1. Data Enhancement
- Deep neural networks generally require a large amount of training data to obtain ideal results. When the amount of data is limited, data augmentation can be used to
增加训练样本的多样性improve the robustness of the model and avoid overfitting.- Image data augmentation is usually only for training data, and less often for test data.
后者常用的是: Do 5 random cropping, and then average the prediction results of the 5 pictures.
- Flip: Flip the image at a random angle horizontally or vertically;
- Rotation: Rotate the image by a random angle clockwise or counterclockwise;
- Shift (Shift): shift the image horizontally or vertically by a certain step;
- Resize: enlarge or reduce the image;
- Random Crop or Pad: Randomly crop or pad the image to a specified size
- Color jittering: The HSV color space randomly alters the original image
饱和度和明度(ie, changes the values of the S and V channels) or色调(Hue)makes small adjustments to it.
- Add Noise: Add random noise.
- Special data augmentation methods:
- Fancy PCA (Alexnet) & Supervised Data Augmentation (Hikvision)
- Generate simulated images using Generative Adversarial Networks (GANs)
- The principle of using HSV to adjust the image color:
- Usually we think of using the RGB value of the image to judge its color, but the color of the image is determined by these three values together, only one component (such as the blue component) is fixed, and it is difficult to adjust the ratio of the other two components. It must appear blue. And HSV is very suitable for the problem of image color judgment. Among them, H(ue) represents the hue, and the value range is: , the red is , the green is , the blue is ; S(aturation) represents saturation, the value range is: , the larger the value, the more saturated the color; V(alue) represents the brightness, and the value range is: , the larger the value, the brighter the color.
- Hue (H) is the only variable related to the nature of color in the HSV color model, so as long as the value of H is fixed, and the saturation (S) and lightness (V) components are kept not too small, the color expressed can be basically determined . As shown in the figure below, when we fix
, as long as both saturation (S) and lightness (V) are greater than
, then we can think that the color of the box is blue.




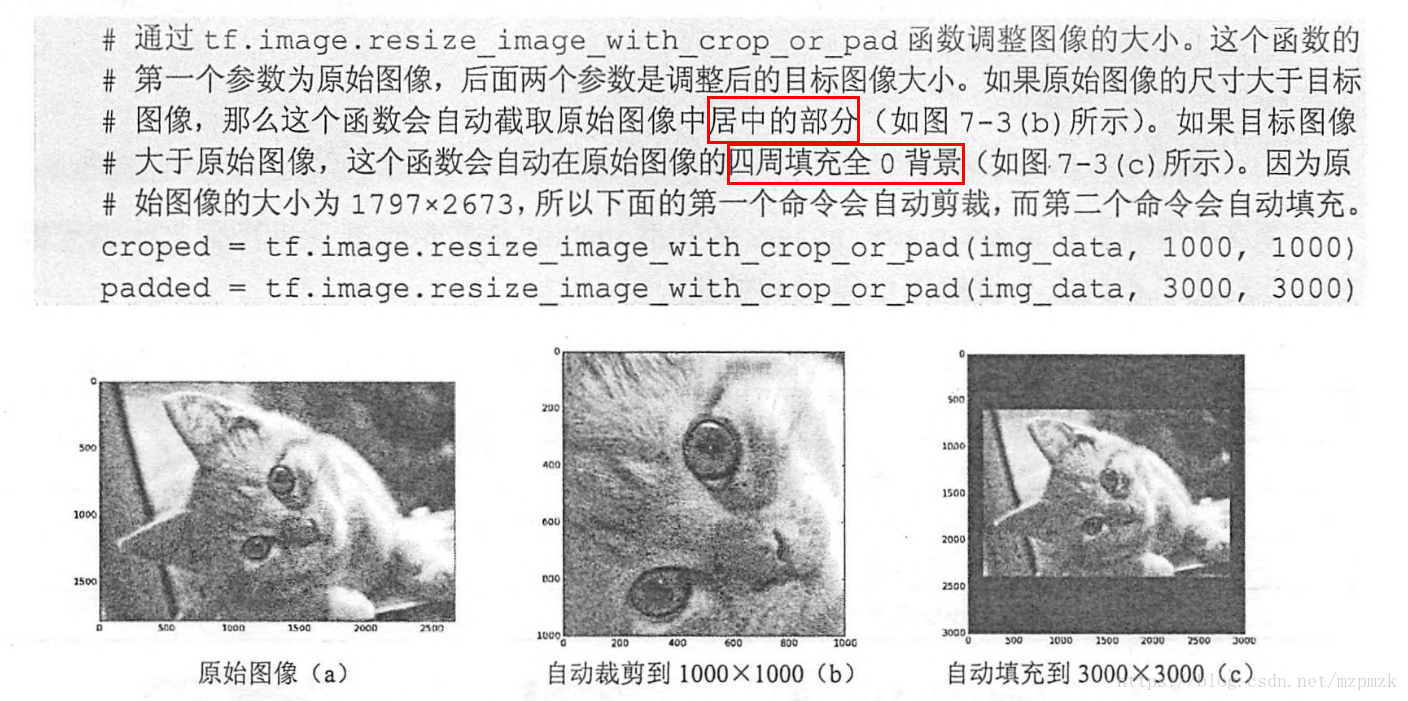
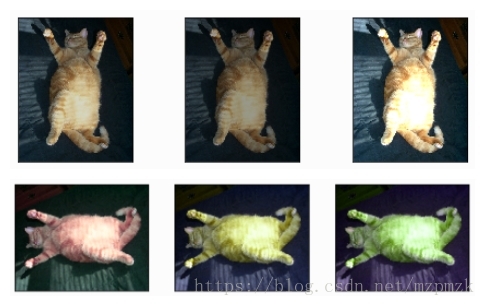
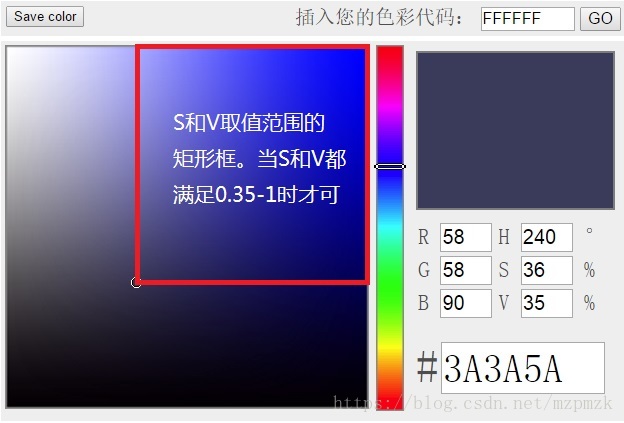
2. Data preprocessing
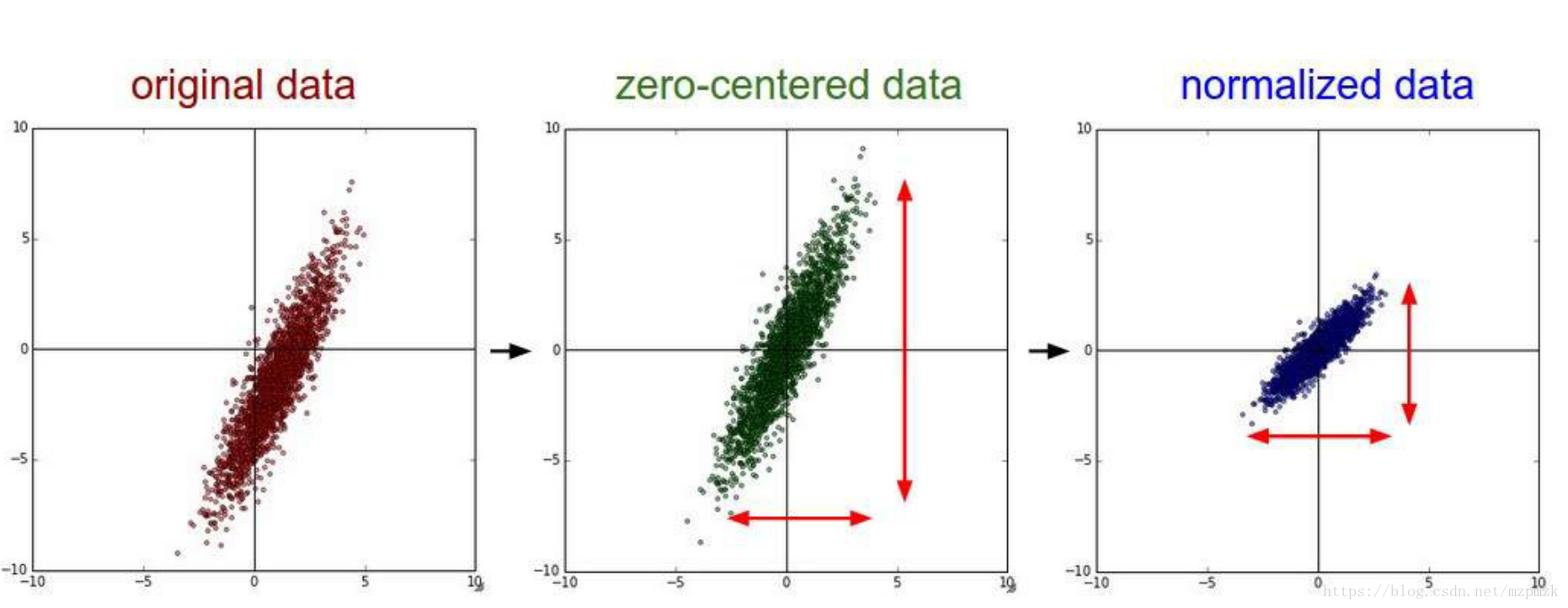
- In image processing, each pixel information of an image can be regarded as a feature. It is very important to subtract the average value of each feature to centralize the feature, which can speed up the convergence of the model, as shown in the following figure:
注意:Usually , the mean of the training set image pixels is calculated , and then the mean needs to be subtracted separately when processing the training set, validation set, and test set. In practice, direct减去 128 再除以 128or direct标准化processing is fine.- For the code implementation of unitization, normalization, and standardization, see the blog: MATLAB data matrix unitization, normalization, and standardization.
- The process of de-averaging and normalization is shown in the following figure:
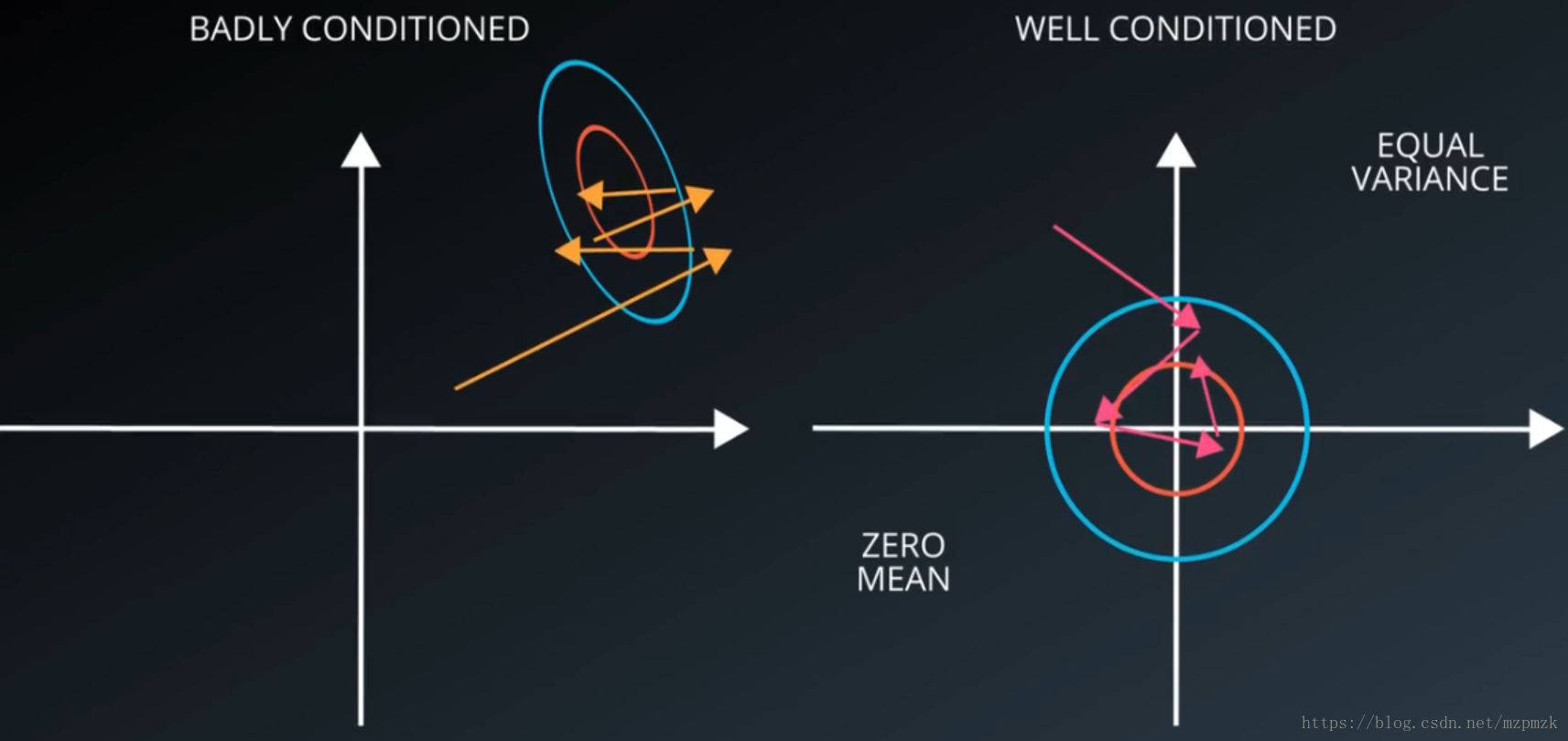

3. References
1. Gluon: Image
Augmentation 2. Introduction to YJango’s Convolutional Neural Network
3. EasyPR – Detailed Explanation of Development (5) Color Positioning and Skew Torsion