This article is to explain some of the database knowledge related to JavaWeb job interviews. Of course, not only need to know this content, but also need to master other aspects of knowledge, I have sorted it out according to my own experience, which is convenient for everyone to carry out Systematic learning, only by reviewing and researching more, can you have a better grasp of the technology and get a better offer.
Java Basics: https://blog.csdn.net/Cs_hnu_scw/article/details/79635874
Data structure: https://blog.csdn.net/Cs_hnu_scw/article/details/79896717
Web direction: https://blog.csdn.net/Cs_hnu_scw/article/details/79896165
Operating system: https://blog.csdn.net/Cs_hnu_scw/article/details/79896500
Computer Network: https://blog.csdn.net/Cs_hnu_scw/article/details/79896621
Other knowledge: https://blog.csdn.net/Cs_hnu_scw/article/details/79896876
1: How to locate slow SQL statements?
Answer:(Method 1: slow query log) MySQL locates those SQL statements with low execution efficiency through the slow query log. Long_query_time seconds of the SQL statement log file, locate inefficient SQL by viewing this log file.
1. The parameter slow_query_log
is set to ON, which can capture SQL statements whose execution time exceeds a certain value.
2, long_query_time
When the SQL statement execution time exceeds this value, it will be recorded in the log, it is recommended to set it to 1 or less.
3, slow_query_log_file
log file name.
4. The parameter log_queries_not_using_indexes
is set to ON, which can capture all SQL statements that do not use indexes, although this SQL statement may be executed very quickly
(1) How to use
MySQL The configuration file in Windows system is generally found in my.ini [mysqld] Add the following
code below:
log-slow-queries = F:/MySQL/log/mysqlslowquery. log
slow_query_log = 1
long_query_time = 2
(2) Check whether the slow SQL log is enabled
mysql> show variables like 'log_slow_queries';
+-------------------+-------+
| Variable_name | Value |
+---------------- --+-------+
| log_slow_queries | ON |
+------------------+-------+
1 row in set (0.00 sec)
(3) Check how many seconds slower SQL will be recorded in the log file
mysql> show variables like 'long_query_time';
+-----------------+--- ----+
| Variable_name | Value |
+-----------------+-------+
| long_query_time | 1 |
+------- ----------+-------+
1 row in set (0.00 sec)
where value=1, means 1 second
(method 2: through the explanin keyword: used to analyze SQL statements Execution status)
(Method 3: Through the profile keyword: used to analyze the execution details of SQL statements), you can learn more about their use through the following articles;
https://blog.csdn.net/cs_hnu_scw/article/details /78774680
2: What are the characteristics of the stored procedure of the database?
Answer: Advantages of stored procedures:1. Stored procedures enhance the flexibility of the SQL language. Stored procedures can be written using control statements, can complete complex judgments and more complex operations, and have strong flexibility;
2. Reduce network traffic and network load. After the stored procedure is successfully created on the database server side, it is only necessary to call the stored procedure, and the traditional method is to send a large number of SQL statements to the database server side through the network each time and then execute it;
3. The stored procedure is only created when When compiling, there is no need to recompile every time the stored procedure is executed in the future, and the general SQL statement is compiled once every time it is executed, so using the stored procedure can improve the execution speed of the database.
4. The system administrator can limit the access authority to the corresponding data by setting the authority of a certain stored procedure, which avoids the access of unauthorized users to the data and ensures the security of the data.
You can refer to: https://blog.csdn.net/gaohuanjie/article/details/50996175
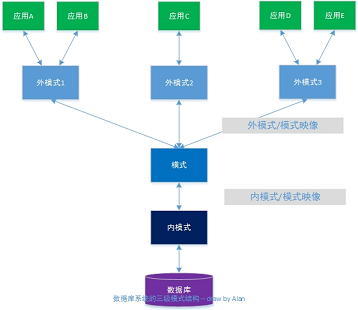
3: What is the three-level schema of the database?
Answer: The three-level schema structure of the database means that the database system is composed of three levels: external schema, schema and internal schema , as shown in Figure
1. Schema schema
is also called: logical schema, which is the logic of all data in the DB A description of structure and characteristics, a common data view for all users. The schema layer is the middle layer of the database schema structure, which is neither related to the physical storage details and hardware environment of the data, nor is it related to specific applications, application development tools and high-level programming languages (C, C++, JAVA, etc.).
A schema is a logical view of database data, and a database has only one schema. In actual work, the schema is equivalent to all the operations of the programmer to create a specific database, such as: this is a MySQL database, there are 2 tables, the name of each table, the name, type, value range of the attribute, the primary key, Foreign keys, indexes, other integrity constraints, and more.
DBMS provides a schema description language (schema DDL) to strictly define the schema.
2. External schema
External schema is also called: subschema/user schema, which is a description of the logical structure and characteristics of the local data used by database users (application programmers, end users), and is the A data view is a logical representation of data related to an application.
Outer schemas are usually subsets of schemas. A database can have multiple foreign schemas. The same external mode can be used by multiple application systems of a user, but an application system can only use one external mode.
External mode is a powerful measure to ensure database security. Each user can only see and access the data in the corresponding external schema, and the rest of the data in the database is invisible.
DBMS provides subschema description language (subschema DDL) to define subschema strictly.
3. Inner mode
Internal schema is also called: Storage schema, a database has only one internal schema. It is a description of the physical structure and storage method of the database, and the representation of data within the database. For example: whether the records are stored in the heap, or according to the ascending (decreasing) of some attribute values, or according to the attribute value cluster (cluster) storage; in what way is the index organized, whether it is a B+ tree index, or a hash index, etc. .
DBMS provides an intra-schema description language (internal-schema DDL/stored-schema DDL) to strictly define intra-schema.
Level
3 schema of the database is 3 levels of abstraction over the data. It enables users to logically and abstractly process data without having to care about the specific representation and storage of data in the computer. In fact, in order to realize the connection and transformation between these three levels of abstraction, DBMS designs two layers of images between these three-level modes:
external mode/mode image
mode/internal mode image
These two-layer images ensure the database The data in can have high logical independence and physical independence.
1. The external schema/schema mapping
can be seen from the above: a DB has only one schema, but can have multiple external schemas.
So, for each foreign schema, the database system has a foreign schema/schema image, which defines the correspondence between this foreign schema and the schema. Definitions of these images are usually included in the description of the outer schema.
When the schema changes (adding new relationships, new attributes, changing the data type of attributes, etc.), the database administrator makes corresponding changes to each external schema/schema image, which can keep the external schema unchanged. And because the application should be written according to the external mode, so the application does not need to be modified, which ensures the logical independence of the data and the program.
Summary: The outer mode/mode mapping ensures that when the mode changes, the outer mode does not change - logical independence .
2. Mode/Internal Mode Image
It can be seen from the above that a DB has only one schema and only one internal schema, and all schema/internal schema images are unique, which define the correspondence between the global logical structure of the data and the storage structure.
When the storage structure of the database changes (for example, another storage structure is selected), the database administrator makes corresponding changes to the schema/internal schema image, so that the schema remains unchanged, so that the application does not have to change. This guarantees the physical independence of data and programs.
Summary: The mode/internal mode mapping ensures that when the internal mode changes, the mode does not change - physical independence .
4: How to backup and restore database?
Answer: mainly to understand the two methods of mysqldump and binlog (binary file);
You can refer to this very good blog post: https://blog.csdn.net/enweitech/article/details/51612858
5: What is the order in which the following SQL statements are executed?
select foo,count(foo)from pokes where foo>10group by foo having count (*)>5 order by foo
答:FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY
6: In mysql, what is the difference between char, varchar, blob, text in the field type?
答:它们的存储方式和数据的检索方式都不一样
(1)char:存储定长数据很方便(最多不可以超过255字符),CHAR字段上的索引效率级高,必须在括号里定义长度,可以有默认值,比如定义char(10),那么不论你存储的数据是否达到了10个字节,都要占去10个字节的空间(自动用空格填充),且在检索的时候后面的空格会隐藏掉,所以检索出来的数据需要记得用什么trim之类的函数去过滤空格。
(2)varchar:存储变长数据(最多不可以超过65535字节),但存储效率没有CHAR高,必须在括号里定义长度,可以有默认值。保存数据的时候,不进行空格自动填充,而且如果数据存在空格时,当值保存和检索时尾部的空格仍会保留。另外,varchar类型的实际长度是它的值的实际长度+1,这一个字节用于保存实际使用了多大的长度。
(3)BLOB被视为二进制字符串,BLOB列没有字符集,并且排序和比较基于列值字节的数值值,在大多数方面,可以将BLOB列视为能够足够大的VARBINARY列
(4)text:存储可变长度的非Unicode数据,最大长度为2^31-1个字符。text列不能有默认值,存储或检索过程中,不存在大小写转换,后面如果指定长度,不会报错误,但是这个长度是不起作用的,意思就是你插入数据的时候,超过你指定的长度还是可以正常插入。
结论:
(1)经常变化的字段用varchar;
(2)知道固定长度的用char;
(3)尽量用varchar;
(4)超过255字节的只能用varchar或者text;
(5)能用varchar的地方不用text;
(6) It is possible to use numeric fields as far as possible to select numeric types instead of string types (phone numbers), which will reduce the performance of queries and connections and increase storage overhead. This is because the engine is processing the query and connecting back to compare each character in the string one by one, while for the numeric type, only one comparison is required;
(7) If you want to store the content of a binary stream (such as a picture), then you can Take with Blob;
7: Under what circumstances should a field be indexed?
Answer: (1) Fields that are frequently queried;
(2) Fields with strong uniqueness, such as gender fields, are not very distinguishable, so they are not suitable for establishment;
(3) The field that appears in the where conditional query, because if it does not appear after the where field, it is not necessary to build an index;
(4) Fields that are not frequently modified, because for frequently modified fields, index maintenance is also required, which consumes time and space;
(5) Fields with no null values;
8: What are the situations in which the field has an index but is found to be invalid?
Answer: (1) For fuzzy matching, use "%Like"
(2) Using the or query, there is no index on one of the fields at both ends
(3) The function operation field is performed, such as the abs() function
(4) Operations are performed on the fields, such as using! = or < ,> etc.
(5) For Bolb and text fields, only prefix indexes can be used
(6) When the field types of the join conditions are inconsistent
(7) For the case where the field is null, and this field is not suitable for indexing
9: Inner join, left join, right join, full join, cross join in the database?
Answer: Inner join: The inner join query operation lists the rows of data that match the join conditions, and it uses comparison operators to compare the column values of the joined columns. (there are three types below)
1.1. Equijoin : Use the equal sign (=) operator in the join condition to compare the column values of the joined columns, and the query result lists all the columns in the joined table, including the duplicate columns.1.2. Unequal join: Compare the column values of the joined columns using other comparison operators other than the equal operator in the join condition. These operators include >, >=, <=, <, !>, !<, and <>.
1.3. Natural join: The equal (=) operator is used in the join condition to compare the column values of the joined columns, but it uses the select list to indicate the columns included in the query result set, and deletes duplicate columns in the join table.
Left join: Based on the left table, connect the data of a.stuid = b.stuid, and then display the corresponding items that the left table does not have, and the column of the right table is NULL
Right join: Based on the right table, the The data of a.stuid = b.stuid is connected, and then the corresponding items that are not in the right table are displayed, and the column of the left table is NULL
Full join: A full outer join returns all rows from the left and right tables. When a row has no matching rows in another table, the select list column of the other table contains null values. If there are matching rows between the tables, the entire result set row contains the data values of the base table; (Note: this method is not supported in mysql, but only by first left join, then use union all and then right join The way)
Cross Join: A cross join returns all rows from the left table, each row from the left table combined with all the rows from the right table. Cross joins are also known as Cartesian products.
Specific example: https://www.cnblogs.com/zxlovenet/p/4005256.html
10: How to ensure the security of the database?
Answer: (1) Set the user's authority: to ensure the illegal intrusion of illegal users;
(2) Define the view: In this way, the data that can be seen by users with different permissions and the data that can be operated are isolated;
(3) Data encryption: to ensure the confidentiality of data;
(4) Start transaction management and fault recovery: prevent unexpected situations from happening and ensure data consistency and integrity. The main measures are logging and data replication;
(5) Database backup and recovery: prevent illegal data loss and accidental discovery, and ensure that data can be recovered to a certain extent;
(6) Audit tracking mechanism: mainly for data update, delete operation log records, to facilitate subsequent review;
(7) Strengthen the security of the server: because the database is stored in the server, it is necessary to ensure the security of the server;
11: