1. Installation of Anaconda environment.
Go to the official website ( click here ) to download the corresponding Anaconda installation package. Anaconda has Python 2.7 and Python 3.6 versions. I downloaded the Python 3.6 version here. Anaconda integrates Python software. After installing Anaconda, there is no need to install Python.
Download the .exe file and click Install. Select the corresponding installation directory, and the others can be installed by default.
2. Pycharm installation.
Go to the official website ( click here ) to download the corresponding Pycharm installation package. The community edition is free.
After downloading the .exe installation file, select the installation directory and install it directly by default.
3. Configure Pycharm + Anaconda development environment
Open Pycharm after installing Pycharm.

Click on Configure -> Settings
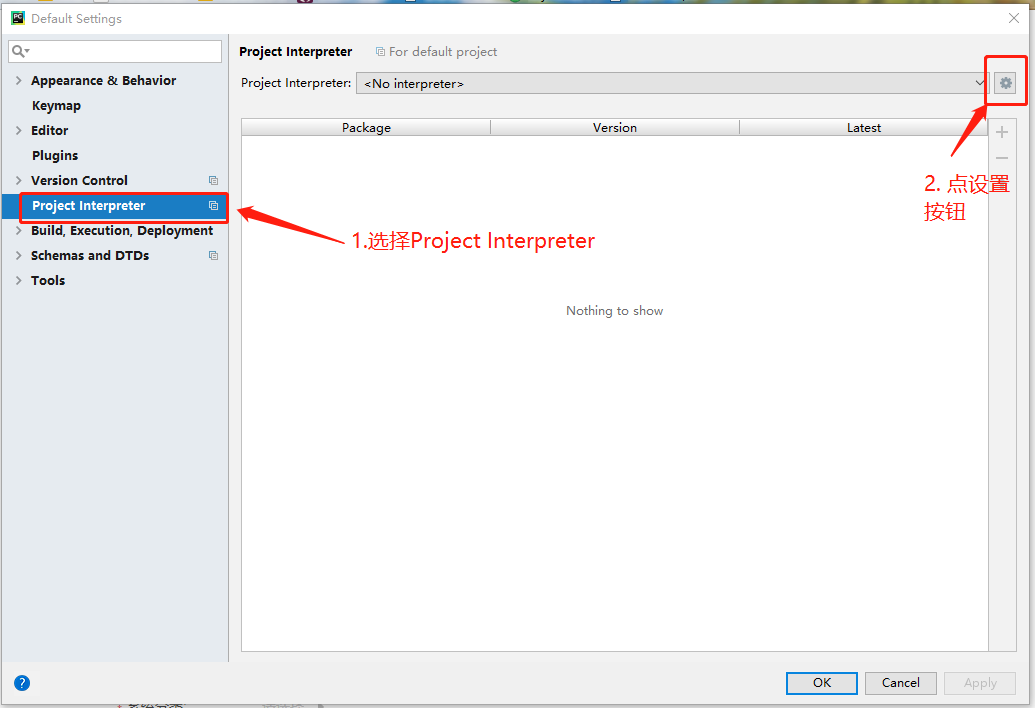
Select Add local -> Conda Environment, if Anaconda installation is not found appears, open CMD as an administrator, and enter the following command:
mklink /D %HOMEPATH%\anaconda C:\ProgramData\Anaconda3 (red is the corresponding Anaconda installation directory, see here for details )
After selecting the Anaconda environment, click OK, an Anaconda environment will be created,
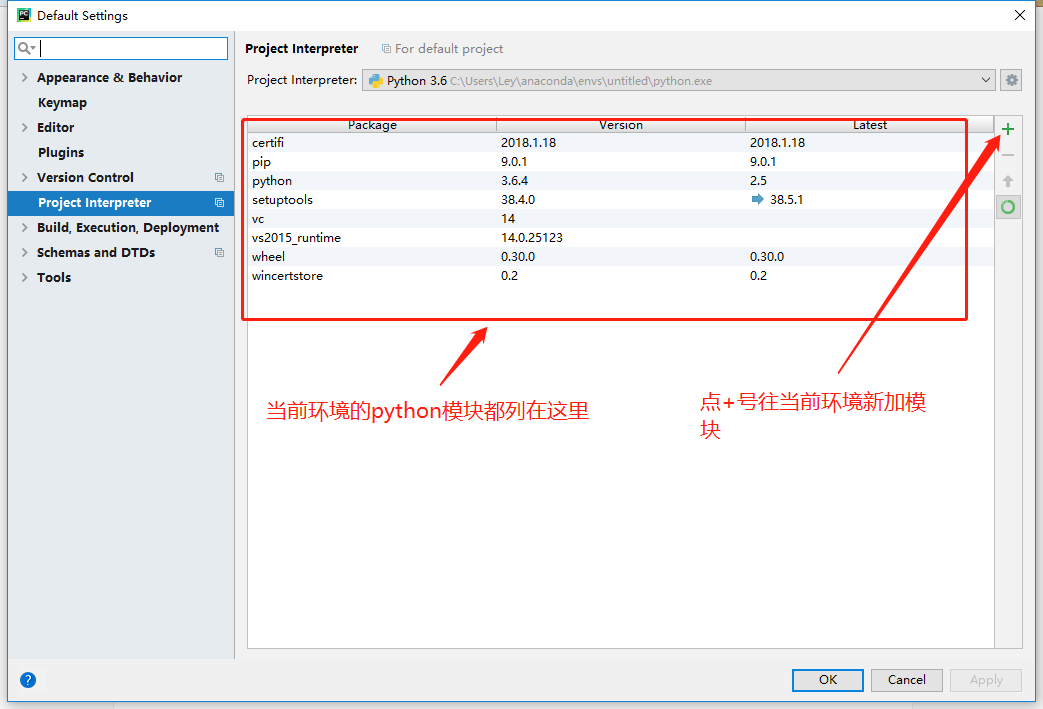
At this point, the Anaconda + Pycharm installation configuration is complete.
4. JDK installation
Go to the official website ( click here ) to download and install the corresponding version of JDK, download the installation package and select the corresponding installation path to install.
After installing jdk, configure the environment variables, right-click on the desktop [Computer] - [Properties] - [Advanced System Settings], then select [Advanced] - [Environment Variables] in the system properties, and then find in the system variables. "Path" variable, and after selecting the "Edit" button, a dialog box will appear, in which you can add the path name of the bin folder under the JDK directory installed in the previous step:
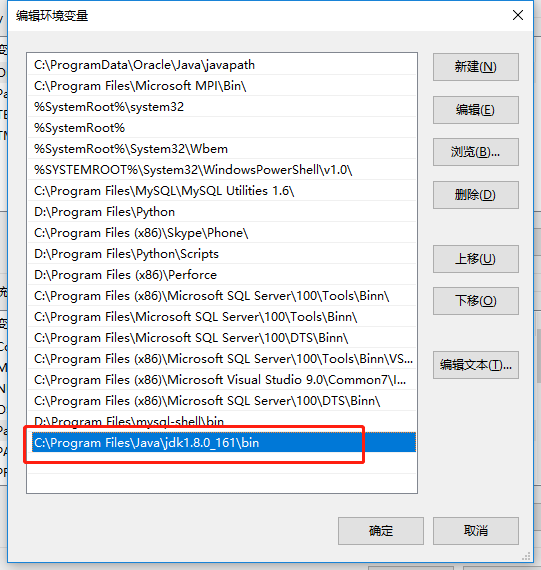
Test the java installation, create a new CMD window, enter java -version, the java version information as shown in the figure below appears, the installation is successful

5. Install Spark
Go to the Spark official website ( click here ) to download the corresponding Spark installation package, pay attention to the selected Spark version and its corresponding Hadoop version
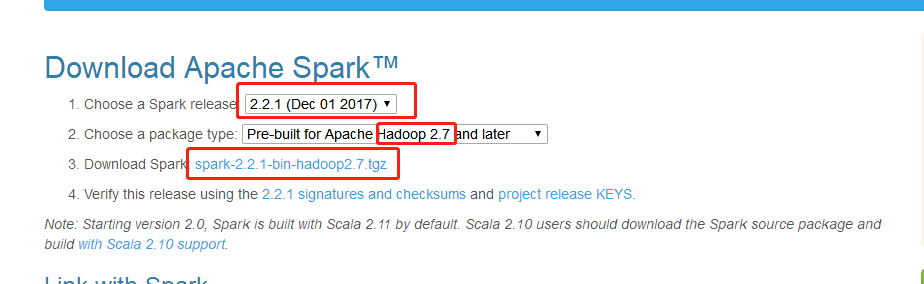
Here is Spark 2.2, Hadoop 2.7, click to download the compressed package. After downloading, you will get a compressed file like the following, and decompress it with decompression software:
![]()
Rename the extracted folder to Spark, copy the folder to the directory you want, I copied it to the root directory of the D drive.
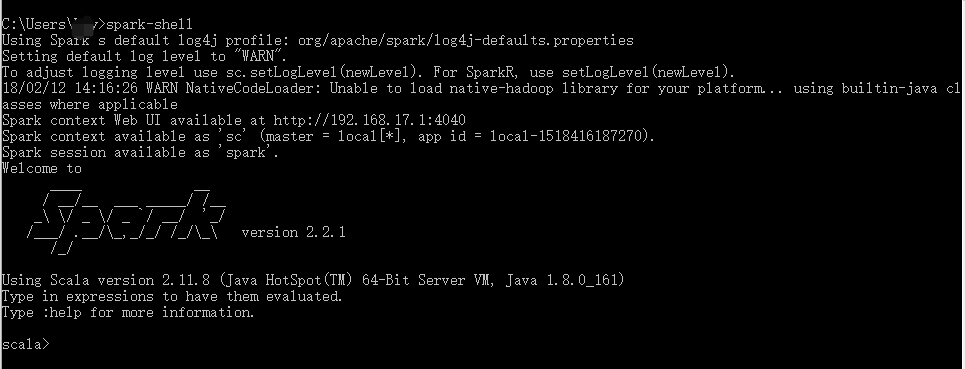
Add Spark's bin directory to the system variable PATH, open the command line and enter spark-shell, and the following message appears indicating that the Spark installation is successful.
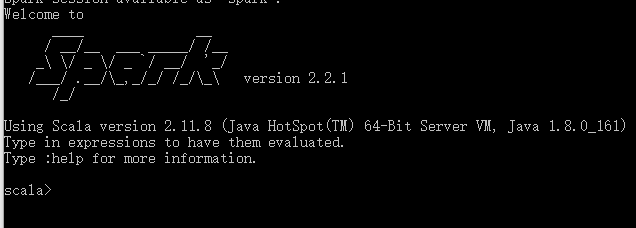
6. Hadoop installation
Go to the official website ( click here ) to download the corresponding Hadoop version. The Hadoop version corresponding to Spark was 2.7 before, so we choose version 2.7.1 to download.
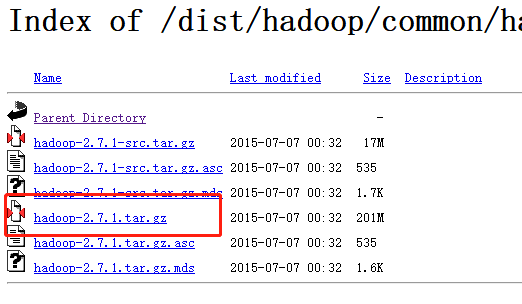
After downloading the installation package, unzip the installation package, change the folder name to hadoop, and add the bin directory of hadoop to the system variable path like Spark.
7. Configure the Spark environment
Entering spark-shell in the CMD window will report the following error, because there is no winutils.exe file in the bin directory of Hadoop.

Go to GitHub to download the winutils.exe file corresponding to the Hadoop version. I choose the winutils.exe file of version 2.7.1, and put it in the bin directory of Hadoop after downloading.
Entering spark-shell will report the following python error.

Python is also added to the system variable path, pointing to the Python executable file of Anaconda.
Open the command line and enter pyspark
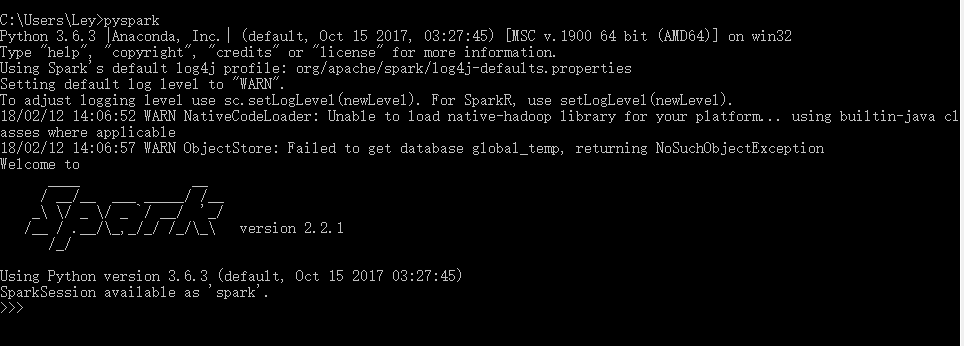
Finally, summarize the environment variables.
1. Add a new system environment variable:
HADOOP_HOME D:\hadoop
SPARK_HOME D:\spark
2. Add the following variables to the system environment variable path:
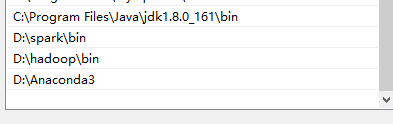
Open cmd, enter spark-shell, the perfect picture is as follows:
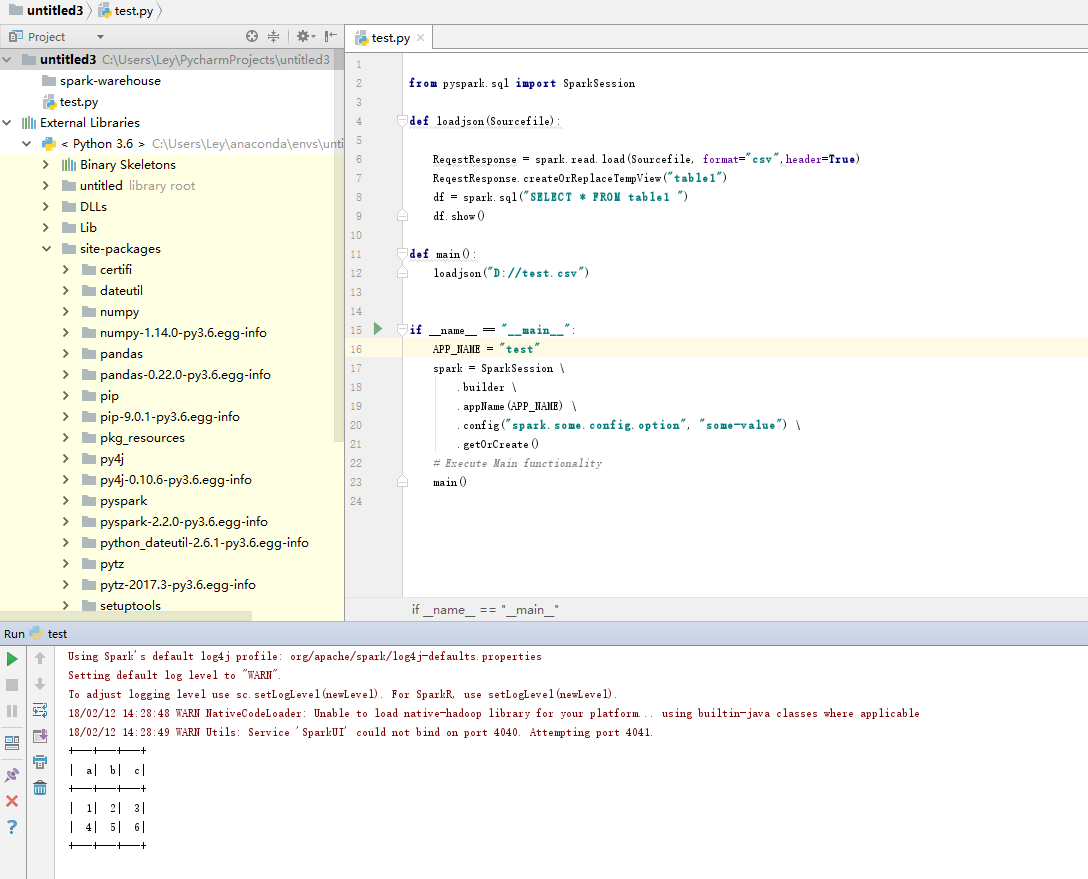
Finally, you can open Pycharm, import the pyspark module, and start playing with the python version of Spark
test: