The second blog assignment has been submitted. The students have made a detailed summary of the previous three code assignments in their own unique tone, which is very interesting. Is there anything interesting in common between these blog posts? I decided to send a little spider to find out. I crawled the second blog assignments of all my classmates, segmented the vocabulary based on text analysis, conducted word frequency statistics, and finally drew a cloud map based on the statistical results. It seems that the blog garden is still very friendly to crawlers. As a novice spider, I clumsily crawled around and tried many times without using a proxy, and I did not encounter any obstacles along the way.
Show results
class work
The cloud map drawn for everyone's work according to the word frequency is as follows:

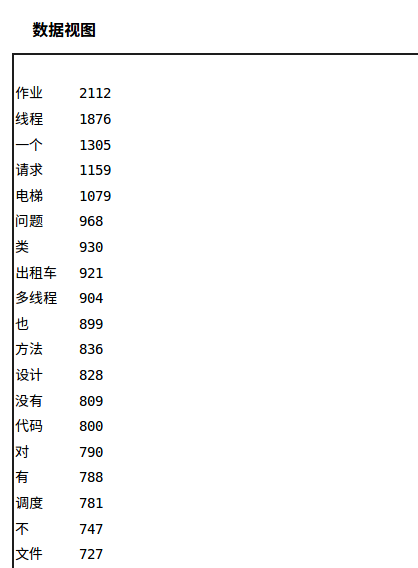
It can be seen that the word that appears the most is "homework", which appears 2112 times in more than 200 blogs. Only followed by "thread", which appeared 1876 times, and the similar word "multithreading" appeared 904 times. The main body of the three operations, "elevator" appeared 1079 times, "taxi" appeared 921 times, and "document" appeared 727 times. It can also be seen that everyone likes to discuss the fifth operation multi-threaded elevator.
In addition, words that appear less frequently are more individual words that everyone uses (because they are crawled page by page directly from the blog directory, some words that are obviously not related to the homework come from articles that are not in this homework but in the class blog directory) , take a small part here, if you are interested, you can click the data view to view it. (Can't guess why the word "eat" appears 5 times...)

personal work
I did a little analysis for my own blog by myself:

The results are amazing, the word I use the most is not "thread" nor "multi-threading", but "one", a full 26 times, this may be mineOneMore redundant speaking habits, should pay more attention in the future. In addition, the words I use more are "file" (21), job (19), scheduling (16), object (15), maybe I am not satisfied with the sixth assignment, so I discussed it at length. 'IFTTT', "document" appears more frequently, while "elevator" and "taxi" appear less frequently.
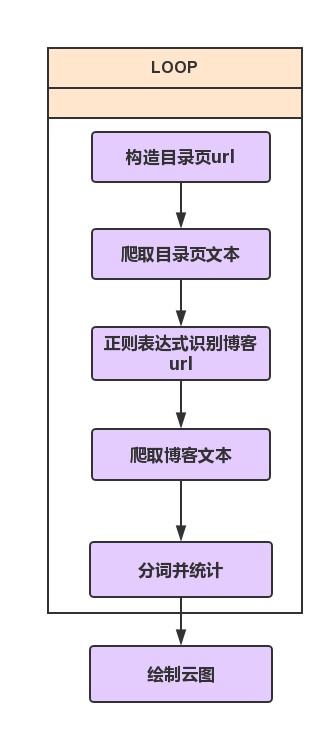
Realize ideas
The whole process is shown in the figure below:
Reference Code
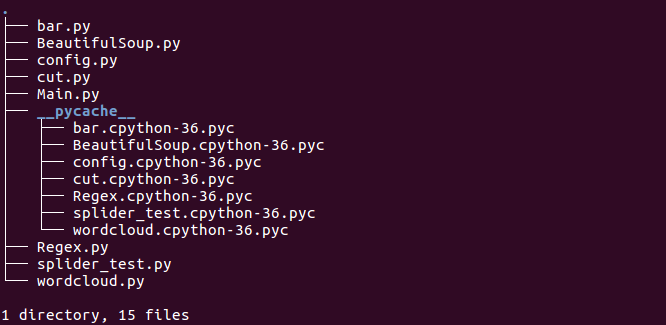
Directory Structure
The complete directory structure of the program is as follows:
Main
The main function code is as follows:
# -*- coding:utf-8 -*-
import splider_test
import BeautifulSoup
import config
import Regex
import wordcloud
def home_handle(home_url,dic):
list_blog = BeautifulSoup.home_parse(home_url)
for url in list_blog:
if (Regex.url_judge(url)):
print("Begin handling:\t", url)
str_html = splider_test.splider(url)
BeautifulSoup.parse(str_html,dic)
home_base = 'https://edu.cnblogs.com/campus/buaa/OO2018'
dic = {}
for i in range(1,24):
home_url = ''
if(i==1):
home_url = home_base
else:
home_url = home_base+"?page="+str(i)
home_handle(home_url,dic)
list_sort = sorted(dic.items(), key=lambda e: e[1], reverse=True)
list_word = []
list_count = []
config.trans(list_word,list_count,list_sort)
wordcloud.draw(list_word,list_count)Among them, the directory page to get the url of everyone's blog uses the "latest blog post" of the class page. I found that the front of the url of each page is unchanged, but the page parameters behind it have changed, so it is easy to use a for loop. The url of all directory pages is constructed.
BeautifulSoup
When I was about to give up writing regular expressions, I found this bowl of BeautifulSoup. It is an HTML parsing library that can be used to easily extract data from web pages. The functions are so powerful that it makes people move. Since I used it just yesterday, I won't introduce it here. Interested students can search for it by themselves.
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import cut
import re
import splider_test
import Regex
def parse(str_html,dic):
soup = BeautifulSoup(str_html, "lxml")
for p in soup.find_all(name="p"):
if(p.string!=None):
string = re.sub('[\s+\.\!\/_,$%^*(+\"\'):-;|]+|[+——!,。?、~@#¥%……&*():;]+','',p.string)
string = re.sub(u'的|我|在|了|是|和|就|中','',string)
count(dic,string)
def count(dic,string):
str_list = cut.cut_str(string)
for item in str_list:
if item in dic:
dic[item]+=1
else:
dic[item]=1
def home_parse(url):
list_url = []
str_html = splider_test.splider(url)
soup = BeautifulSoup(str_html,'lxml')
list_h3 = soup.find_all(attrs={'class':'am-list-item-hd'})
for item in list_h3:
list_url.append(Regex.url_match(str(item)))
return list_urlSome frequently occurring punctuation marks and Chinese function words are filtered out when parsing the text.
cut
Chinese word segmentation I use a Chinese word segmentation component called "Jaba" . I have to feel the power of python again. I only wrote two lines of code for such a complex task of dividing Chinese words, which is so short that I am a little embarrassed hahaha .
# -*- coding:utf-8 -*-
import jieba
def cut_str(string):
return jieba.lcut(string)Regex
Regular expressions are used to assist BeautifulSoup in identifying urls.
# -*- coding:utf-8 -*-
import re
def url_match(string):
REGEX = 'http:.*?html'
result = re.search(REGEX,string,re.U)
return result.group()
def url_judge(string):
REGEX = 'http:.*?html'
if(re.match(REGEX,string,re.U)):
return True
else:
return Falsewordcloud
The cloud map is drawn using pyecharts, which is a class library for generating Echarts charts. Echarts is a data visualization JS library open sourced by Baidu, which is mainly used for data visualization.
# -*- coding:utf-8 -*-
from pyecharts import WordCloud
def draw(list_word,list_count):
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", list_word, list_count, word_size_range=[20, 100])
print("wordcloud succeed!")
wordcloud.render("WordCloud.html")Improvement direction
- Because it is written for fun, the writing is relatively rough. For example, the crawler is easy to fail, but the code does not perform any exception handling. If you encounter a less friendly website, it may not be smooth.
- Some of the most frequently occurring Chinese function words and punctuation were manually filtered, but some function words (“also”, “but”, “also”, etc.) still remained. How to identify function words and content words is a problem.
- It can be seen that the blog reading volume of most students is distributed in the [10, 20] interval, but there are some blogs with a high reading volume. In addition, the ratio of the number of likes to the reading volume can also be used as a parameter. In the next step, I hope to pass Crawl the number of views and likes to find more popular blogs, and then perform word frequency analysis on these blogs.