data structure
pg_interval_t{
vector<int32_t> up, acting;//The current pg_interval up and acting osd list
epoch_t first, last;//The start and end epoch of the interval
bool maybe_went_rw;//Whether there may be data read and write at this stage
int32_t primary;//主osd
int32_t up_primary;//The main osd of the up state
}
PriorSet {
Const bool ec_pool;//Whether it is ec pool
set<pg_shard_t> probe; //Need probe's osd
set<int> down; //Currently down osd
map<int, epoch_t> blocked_by; //The osd that causes pg_down to be true and the epoch of the corresponding osdmap
bool pg_down; //whether pg is down
boost::scoped_ptr<PGBackend::IsRecoverablePredicate> pcontdec;//A function pointer to determine whether pg is recoverable
}
pg_info_t {
spg_t pgid;//pgid and shardid information
eversion_t last_update; // last object version applied to store. The latest update of the current osd
eversion_t last_complete; // last version pg was complete through. The version number to ensure that all osds are updated
epoch_t last_epoch_started;// last epoch at which this pg started on this osd // epoch after the latest one becomes active
version_t last_user_version; // last user object version applied to store
eversion_t log_tail; // oldest log entry.
hobject_t last_backfill; //The object pointer of backfill, the normal case is hobject_t::get_max()
interval_set<snapid_t> purged_snaps;
pg_stat_t stats;//Statistics
pg_history_t history;//Historical version
pg_hit_set_history_t hit_set;//cache tier相关
};
pg_log_t{
eversion_t head; // latest pg_log_entry version
eversion_t tail; // the oldest pg_log_entry
iteration_t can_rollback_to;//The version that can be rolled back
eversion_t rollback_info_trimmed_to;//The version of the rollback scene that can be trimmed
list<pg_log_entry_t> log; //Specific pg_log_entry information
};
pg_missing_t {
map<hobject_t, item> missing;//Lost object and version
map<version_t, hobject_t> rmissing;
};
class MissingLoc {
map<hobject_t, pg_missing_t::item> needs_recovery_map;//Object and version information to be recovered
map<hobject_t, set<pg_shard_t> > missing_loc;//Indicates which osd the object exists on
set<pg_shard_t> missing_loc_sources;//There is an osd list of missing objects
PG *pg;
set<pg_shard_t> empty_set;
};
Profiling
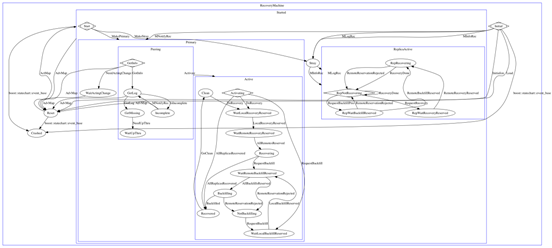
Overall state transition diagram of Pg state machine
Interaction diagram during Peering
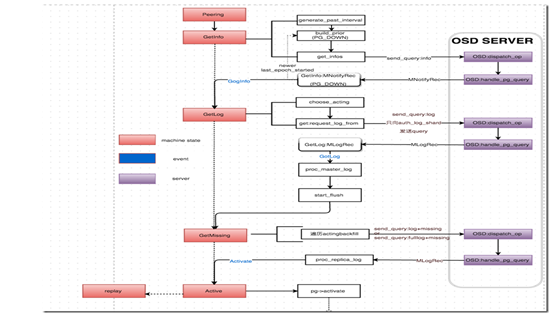
Overall, peering is divided into 4 stages: Getinfo, Getlog, Getmissing, Active. If necessary, there will be a waitupThru after getmissing.
Getinfo: pg's main osd collects other information from pg_info_t on osd.
GetLog: Select the osd with the authoritative log. If it is not the master, pull the authoritative log from the osd to the master osd.
GetMissing: The main osd pulls pg_entry_t from other osds, and judges the missing object information on each osd by comparing pg_entry_t with the authoritative log.
Active: activate master osd and slave osd
basic concept
Temporary PG, acting set and up set
The acting set is the osd list corresponding to pg, and the first one in the list is the main osd. In general, the acting set and the up set are the same. Suppose the acting of a pg is [1, 2, 3]. When 1 hangs, up is [4, 2, 3]. At this time, since 4 is the osd newly added to the pg, there is no data on it, and it needs to be backfilled. At this time, a temporary pg will be generated. Then up is [4,2,3]. But acting is still [2,3].
Up_thru
Simple example: when the osd list corresponding to a pg is [1, 2], min_size is 1. When osd.1 and osd.2 hang up in sequence, there may be two situations:
Case 1: osd.1 hangs, osd.2 has not completed the peering stage, and osd.2 hangs immediately. At this time, data cannot be written to osd.2.
Situation 2: osd.1 hangs up, and osd.2 hangs up after completing peering and entering active. At this time, there is a time window for the pg to write data normally.
When osd.1 restarts, if it is case 1, because no new data is written, pg can finish peering normally. If it is case 2, it is possible that a part of the data exists only on osd.2, and peering cannot be completed.
In order to distinguish between case 1 and case 2, up_thru is introduced. up_thru records the epoch value of each osd completing peering, and osdmap maintains an array of up_thru[osd].
After the introduction of up_thru, it is assumed that the initial up_thru is 0. Then up_thru[osd.2] is 0 in case 1, and up_thru[osd.2] is not 0 in case 2.
Osdmap maintains osd_info information, which contains up_from and up_thru. The epoch between up_from and up_thru cannot write data.
past_interval
Indicates a continuous sequence of epochs in which the acting and up of the pg have not changed. E.g:
| epoch |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| invalid osd |
|
Osd.3 |
Osd.4 |
Osd.5 |
Osd.2 |
Osd.10 |
Osd.11 |
Osd.12 |
Osd.13 |
| up |
[0,1,2] |
[0,1,2] |
[0,1,2] |
[0,1,2] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
| acting |
[0,1,2] |
[0,1,2] |
[0,1,2] |
[0,1,2] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
|
|
Past_interval |
Current_interval |
Statechart state machine
State: inherits boost::statechart::state. There are 2 states:
The first is a state with no substates. E.g:
struct Reset : boost::statechart::state< Reset, RecoveryMachine >, NamedState
When entering this state, the constructor is called directly.
The second is a state with substates. E.g:
struct Started : boost::statechart::state< Started, RecoveryMachine, Start >, NamedState
struct Start : boost::statechart::state< Start, Started >, NamedState
Indicates that Start is the first substate of Started. If it enters the Started state, it will enter the Start state
Event: inherit boost::statechart::event. E.g:
struct MakePrimary : boost::statechart::event< MakePrimary >
Status response events:
It is roughly divided into 3 types:
boost::statechart::transition< NeedActingChange, WaitActingChange >
Indicates that the NeedActingChange event is received, and the WaitActingChange state is entered. Generally, the event is delivered through the post_event method.
boost::statechart::custom_reaction< ActMap >
This generally has a boost::statechart::result react(const ActMap&) method corresponding to processing events
boost::statechart::custom_reaction< NullEvt >
NullEvt does not have a corresponding react method to handle it, and does nothing. Generally, it is only used for scheduling in the process.
Main process
Started/Primary/Active to peering state transition
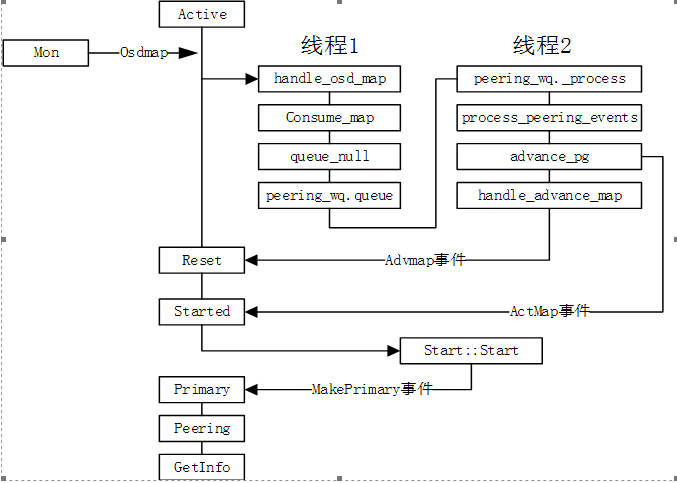
When there is an osd failure or startup, it will cause the osdmap to change. The main osd corresponding to the pg will receive the osdmap information sent by the mon. When the advmap event is delivered, it enters the reset state.

In the reset state, when the Actmap event is delivered and enters the Started state, it directly enters the first sub-state Start of Started. If it is judged in the constructor that the current osd is the main pg of the osd, the MakePrimary event is delivered and the primary state is entered. So enter the GetInfo state
GetInfo process
The core functions of GetInfo are all done in the constructor. It mainly contains 3 functions:
generate_past_intervals: Calculate the value of past_intervals.
1) Call _calc_past_interval_range to infer the start and end ranges of epochs for all past_intervals.
Start value: the epoch of the last pg clean state, the epoch created by pg, and the larger value of the epoch of the oldest osdmap.
end value: generally the epoch of the current osdmap.
2) Traverse the historical osdmap according to the start and end values. The past_intervals value is obtained by comparing adjacent osdmaps in turn. Pay attention to the judgment of maybe_went_rw here.
build_prior: build osd list based on current acting, up and past_intervals
1) Add the current acting and up osd to the probe's osd list.
2) Traverse each pg_interval_t in past_intervals in reverse order. If interval.last is less than info.history.last_epoch_started, it means that this interval is before the last peering, and break directly. If acting is empty, or no data is written for this interval, continue. Traverse the osd in the acting list of the interval. If the osd is up in the current osdmap, it will be added to the probe and up_now, otherwise it will be added to the down list. Use pcontdec to determine whether the current pg is in the down state. In the multi-copy scenario, pcontdec is true as long as there is one up_now in the multi-copy scenario, and true if more than or equal to M up_nows exist in the ec scenario.
3) Determine whether to perform the up_thru operation. If the up thru of the osd in the current osdmap is smaller than the epoch of the latest osdmap, it needs to be updated.
4) Send pg_query_t to osd of all prior_set.probe, and save the information of sending osd in GetInfo.peer_info_requested and pg->blocked_by.
5) The Pg master osd receives the information returned by other osd and calls handle_pg_notify. To post the MNotifyRec event, call boost::statechart::result PG::RecoveryState::GetInfo::react(const MNotifyRec& infoevt).
a. Remove the corresponding osd from peer_info_requested and pg->blocked_by
b. Call proc_replica_info to process the pg_info_t information of each replica.
1. Check that there is already pg_info_t information in peer_info (peer_info information will be cleared when it is in the Reset state), if there is, return false directly, otherwise save it to peer_info
2. Make pg not in the operation queue of osd's scrub.
3. Merge from the history of osd pg to this pg info.history. The update method is to use the largest epoch. dirty_info is true if there is an update.
4. If the osd of from is not in the current up and acting list, put it in stray_set, and call purge_strays to clean the data after pg clean.
5. Update PGheartbeat_peers, if you need to update, set OSD.heartbeat_need_update to true.
c. If the new pg.info.history.last_epoch_started is larger, it means that there is an updated last peering version from the osd. At this time, the priority_set needs to be rebuilt. The purpose is to remove the osd that is not allowed to probe from the peer_info_requested, so that it can be faster Fire the GotInfo event.
d. When peer_info_requested is empty, that is, all pg_info_t are saved in peer_info. Traverse past_intervals in reverse order, and the osd of the acting list in the specific interval, at least one osd must be in the up state and not in the incomplete state, otherwise the pg is set to the down state.
e. Deliver the GotInfo event and enter the GetLog state
GetLog status flow
The core functionality of GetLog is also done in the constructor.
1) Call choose_acting to choose an osd for authoritative logs. The whole choose_acting to do includes:
1. Select an osd of an authoritative log
2. Fill the fields of pg: actingbackfill, want_acting, backfill_targets
a. Call the find_best_info function to select an osd of the authoritative log from peer_info.
1. Calculate the largest last_epoch_start in all peer_info, and the smallest last_update in the case of the largest last_epoch_start, as min_last_update_acceptable.
2. Filter out the case where last_update is smaller than min_last_update_acceptable, last_epoch_started is smaller than max_last_epoch_started_found, and pg is incomplete.
3. If the pg is the pg of the ec pool, choose the smaller last_update, and if it is multiple copies, choose the larger last_update. Try to choose the smaller log_tail, that is, with more logs, and finally choose the main one as much as possible.
In summary. The conditions to be met by the osd of the authoritative log:
last_epoch_start must be the largest and must be a non-incomplete osd, and last_update must be greater than or equal to min_last_update_acceptable. Then the most logged, or the master.
b. If find_best_info does not elect the osd of the authoritative log, and up is not equal to acting, add pg to pg_temp_wanted and apply for a temporary PG. Finally choose_acting returns false
c. If the osd of the authoritative log is incomplete, you need to select another osd of the authoritative log from the complete osd list in peer_info.
d. If all peer_info osds support the EC feature, compat_mode is true.
e. If it is a multi-replicated pool, call calc_replicated_acting. If it is an ec pool, call calc_ec_acting.
calc_replicated_acting:
The purpose of this function is to find the main osd and get the list of backfill and acting_backfill.
1. Select the main osd of pg, that is, the primary variable. If the last_update of the pg_info_t information of the up_primary (current primary) is greater than the log_tail of the authoritative log, that is, it overlaps with the authoritative log, then the primary is up_primary. Otherwise the osd of the authoritative log is the primary osd. Set the main osd to want_primary, and add the main osd to want and acting_backfill.
2. Traverse the pg_info_t information of the current up list. If last_update is less than MIN (primary->second.log_tail, auth_log_shard->second.log_tail) or incomplete, it means that the osd that needs backfill is added to backfill and acting_backfill. Otherwise, it is normal or the recovery osd is placed in acting_backfill.
3. Traverse the osd that exists in acting but does not exist in up. If such an osd exists and overlaps with the authoritative log, it will be added to acting_backfill.
4. Traverse the osd that exists in all_info but does not exist in up and acting. If such an osd exists, and the pg_info information overlaps with the authoritative log, add it to acting_backfill.
calc_ec_acting:
1. The initial vector<int> want size is ec pool size, and the initial value is CRUSH_ITEM_NONE
2. Traversing want is actually traversing up. If pg_info in up is not incomplete and last_update is greater than the tail of the authoritative log, add the osd in up to want.
3.Add other osd in up to the backfill list
4. The first osd in want is want_primary.
f. If the size of want is less than the min_size of the pool, choose_acting returns failure.
g. Construct set<pg_shard_t> have according to want. Call recoverable_predicate to determine whether it can be recovered
h. If want is not equal to acting, but want is equal to up. Then send a MOSDPGTemp message to mon to apply for a temporary pg, and return failure.
2) If the osd of the authoritative log is itself, directly deliver the GotLog event and enter the GetMissing state
3) If the osd of the authoritative log is not its own, update request_log_from to the last_update of the smallest peer_info and greater than the tail of the authoritative log. go to the authoritative log
4) The main osd receives the msg of the authoritative log, delivers the GotLog event, and calls boost::statechart::result PG::RecoveryState::GetLog::react(const GotLog&)
5) GotLog event processing, if there is msg, call proc_master_log to merge authoritative logs. Enter the GetMissing state after completion
a. Call PGLog::merge_log to merge authoritative logs. Enter information including authoritative log information oinfo and olog and the info information of this pg
|
|
From |
|
To |
|
|
| Authoritative log |
(20,2) |
(20,3) |
(20,4) |
(20,5) |
(20,6) |
| local log |
|
|
(20,4) |
(20,5) |
(20,6) |
1. If the tail of the authoritative log is smaller than the tail of the local log, it means that the local log is missing. Calculate the overlapping version number to of the authoritative log and the local log. Copy the missing log_entry_t of the local log from the authoritative log to the local, and update the log_tail of the local info to the log_tail of the authoritative log.
|
|
|
|
|
Divergence log |
|
| Authoritative log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
|
|
| local log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
2. If the head of the authoritative log is smaller than the head of the local log, the latest data exists in the local log. transfer
rewind_divergent_log to handle divergent logs.
a. First obtain the list of local divergence logs according to the head of the authoritative log, and update the info of the local log, the head information of the pglog, and the last_update information to the head of the authoritative log. Indicates that the divergence log needs to be trimmed
b. Classify the difference log according to the object, and put the pg_log_entry_t of the same object into a list.
c. Call _merge_object_divergent_entries to process the object's divergent log collection. Add all divergence logs to the transaction that joins the trim. 1) If the latest version of the object in the local log is greater than or equal to the first version of the divergent log, it means that the object has subsequent operations on the object. Delete this object, set have in the missing list to empty, and restore it through the missing list. There are some things I don't understand about this scene. 2) If the previous version of the divergence log is version_t or the first log is a clone log, it means that it is a creation log, and there is no need to restore it. It is directly deleted from the missing list, and the object is also deleted. 3) If the object is already in the missing list, and the previous version of the divergence log is already the have of the current item, indicating that the current version is the latest version, it will be removed from the missing list. Otherwise the item's need is the previous version of the divergence log. If the previous version of the divergence log is older than the oldest version of the log, it is processed separately. 4) 5) First determine whether there is a log that can be rolledback in the divergence log. If rollback is possible, it will be placed in the rollback queue, otherwise the object will be deleted and restored through the missing list.
|
|
|
|
|
from |
|
| Authoritative log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
| local log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
|
|
3. If the head of the authoritative log is larger than the head of the local log, the data of the local log is not new enough. First find the from point by traversing the authoritative log subsequently. Add authoritative logs starting from from to the local pg_log. At the same time, the object of pg_log_entry_t is added to the missing list.
|
|
|
|
|
from |
|
| Authoritative log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
(22,5)obj2 |
(22,6)obj2 |
| local log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
In the above figure, it is a special case that the head of the authoritative log is larger than the head of the local log. Put the local logs (20, 5) (20, 6) into the divergent log list, delete these divergent logs from the local log, and update the pg_log_entry of the authoritative log. These divergence logs are then processed according to the 5 rules for handling divergence logs in 2.
b. Update peer_info and peer_missing of the authoritative log osd to the local pg. Merge authoritative log history information into the local history information. After the entire proc_master_log is completed, enter the GetMissing stage.
GetMissing process
1) Traverse the pg_info_t information of the copy osd of the actingbackfill in the constructor. Among them, backfill and osd without missing objects are required to continue directly. The rest are the copy osd that needs to be recovered. If the last_epoch_started (the last active version number) of the pg_info information of the replica osd is greater than log_tail, it means that only some log objects need to be replied, so only the logs from last_epoch_start to log_head need to be pulled. Otherwise, all logs need to be recovered, and all logs will be pulled. At the same time, add the osd that needs to be pulled to peer_missing_requested.
2) If peer_missing_requested is empty, it means that there is no osd that needs to pull the log. Then directly enter the Active state.
3) If peer_missing_requested is not empty, wait for the replica osd to return the information of pg_log. When the copy information is returned, the MLogRec event will be delivered, and boost::statechart::result PG::RecoveryState::GetMissing::react(const MLogRec& logevt) will be called. where proc_replica_log is called to process the returned replica pg_log. And peer_missing_requested deletes the corresponding osd. When peer_missing_requested is empty, it means that the pg_log information of all replica osd has been returned, and it enters the Active state. Focus on how proc_replica_log handles the pg_log information of the replica osd
|
|
|
|
lower_bound |
Fromiter Divergence log |
Divergence log |
| replica log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
| Authoritative log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
|
|
|
|
|
|
lower_bound |
Fromiter
|
|
| replica log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
|
|
| Authoritative log |
(20,2) obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
a. First, find lower_bound and fromiter by comparing the information of the replica log and the authoritative log. The possible scenarios are the above two. If there are divergent logs, process divergent logs.
b. It is worth noting that the Missing information of the replica osd should be obtained in proc_replica_log, but it is not.
Active process
The main flow is done in PG::activate.
1) Update the information of pg_info, mainly the last_epoch_started field is the current epoch. last_update_ondisk is last_update, if pg's missing is empty, last_complete is last_update
2) If it is the master osd, the slave osd needs to be activated. 1. If the last_update of the slave osd is equal to the last_update of the master osd. It means that this slave osd is clean, added to activator_map, and then sent pg_info in do_infos to activate. 2. The osd that needs backfill sends the latest pg_info and pg_log_entry, and the peer_missing is cleared. 3. Need to recover the osd, send the latest pg_info and lost pg_log_entry, update peer_missing.
3) Set missing_loc, call add_active_missing to add missing and peer_missing oids to needs_recovery_map. needs_recovery_map only saves the correspondence between the missing object and pg_missing_t::item. Ultimately we also need the relationship between the missing object and osd. Traverse all osd, call add_source_info, to set missing_loc.
4) After receiving the reply from the replica osd, trigger the MInfoRec event and call boost::statechart::result PG::RecoveryState::Active::react(const MInfoRec& infoevt). Every time a piece of osd information is returned, peer_activated is inserted into osd information. When peer_activated is equal to actingbackfill, all_activated_and_committed is called, indicating that all osd return information is received. Post the AllReplicasActivated event.
5) boost::statechart::result PG::RecoveryState::Active::react(const AllReplicasActivated &evt) processes the events returned by all replicas. Clean and set the state of pg. Set history.last_epoch_started equal to pg's last_epoch_started. Call check_local to check if the deleted object is still there. Call ReplicatedPG::on_activate to trigger the recovery or backfill process.