Original link: http://blog.cloudera.com/blog/2015/06/inside-apache-hbases-new-support-for-mobs/
Design Background for HBase MOBs Features
Apache HBase is a distributed, scalable, performant, consistent key value database that can store a variety of binary data types. It excels at storing many relatively small values (<10K), and providing low-latency reads and writes.
However, there is a growing demand for storing documents, images, and other moderate objects (MOBs) in HBase while maintaining low latency for reads and writes. One such use case is a bank that stores signed and scanned customer documents. As another example, transport agencies may want to store snapshots of traffic and moving cars. These MOBs are generally write-once.
Apache HBase is a distributed, scalable, high-performance, consistent key-value database that can store a wide variety of binary data. Excellent for storing small files (less than 10K) with low read and write latency.
With that comes the growing need for storage of documents, images, and other medium-sized files, with low latency for reads and writes. A typical scenario is where a bank stores a customer's signature or scanned documents. Another typical scenario, the traffic department saves snapshots of road conditions or passing vehicles. Medium size files are usually written once.
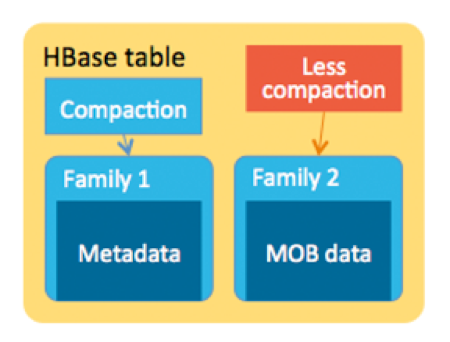
Unfortunately, performance can degrade in situations where many moderately sized values (100K to 10MB) are stored due to the ever-increasing I/O pressure created by compactions. Consider the case where 1TB of photos from traffic cameras, each 1MB in size, are stored into HBase daily. Parts of the stored files are compacted multiple times via minor compactions and eventually, data is rewritten by major compactions. Along with accumulation of these MOBs, I/O created by compactions will slow down the compactions, further block memstore flushing, and eventually block updates. A big MOB store will trigger frequent region splits, reducing the availability of the affected regions.
In order to address these drawbacks, Cloudera and Intel engineers have implemented MOB support in an HBase branch (hbase-11339: HBase MOB). This branch will be merged to the master in HBase 1.1 or 1.2, and is already present and supported in CDH 5.4.x, as well.
Unfortunately, when storing files between 100k and 10M in size, performance is degraded due to the ever-increasing read and write pressure caused by compression. Imagine a scenario where the traffic camera generates 1TB of photos every day and stores them in Hbase, each file is 1MB. Some files are compressed multiple times to minimize. Data is written repeatedly due to compression. As the number of medium-sized files accumulates, the reads and writes generated by compression can slow down compression, further blocking memstore flushes and eventually updates. A large amount of MOB storage will trigger frequent region segmentation, and the availability of the corresponding region will decrease.
To solve this problem, Cloudera and Intel engineers implemented support for MOB in the Hbase branch. ( hbase-11339: HBase MOB ). (Translator's Note: This feature did not appear in versions 1.1 and 1.2, but was incorporated in version 2.0.0). You can get it in CDH 5.4.x.
Operations on MOBs are usually write-intensive, with rare updates or deletes and relatively infrequent reads. MOBs are usually stored together with their metadata. Metadata relating to MOBs may include, for instance, car number, speed, and color. Metadata are very small relative to the MOBs. Metadata are usually accessed for analysis, while MOBs are usually randomly accessed only when they are explicitly requested with row keys.
Users want to read and write the MOBs in HBase with low latency in the same APIs, and want strong consistency, security, snapshot and HBase replication between clusters, and so on. To meet these goals, MOBs were moved out of the main I/O path of HBase and into a new I/O path.
In this post, you will learn about this design approach, and why it was selected.
Operations on MOBs are usually focused on writes, rarely updated or deleted, and read infrequently. MOBs are usually stored with metadata. Metadata is relatively small compared to MOB and is usually used for statistical analysis, while MOB is generally obtained through explicit row keys.
Users want to use the same API to read and write MOB files in Hbase, and maintain low latency between clusters, strong consistency, security, snapshots, and Hbase replicas. To achieve this, the MOB must be moved from HBase's main read-write directory to a new read-write directory.
Feasible plan analysis
There were a few possible approaches to this problem. The first approach we considered was to store MOBs in HBase with a tuned split and compaction policies—a bigger desired MaxFileSize decreases the frequency of region split, and fewer or no compactions can avoid the write amplification penalty. That approach would improve write latency and throughput considerably. However, along with the increasing number of stored files, there would be too many opened readers in a single store, even more than what is allowed by the OS. As a result, a lot of memory would be consumed and read performance would degrade.
There are potential solutions to this problem. The first is to optimize the split and compression strategy - a larger MaxFileSize to reduce the frequency of region splitting, and less or no compression to avoid write corruption. This improves write latency and throughput is much better. However, as the number of files grows, a single store will open a very large number of readers, even exceeding the limits of the operating system. The result is that memory is used up and performance degrades.
Another approach was to use an HBase + HDFS model to store the metadata and MOBs separately. In this model, a single file is linked by an entry in HBase. This is a client solution, and the transaction is controlled by the client—no HBase-side memories are consumed by MOBs. This approach would work for objects larger than 50MB, but for MOBs, many small files lead to inefficient HDFS usage since the default block size in HDFS is 128MB.
For example, let’s say a NameNode has 48GB of memory and each file is 100KB with three replicas. Each file takes more than 300 bytes in memory, so a NameNode with 48GB memory can hold about 160 million files, which would limit us to only storing 16TB MOB files in total.
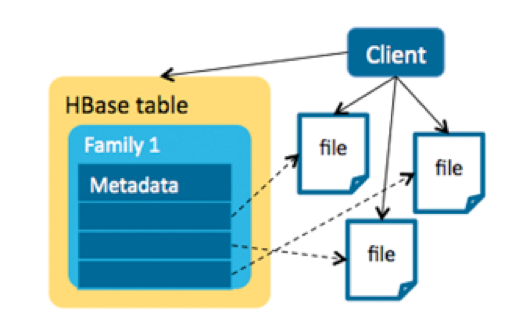
Another way is to use HBase+HDFS to store metadata and MOB files separately. One file corresponds to one Hbase entry. This is a client-side solution, where the transaction is controlled. MOB does not consume Hbase's memory. Stored objects can exceed 50MB. However, a large number of small files make HDFS underutilized because the default block size is 128M.
For example, NameNode has 48G memory, 100KB per file, 3 replicas. Each file occupies 300 bytes in memory, and 48G memory can store about 160 million files, limiting the total file size stored to only 16T.
As an improvement, we could have assembled the small MOB files into bigger ones—that is, a file could have multiple MOB entries–and store the offset and length in the HBase table for fast reading. However, maintaining data consistency and managing deleted MOBs and small MOB files in compactions are difficult. Furthermore, if we were to use this approach, we’d have to consider new security policies, lose atomicity properties of writes, and potentially lose the backup and disaster recovery provided by replication and snapshots.
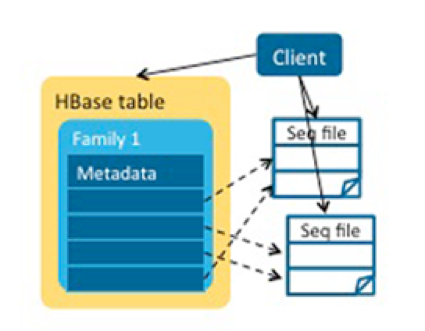
We can combine many small MOBs into a large file, and a file has multiple MOB entries to speed up reading by storing offsets and lengths. However, maintaining data consistency, managing deleted files and small compressed files is difficult. Also, we also need to consider security policies, loss of atomicity of writing data, possibly loss of backup and disaster recovery provided by replication and snapshots.
HBase MOB Architecture Design
In the end, because most of the concerns around storing MOBs in HBase involve the I/O created by compactions, the key was to move MOBs out of management by normal regions to avoid region splits and compactions there.
The HBase MOB design is similar to the HBase + HDFS approach because we store the metadata and MOBs separately. However, the difference lies in a server-side design: memstore caches the MOBs before they are flushed to disk, the MOBs are written into a HFile called “MOB file” in each flush, and each MOB file has multiple entries instead of single file in HDFS for each MOB. This MOB file is stored in a special region. All the read and write can be used by the current HBase APIs.
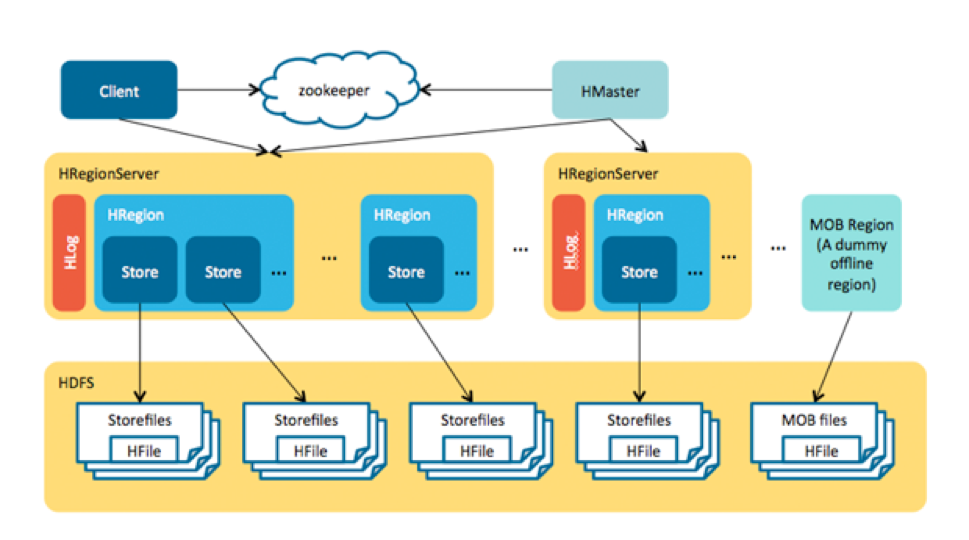
Finally, since most of the worry comes from the IO brought by compression, the most critical is to move the MOB out of the normal region management to avoid region segmentation and compression.
The design of HBase MOB is similar to the way of Hbase+HDFS, which stores metadata and MOB separately. The difference is the design of the server. Medium-sized files are cached in memstore before being flushed to disk, and each time they are flushed, medium-sized files are written to a special HFile file—“MOB File”. Each medium file has multiple MOB entries, unlike HDFS only one entry. MOB files are placed in a special region. Both reads and writes go through the existing Hbase API.
Unfinished, see the next article: https://my.oschina.net/u/234661/blog/1553060