The basic problem of text learning is related to input features. Each file, email or book title we learn has a non-standard length, so a single word cannot be spoken as an input feature, so in the text There is a function in the machine learning of the word - Bag of Words, the basic idea selects a text, and then calculates the frequency of the text
Nice Day与A Very Nice Day

Mr Day Loves a Nice Day
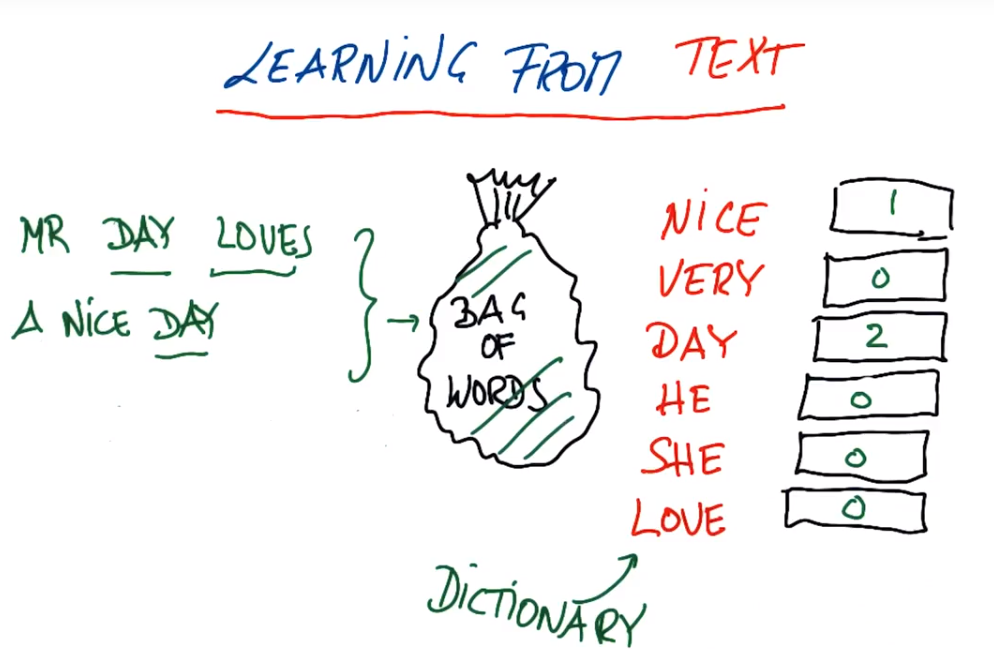
Bag-of-words property : word order of phrases does not affect frequency (Nice Day and Day Nice), long texts or phrases give completely different input vectors (the same email is copied ten times and then ten copies are put into the same text, giving The result is completely different from a copy), can't handle compound phrases composed of multiple words (Chicago bulls have different meanings when separated and grouped together, the dictionary has now been changed, there are compound phrases Chicago bulls)

Bag of words in sklearn is called CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() string1 = "hi Katie the self dirving car will be late Best Sebastian" string2 = "Hi Sebastian the machine learning class will be great great great Best Katie" string3 = "Hi Katie the machine learning class will be most excellent" email_list = [string1,string2,string3] bag_of_words = vectorizer.fit(email_list) bag_of_words = vectorizer.transform(email_list)


When performing text analysis, in the vocabulary, not all words are equal, and some words contain more information, such as low-information words in the figure above;
Some words do not contain information, they will become noise in the data set, so to remove the corpus, this list of words is stop words, generally low-information words that appear very frequently. A common preprocessing step in text analysis is to process the data. remove stop words before

NLTK is a natural language toolkit. Get the list of stop words from NLTK. NLTK needs a corpus (ie document) to get stop words. It needs to be downloaded for the first time.
import nltk
nltk.download()
from nltk.corpus import stopwords
sw = stopwords.words("english")
len (sw)
<<<153
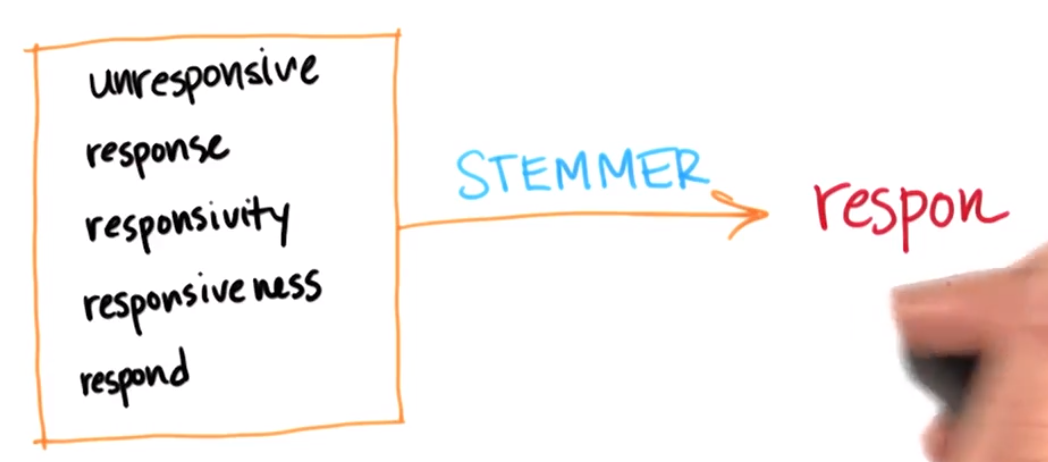
Stemming, stemming or stemming that can be used in classifiers or regression
Convert the following five-dimensional input space to one-dimensional without losing any real information
Stemming with NLTK
from nltk.stem.snowball import SnowballStemmer
votes = SnowballVotes ('english')
print stemmer.stem('responsiveness')
print stemmer.stem('responsivity')
print stemmer.stem('unresponsive')
<<<respons
<<<respons
<<<unrespons
In general, using a stemmer can clean up the vocabulary of your corpus to a great extent
The order of operators in text processing: stem extraction first (reason: if you put the word bag first, you will get the same word repeated many times in the word bag)

E.g:
Suppose the passage "responsibility is responsive to responsible people" is being discussed (this sentence is ungrammatical)
If you put this text directly into the bag of words, what you get is:
[is:1
people: 1
responsibility: 1
responsive: 1
responsible:1]
Then apply stemming again, and you get
[is:1
people:1
respon:1
respon:1
respon:1]
(if you can find a way to stem the object of the count vectorizer in sklearn, this is the best attempt The likely result is that your code will crash...)
That way, you'd need to do one more postprocessing to get the following bag of words, which if you stemmed from the start, you'd get the bag directly:
[is:1
people:1
response:3]
Obviously, the second bag of words is likely what you want, so stemming first here will get you the correct answer.
Tf Idf expression - pay more attention to rare words, help distinguish information
Tf - term frequency Term frequency - more like a bag of words, each term or word is weighted according to the number of times it appears in a file (a word that appears ten times is weighted ten times more than a word that appears once)
Idf - inverse document frequency - words are weighted according to their frequency in the entire corpus, in all documents

Text Learning Mini Project
Exercise: parseOutText() warm up
- Just run the code
- answer: Hi Everyone If you can read this message youre properly using parseOutText Please proceed to the next part of the project
Exercise: Deploying Stemming
- answer:hi everyon if you can read this messag your proper use parseouttext pleas proceed to the next part of the project
- Pay attention to the use of filter here, to filter out blank characters
text_list = filter(None,text_string.split(' '))
stemmer = SnowballStemmer("english")
text_list = [stemmer.stem(item) for item in text_list]
words = ' '.join(text_list)
Exercise: Clear signature text
answer:tjonesnsf stephani and sam need nymex calendar
### use parseOutText to extract the text from the opened email
words = parseOutText(email)
### use str.replace() to remove any instances of the words
### ["sara", "shackleton", "chris", "germani"]
stopwords = ["sara", "shackleton", "chris", "germani", "sshacklensf", "cgermannsf"]
for word in stopwords:
words = words.replace(word, "")
words = ' '.join(words.split())
### append the text to word_data
word_data.append(words)
### append a 0 to from_data if email is from Sara, and 1 if email is from Chris
if name == "sara":
from_data.append(0)
elif name == "chris":
from_data.append(1)
Exercise: Doing TfIdf
Convert word_data to tf-idf matrix using sklearn TfIdf transform. Remove English stop words.
Use get_feature_names() to access the mapping between words and feature numbers, returning a list of all words in the vocabulary. How many different words are there?
Exercise: Accessing TfIdf Features
What is the word number 34597 in your TfId?
The answer I got: 42282 and reqs, and the stephaniethank sequence is 37645
- Correct Answer: 38757 and stephaniethank
for name, from_person in [("sara", from_sara), ("chris", from_chris)]:
for path in from_person:
### only look at first 200 emails when developing
### once everything is working, remove this line to run over full dataset
#temp_counter += 1
#if temp_counter < 200:
path = os.path.join('..', path[:-1])
print path
email = open(path, "r")
### use parseOutText to extract the text from the opened email
words = parseOutText(email)
### use str.replace() to remove any instances of the words
### ["sara", "shackleton", "chris", "germani"]
stopwords = ["sara", "shackleton", "chris", "germani", "sshacklensf", "cgermannsf"]
for word in stopwords:
words = words.replace(word, "")
words = ' '.join(words.split())
### append the text to word_data
word_data.append(words)
### append a 0 to from_data if email is from Sara, and 1 if email is from Chris
if name == "sara":
from_data.append(0)
elif name == "chris":
from_data.append(1)
email.close()
print word_data[152]
print "emails processed"
from_sara.close()
from_chris.close()
pickle.dump( word_data, open("your_word_data.pkl", "w") )
pickle.dump( from_data, open("your_email_authors.pkl", "w") )
### in Part 4, do TfIdf vectorization here
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
vectorizer.fit_transform(word_data)
feature_names = vectorizer.get_feature_names()
print len(feature_names)
print feature_names[34597]