1. Hadoop



2. HDFS

Large files; write once, read many times, and cannot be modified; ordinary hardware can store them.

Low-latency data; small file processing has no advantage; data that is not suitable for multiple writes and random changes
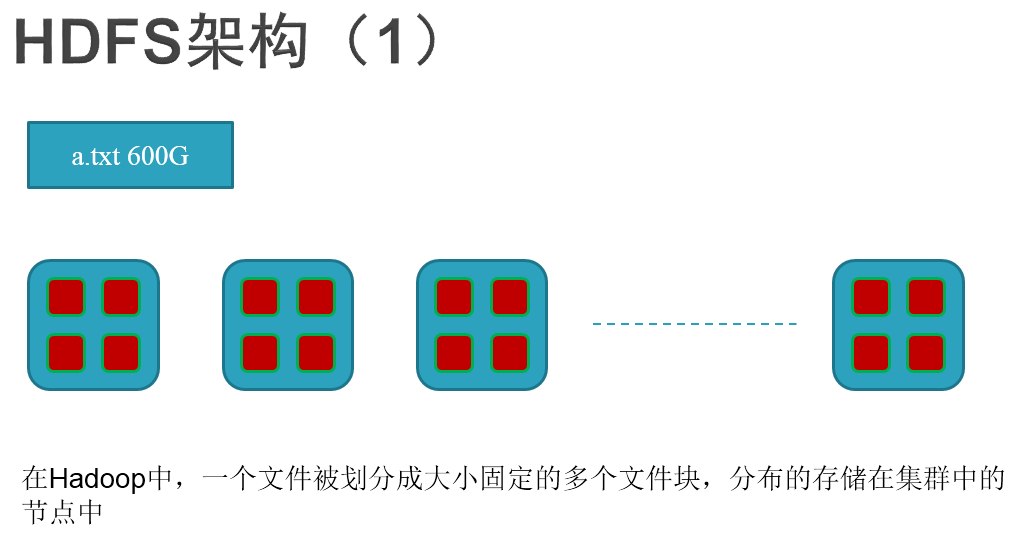
At the same time, it can be read in a distributed manner, and the reading speed can be greatly accelerated.

Copy backup; automatic backup;
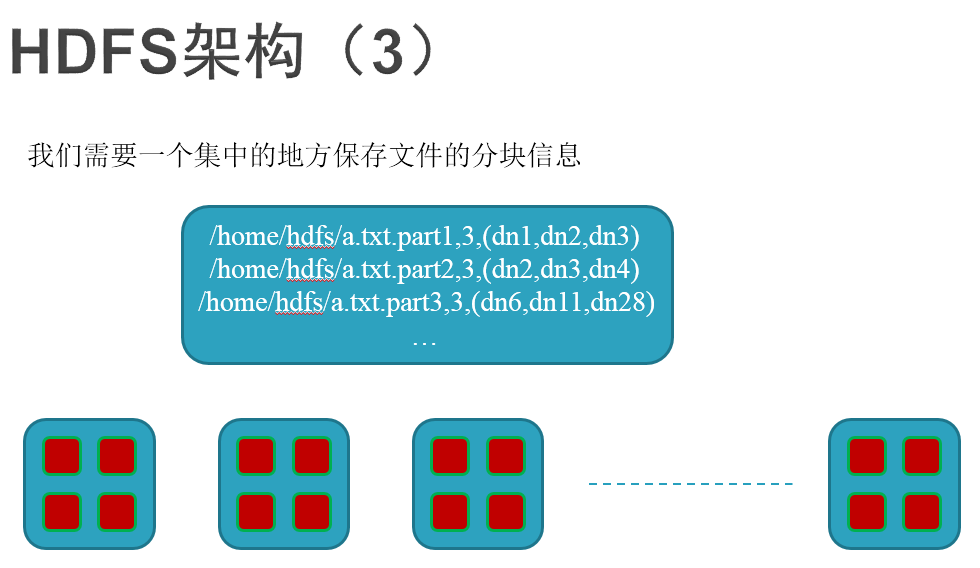
The block information is stored in: namenode.
Block storage; redundant storage; distributed reading;
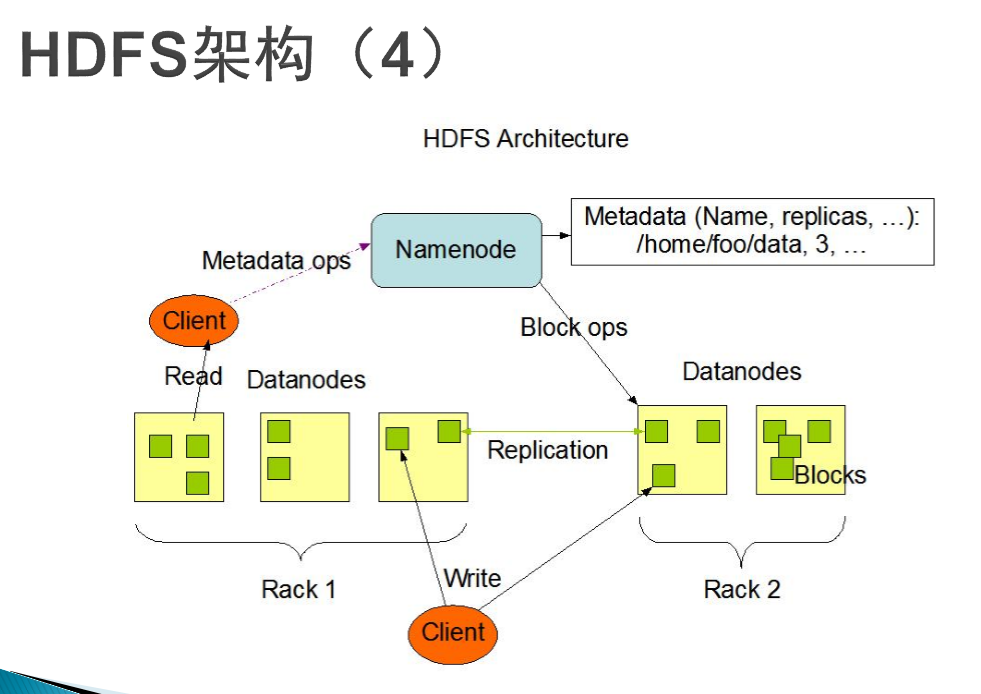

namenode is kept in memory. And there are copies.
When running, standy obtains NameNode information from active from time to time. Once there is a problem with active, switch to standy mode.
three,

