服务,支持高并发的数据读写和PB级别的数据存储能力,提供毫秒级的读取性能。通过上面对传统方案的分析,我们对海量气象数据的存储和查询已经有了一定认识,那么表格存储如何解决其中的问题呢?
首先,表格存储是一种分布式NoSQL存储服务,数据本身会分散到不同的机器上,单集群可以支撑10PB的数据规模,这就解决了存储的问题。
其次,表格存储支持快速的单行查询和范围查询,从数据模型上可以认为是一个巨大的SortedMap。即使表中拥有几百亿、几万亿行数据,单行数据的定位速度并不会下降,这就解决了文件系统在大量小文件时定位慢的问题。
从查询的角度来看,越高效准确的定位到数据,读取以及返回的冗余数据越少,查询效率越高。那么我们可以把表格存储中一行或者一列的数据大小控制在一个恰当的粒度,以此来满足各种查询方式的需求。实践中已经验证,这种方式可以带来非常优秀的性能。下面具体来看存储方案的设计。
存储方案设计
表格存储的数据模型如下图所示,每行数据分为主键和属性列,通过主键来标示一行数据。
下文中的方案重点来讲主键列和属性列如何设计,并且如何实现两种典型的查询方式, 即“查询一个经纬度平面的格点数据”和“查询某个格点的时间序列数据”。
方案一
对于气象中的某种模式数据Data,我们暂且用下面的方式表示:
Data = F(物理量、起报时间、高度、预报时效、经度、纬度)
我们可以把前四个维度作为主键(PrimaryKey,简称PK),后两个维度的数据作为属性列保存,表示为:
Row(物理量、起报时间、高度、预报时效) = F(经度、维度)
PK = (物理量、起报时间、高度、预报时效)
Data = F(经度、维度) = 二维的经纬度格点数据(我们采用binary格式存储在属性列中)
Meta = 一些其他的辅助信息,比如数据是否压缩等等。
那么 Row(PK) = (Data, Meta, 其他属性列), Table = SortedMap(Rows), 如下图所示。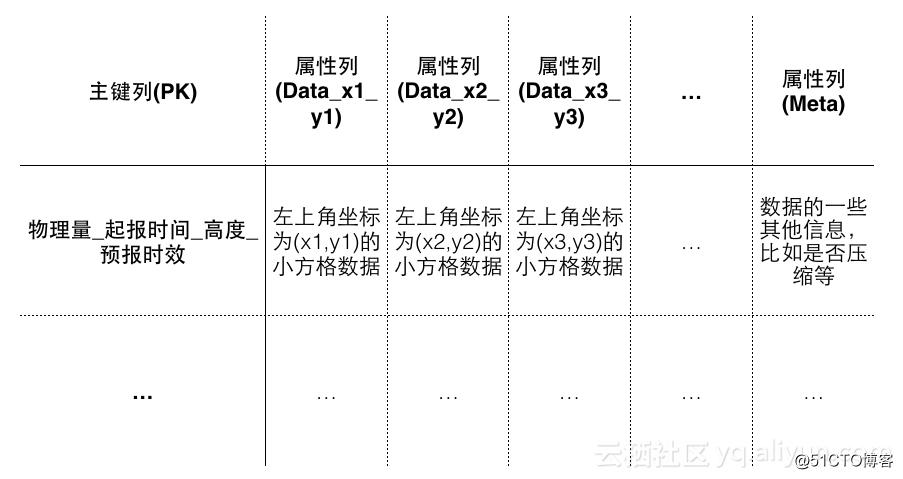
这种方式下,对于查询“一个经纬度平面的格点数据”, 那么只需要把物理量、起报时间、高度、预报时效这些信息拼成主键,然后通过表格存储的GetRow接口读取一行数据即可,如果一次要获取多个经纬度平面的数据,可以通过BatchGetRow接口一次读取多行数据。读取完成后,客户端需要解析出属性列中存储的二进制数据,因为气象数据的压缩率较高,这种方式下推荐对数据进行压缩。
设计这种方案时很重要的考虑因素是,一行存储多大粒度的数据。这里一行只存储一个经纬度平面的数据,以2880 x 570的float数据为例为例,数据量为2880 x 570 x 4=6.3MB数据,压缩后数据量更小。这个粒度对于存储和查询都较为合适,而且气象中大部分查询请求也是读取一个平面。
但是这种方案有一个缺点,对于“查询某个格点的时间序列数据”,必须先读取出一个完整的经纬度格点数据,然后筛选出所需的一个格点。因为获取的冗余数据太多,所以对这个查询场景不能提供很好的性能。由此我们引出方案二。
方案二
为了满足“查询某个格点的时间序列数据”的需求,我们想到通过对数据再切分,来减小数据的粒度,缩小冗余数据的查询和返回。为了缩小数据的粒度,我们把一行中的一个经纬度平面再切分为100个方格,存储在100个属性列中。下图是一个切分的例子,我们把一个481 x 641的平面,切分成很多49 x 65的方格,每个方格的数据保存为一列,列名为Data_x_y, (x, y)是这个方格的左上角坐标。
此时, Row(PK) = (Data_x1_y1, Data_x2_y2, Data_x3_y3, … , Meta)
切分示意图如下:
这种方式下,对于“查询某个格点的时间序列数据”,我们先根据切分方式算出这个格点落在哪个属性列中,然后设置只读取该属性列,然后使用BatchGetRow接口批量读取不同预报时效的数据,即可获取并筛选出“这个格点的时间序列数据”。相比方案一,这里读取的数据量缩小了100倍,性能得到了巨大的提升。
如果读取的不是某个格点,而是读取一部分区域的数据。那么可以先算出这个区域涉及哪些小方格,只读取这些小方格的数据,也可以大量的减少冗余数据的读取。
如果需要读取整个平面,方案一和方案二都可以满足。方案一的好处在于数据放在一起可以获得较好的压缩率,因此业务上可以考虑综合使用方案一和方案二,还是只使用方案二。
方案优缺点
采用表格存储的方案之后,新的查询方式如下图所示: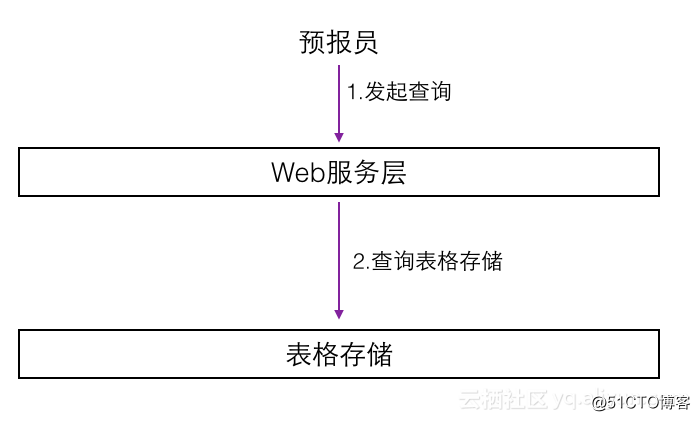
这种方案的优点可以总结一下:
高可靠和高可用保障,可维护性和可扩展性强。采用成熟的分布式NoSQL系统,相比人为的管理多台服务器的文件系统,可靠性和可用性有巨大提升。可扩展性强,针对不同类型的模式数据,都可以方便的纳入这一系统中来。
弹性的存储和计算资源。使用公共云上的表格存储服务,只需要按量付费,大大的节约了成本,并且可以应对短期的容量或访问高峰。
性能优异,架构简单。实际测试中,上述方案的性能远优于传统方案。同时,传统方案需要在服务端启动一个agent来优化读取性能,在表格存储的方案中已经不再需要开发类似的agent,架构更加简单,分层清晰。
这种方案的缺点在于,气象系统的开发工程师需要对分布式NoSQL较为了解,特别是在进行方案二的实现时,需要对数据进行切分,有一些开发上的复杂度。
作者:亦征