System environment: Windows7
Task requirements: crawling URL + crawling the news content inside + storage
http://www.oschina.net/p/Crawler project software address

1. We must first have a URL list. With the list, we can deeply dig the content of the news
Use the cl command to collect the content to crawl:
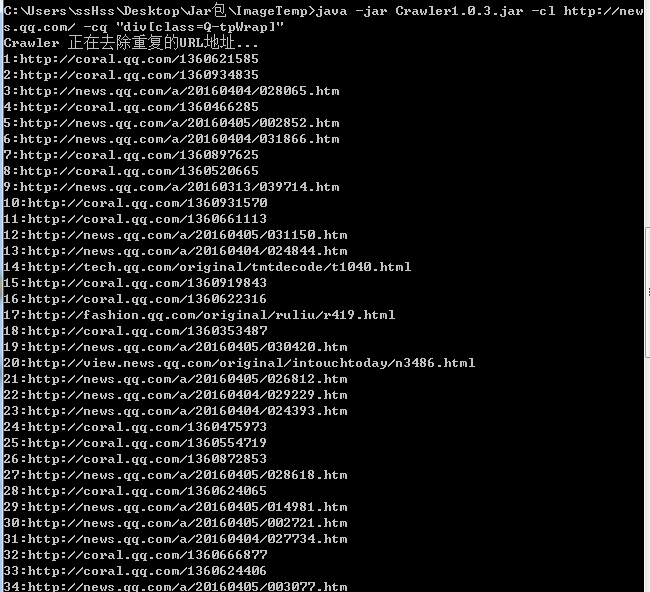
C:\Users\ssHss\Desktop\Jar包\ImageTemp>java -jar Crawler1.0.3.jar -cl http://news.qq.com/ -cq "div[class=Q-tpWrap]"
-cl http://news.qq.com/
-cq "div[class=Q-tpWrap]" 就是样式代码 <div class="Q-tpWrap" style:"xxsxxs:da;dadsad;sad;"><a href="x">x</a></div>
Extract the parameters after the rule -cq
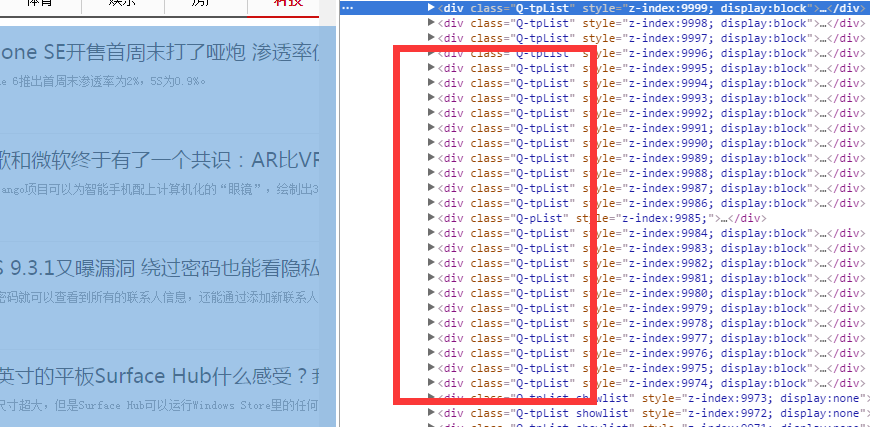
Oh my god, why are there different codes in the crawling? ヾ(。`Д´。). ok, we add the format parameter, haha, it will be safer to write the code in this way. -format feature
Through crawling, we found that news.qq.com/a/ is a URL feature shared by news
We add stunt -fromat "news.qq.com/a/"

Add File, we generate the URL to the local path - input localpath

The first step we completed the collection of URLs
2. Deep crawling content using ci command
Load the local URLlist file for crawling


I read the content, I made a mistake in neirong extraction and changed it to div[class=db].
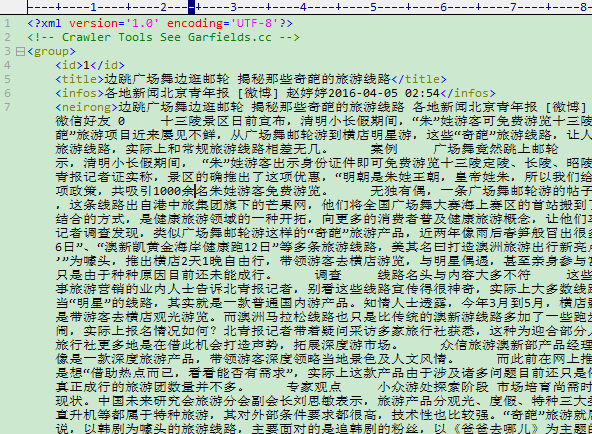
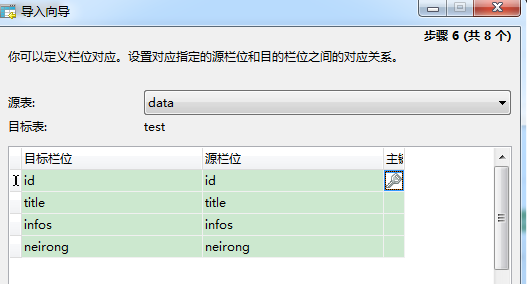
3. Import the database
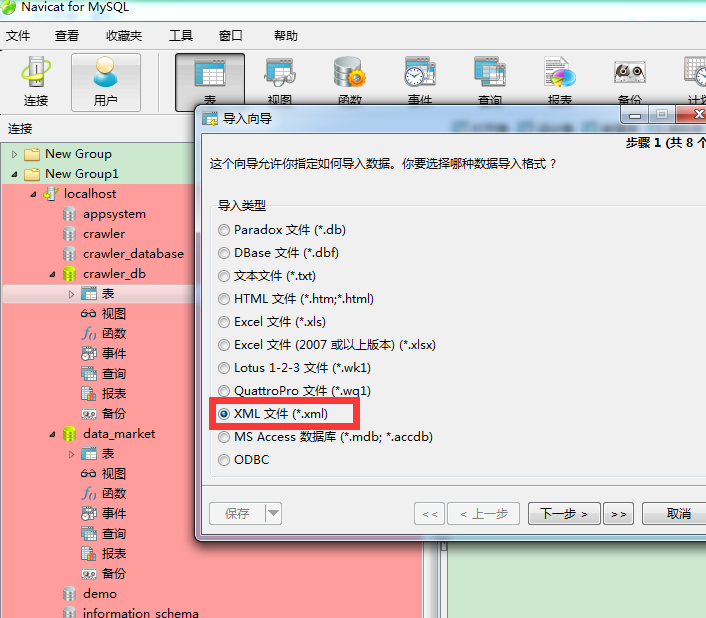


finished