Scrapy framework learning (8) - Scrapy-redis distributed crawler learning
Scrapy-redisThe distributed crawler framework is Scrapyimproved on the basis of the crawler framework. By Rediscaching data, crawler programs can be run on multiple machines. The examples in this article are CentOSrunning on a virtual machine.
1. Redis installation
Regarding the installation of Redis, there are many articles on the Internet, and there are also some problems in configuring the Redis environment. The following two articles introduce the installation and problems of Redis in detail, and they are directly transferred here. Because my Scrapy-Rediscrawler code is running CentOSin
Installation and configuration of Redis under CentOS 7
CentOS 7.0 installs Redis 3.2.1 detailed process and usage frequently asked questions
2. Redis distributed testing
We use 3 machines to crawl data with distributed crawler. After installing it on the virtual machine Redis, we will conduct Redisdistributed testing.
We have server1 as the Mastermachine ( ip:192.168.108.20). server2( ip:192.168.108.21), server3( ip:192.168.108.22) as 2 machines Slaves.
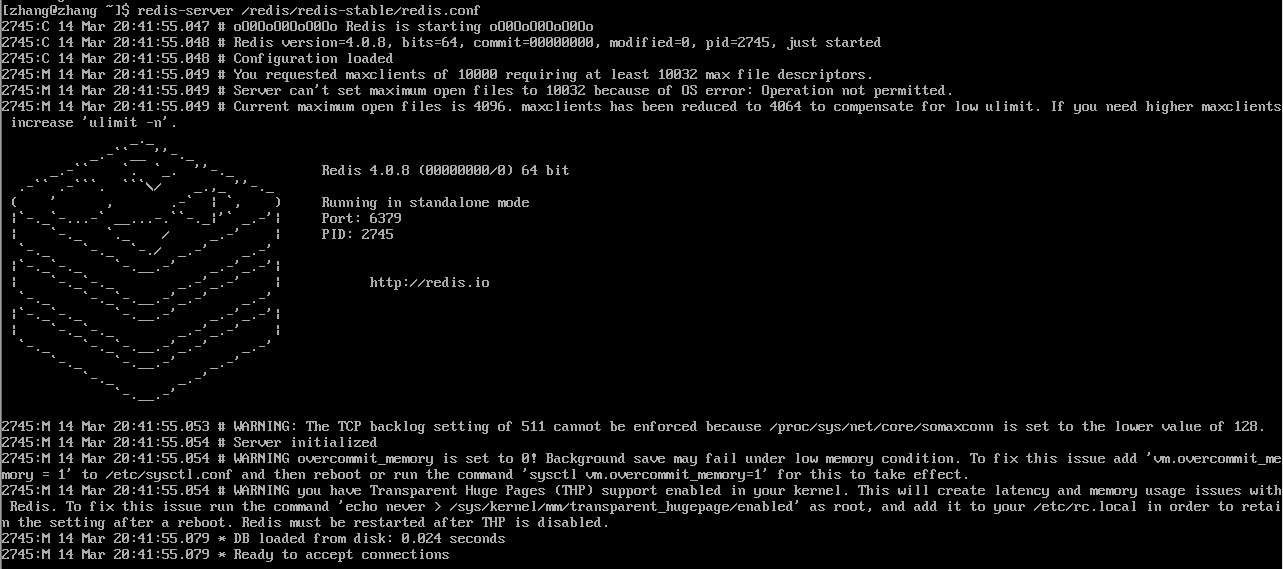
2.1 Start the Redis service of the Master machine
Find the configuration file of redis redis.conf, comment bind 127.0.0.1, and set the protected mode protected-modeto no.
specified redis.confstartup
redis-server /redis/redis-stable/redis.confAs shown in the figure:
2.2 Start the Redis client redis-cli on each machine
Master machine:
redis-cli
Slaves machine, specify the ip of the Master machine
redis-cli -h 192.168.108.20If the following occurs:
Could not connect to Redis at 192.168.108.20:6379: No route to host
You need to clear the firewall configuration for each machine:
sudo iptables -FConnect to Master's Redis again, as shown in the figure:
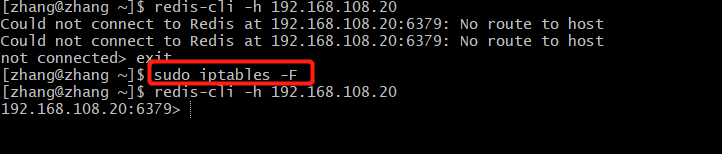
If the machine fails to connect, it may be a firewall problem, you can try: sudo iptables -F to clear the firewall configuration
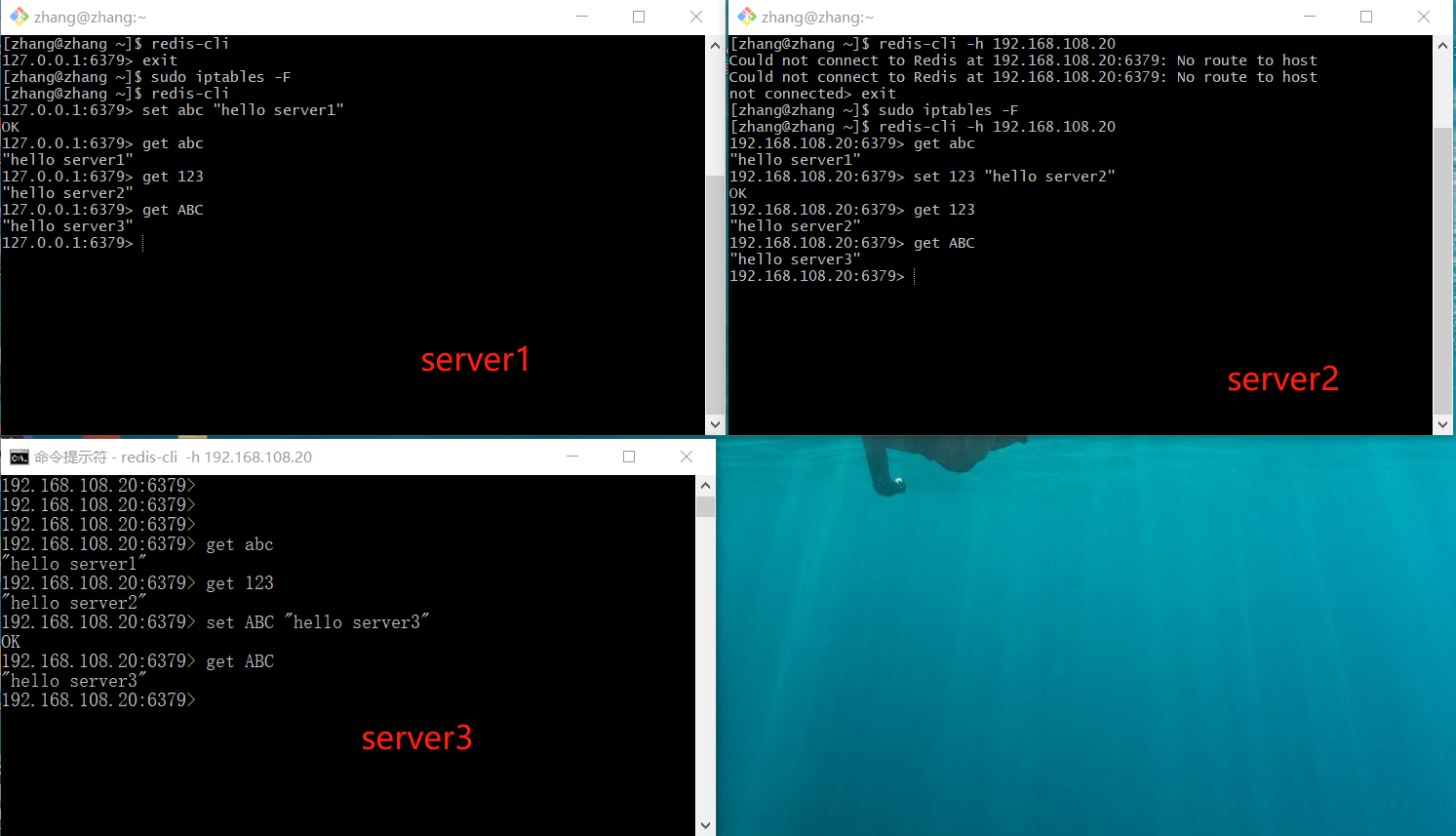
2.3 Test Distributed Redis
3. Crawler code of scrapy-redis
Scrapy-redis distributed crawler, crawling is: http://sh.58.com/chuzu/.
Let's look at the code below, which is basically the same as the Scrapy project, except that the Spider class is changed to the class in Scrapy-redis, and the configuration in settings.py is different.
3.1 Item
define entity class
class Redis58TestItem(scrapy.Item):
# 标题
title = scrapy.Field()
# 房间
room = scrapy.Field()
# 区域
zone = scrapy.Field()
# 地址
address = scrapy.Field()
# 价格
money = scrapy.Field()
# 发布信息的类型,品牌公寓,经纪人,个人
type = scrapy.Field()3.2 spider
spider crawler class implementation
from scrapy.spiders import Rule
from scrapy_redis.spiders import RedisCrawlSpider
from scrapy.linkextractors import LinkExtractor
from redis58test.items import Redis58TestItem
class Redis58Spider(RedisCrawlSpider):# 继承的Spider是Scrapy-redis框架提供的
# spider的唯一名称
name = 'redis58spider_redis'
# 开始爬取的url
redis_key = 'redis58spider:start_urls'
# 从页面需要提取的url 链接(link)
links = LinkExtractor(allow="sh.58.com/chuzu/pn\d+")
# 设置解析link的规则,callback是指解析link返回的响应数据的的方法
rules = [Rule(link_extractor=links, callback="parseContent", follow=True)]
def parseContent(self, response):
"""
解析响应的数据,获取需要的数据字段
:param response: 响应的数据
:return:
"""
# 根节点 //ul[@class="listUl"]/li[@logr]
# title: .//div[@class="des"]/h2/a/text()
# room: .//div[@class="des"]/p[@class="room"]/text()
# zone: .//div[@class="des"]/p[@class="add"]/a[1]/text()
# address: .//div[@class="des"]/p[@class="add"]/a[last()]/text()
# money: .//div[@class="money"]/b/text()
# type: # .//div[@class="des"]/p[last()]/@class # 如果是add,room .//div[@class="des"]/div[@class="jjr"]/@class
for element in response.xpath('//ul[@class="listUl"]/li[@logr]'):
title = element.xpath('.//div[@class="des"]/h2/a/text()')[0].extract().strip()
room = element.xpath('.//div[@class="des"]/p[@class="room"]')[0].extract()
zone = element.xpath('.//div[@class="des"]/p[@class="add"]/a[1]/text()')[0].extract()
address = element.xpath('.//div[@class="des"]/p[@class="add"]/a[last()]/text()')[0].extract()
money = element.xpath('.//div[@class="money"]/b/text()')[0].extract()
type = element.xpath('.//div[@class="des"]/p[last()]/@class')[0].extract()
if type == "add" or type == "room":
type = element.xpath('.//div[@class="des"]/div[@class="jjr"]/@class')[0].extract()
item = Redis58TestItem()
item['title'] = title
item['room'] = room
item['zone'] = zone
item['address'] = address
item['money'] = money
item['type'] = type
yield item
3.3 Pipe Item
In fact, we don't need to process Pipeitem's data, because the Scrapy framework will deduplicate the data to redis.
class Redis58TestPipeline(object):
def process_item(self, item, spider):
return item3.4 settings.py settings
Information for configuring Scrapy-Redis
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
# 使用什么队列调度
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" # 优先级队列
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue" # 基本队列
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack" # 栈
ITEM_PIPELINES = {
'redis58test.pipelines.Redis58TestPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
REDIS_HOST = '192.168.108.20' # redis Master机器的ip
REDIS_PORT = 63794. Execute the crawler
4.1 Start the redis-server of the Master machine
# 启动Master机器上的redis-server
redis-server /redis/redis-stable/redis.conf4.2 Execute the crawler
Put the crawler code of the Scrapy-redis project on the slaves machine. Enter the spider directory of the project, and then start the scrapy-redis project crawler program on the slaves machine, in no particular order.
scrapy runspider myspider.py4.3 redis-cli of Master machine
Start the url to be crawled in the redis-cli of the Master machine.
127.0.0.1:6379> lpush redis58spider:start_urls http://sh.58.com/chuzu/5. Permanently store redis data
After the crawler program crawls, we save the data in redis to the mongodb database. as follows
import json
import redis
import pymongo
def main():
# 指定Redis数据库信息
rediscli = redis.StrictRedis(host='192.168.108.20', port=6379, db=0)
# 指定MongoDB数据库信息
mongocli = pymongo.MongoClient(host='localhost', port=27017)
# 创建数据库名
db = mongocli['redis58test']
# 创建表名
sheet = db['redis58_sheet2']
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop(["redis58spider_redis:items"])
item = json.loads(data)
sheet.insert(item)
try:
print(u"Processing: %(name)s <%(link)s>" % item)
except KeyError:
print(u"Error procesing: %r" % item)
if __name__ == '__main__':
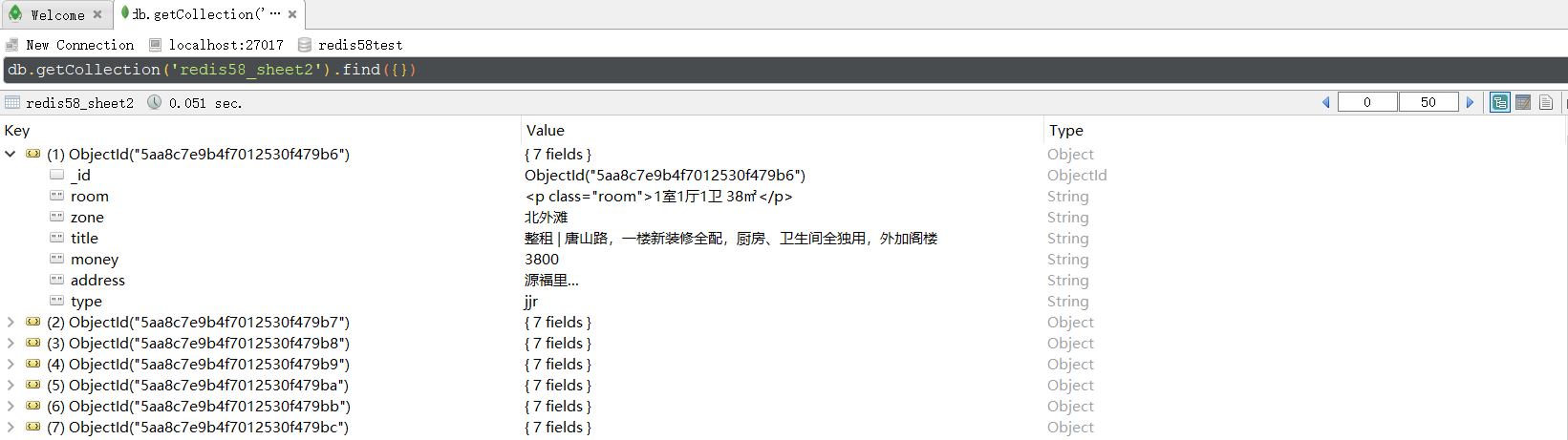
main()The data is shown in the figure: