This blog is used to record the bugs encountered when using pytorch. Although I am old, it is still exciting to call out the bugs ^_^!
BUG1:
When using the NLLLoss() activation function, NLLLoss is used for n-class classification. Generally, the last layer of the network is LogSoftmax, and if others need to use CrossEntropyLoss. Its usage format is: loss(m(input), target), where input is 2DTensor size (minibatch, n), and target is the label of the real classification.
If the input type of the input is torch.cuda.FloatTensor and the target type is torch.cuda.IntTensor, the following error will occur:
TypeError: CudaClassNLLCriterion_updateOutput received an invalid combination of arguments - got (int, torch.cuda.FloatTensor, !torch. cuda.IntTensor!, torch.cuda.FloatTensor, bool, NoneType, torch.cuda.FloatTensor), but expected (int state, torch.cuda.FloatTensor input, torch.cuda.LongTensor target, torch.cuda.FloatTensor output, bool sizeAverage, [torch.cuda.FloatTensor weights or None], torch.cuda.FloatTensor total_weight)
Therefore, it is necessary to ensure that the target type is torch.cuda.LongTensor, and it is necessary to convert the target type to int64-bit in the iteration of data reading: target = target.astype(np.int64), so that the output target type is torch. cuda.LongTensor. (or use to convert before using Tensor.type(torch.LongTensor)).
In order to illustrate the conversion relationship between numpy and toch in pytorch, the test is as follows:
First, convert the numpy array of int32 to torch, and get the IntTensor type
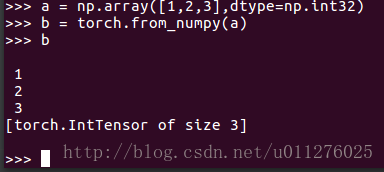
If the input is int64 numpy, get LongTensor type:
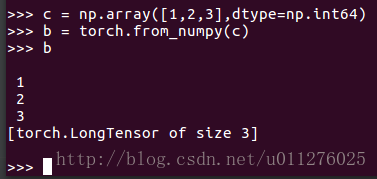
If you convert the array of int32 to LongTensor, you will get an error:

If the array of int64 is converted to LongTensor, it is normal:
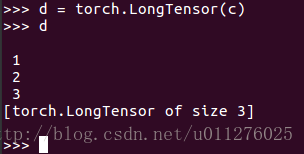
PS: 2017/8/8 (strangely, when using binary_cross_entropyfor classification, the type is required to be a FloatTensortype, which is enough)
BUG2:
It is also a problem when using NLLLoss(). The network propagation is normal, but the following error occurs when calculating the loss:
RuntimeError: cuda runtime error (59) : device-side assert triggered at /home/loop/pytorch-master/torch/lib/THC/generic/THCTensorMath.cu: 15
Breakpoint debugging found the following changes in the data type:

I thought the graphics card had nothing but a problem, and finally found a -1 in a person's tag in pytoch#1204 , a similar error occurred:

And my label is 1~10, and finally the label is defined as 1~9 to solve this problem. ^_^!
BUG3: RuntimeError: input is not contiguous at /home/loop/pytorch-master/torch/lib/TH/generic/THTensor.c:231
when usingtorch.view()
This is due to a problem with shallow copies.
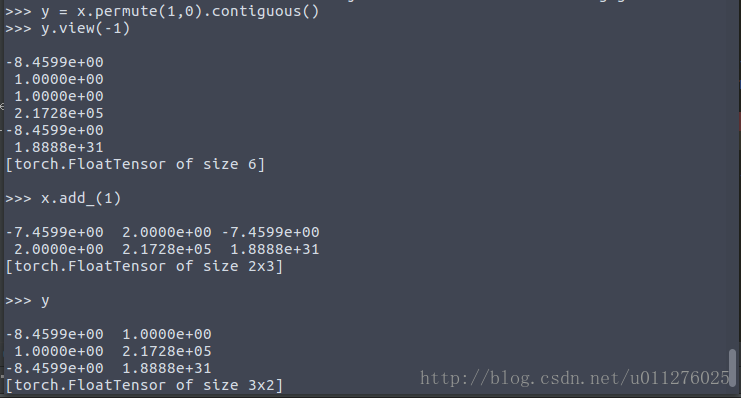
As follows: The definition initializes a Tensorvalue, and the dimension is exchanged, and Tensor.view()the above error occurs when the operation is performed.
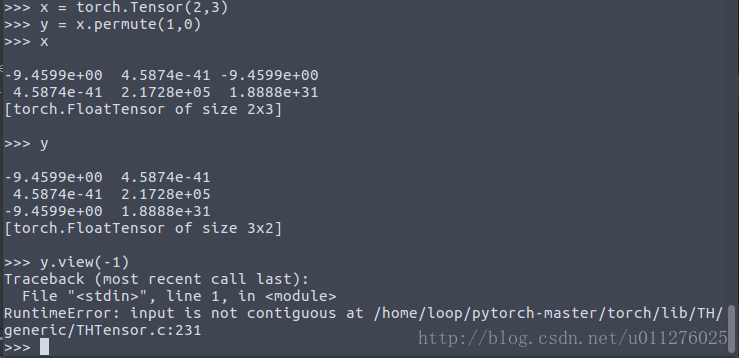
This is due to the shallow copy, yonly the copied xpointer, if xchanged, ywill also change, as follows:
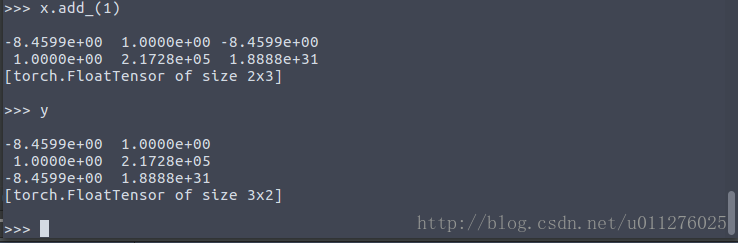
Can be tensor.contiguous()solved using:
BUG4: RuntimeError: multi-target not supported at … when
using loss functionCross_entropy
Look carefully at its parameter description:
input has to be a 2D Tensor of size batch x n.
This criterion expects a class index (0 to nClasses-1) as the target for each value of a 1D tensor of size nThe label must be 0~n-1, and it must be 1-dimensional. If the label is set to [nx1], the above error will also occur.
BUG4:
Appears when compiling the PyTorch source code according to the official website: undefined reference to ... @GLIBCXX_3.4.21 (未定义的引用问题)mine appears near the broadcast_test that compiles about 90% of the time. The problem is estimated to be caused by the version of GCC. Although GCC -v5.0 is displayed, the library called is not. It needs to be executed:
conda install libgccThen python setup.py cleanregenerate to solve the problem
BUG5:
The following error occurred:
ValueError: Expected more than 1 value per channel when training, got input size [1, 5,1,1]This is the calculation of one sample BatchNormthat cannot be set to 1 when used, resulting in the output of .batchsizey = (x - mean(x)) / (std(x) + eps)x==mean(x)0
NOTE1: Shared parameter problem
There is a way to implement parameter sharing in tensorflow variable_scope, that is to say, for 2 images, the weight parameters of the second image are the same as those used in the first image, see tf.variable_scope for details . Similarly, there is no such thing in PyTorch The problem, because the convolutional (or other) layers used in PyTorch first need to be initialized, that is, an instance needs to be created, and then the network is built using the instance, so the weights are shared when the instance is used multiple times.
NOTE2: torch.nn.Module.cuda role
In the previous tutorial, after defining the network, it will be done:
if gpu:
net.cuda()Only now I found out the role of this, the official document says: Moves all model parameters and buffers to the GPU.
That is to say, the parameters are not passed into the gpu when the definition is made weight. When calling the network for calculation, if the incoming data is GPU data, the error: tensors are on different GPUs will appear, so torch.nn.Module.cudathe defined network parameters can be passed. into the gpu.
NOTE3: Perform two consecutive gradient solutions on the same network (backward)
If you use one Variabledata input to the network, backwardsolve its gradient value, and then use another Variableinput network to solve the gradient value again, what will happen to the final result? As you can imagine, it is the sum of the two gradients . The test code is as follows:
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
def init_weigts(m):
classname = m.__class__.__name__
if classname.find('Linear') != -1:
m.weight.data.fill_(0)
m.bias.data.fill_(0)
net = nn.Sequential(nn.Linear(2, 2))
net.apply(init_weigts)
input = Variable(torch.FloatTensor(1, 2).fill_(1))
label = Variable(torch.FloatTensor(1, 2).fill_(1))
criterion = nn.MSELoss()
# compute first time network
net.zero_grad()
print('before backward')
print(net[0].bias.grad)
output = net(input)
loss = criterion(output, label)
loss.backward()
print('after backward1')
print(net[0].bias.grad)
# compute second time network
input2 = Variable(torch.FloatTensor(1, 2).fill_(1))
label2 = Variable(torch.FloatTensor(1, 2).fill_(1))
output2 = net(input2)
loss2 = criterion(output2, label2)
loss2.backward()
print('after2 backward1')
print(net[0].bias.grad)Define a one-layer linear network, and its weight (weight) and bias (bias) are initialized to 0, and the gradient value is output after each gradient solution. The results are as follows:
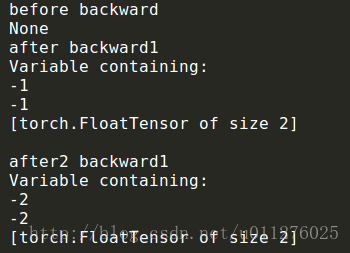
It can be found that there is no gradient before the gradient solution is performed. After the first calculation, the gradient is -1, and after the second calculation, it is -2. If the gradient is initialized after the first solution net.zero_grad(), it is always -1. , then successively solving the gradient for multiple times is the sum of multiple gradients.
NOTE4: PyTorch custom weight initialization
In the above NOTE3 , use custom weight parameters to initialize, use toch.nn.Module.apply()to initialize the defined network parameters, first define a weight initialization function, if the incoming class is the defined network, assign its weight in_place.
If weight_init(m)the classname in the pair is output, it can be found that there are multiple classes: (so it is necessary to judge whether it is the defined network)
Linear
SequentialNOTE5: Update of PyTorch weights
Regarding the definition of the network in the network transfer, the calculation of loss, and the calculation of backpropogate, update weight is briefly introduced in Neural Networks , and it is tested here. Just define an optimizer, implement common optimization algorithms, and then use the optimizer and computed gradients to update the weights.
Add the following after the code in NOTE3 (update the weight parameter):
print('before update parameters')
print(net[0].bias)
optimizer = optim.Adam(net.parameters(), 1)
optimizer.step()
print('after update parameters')
print(net[0].bias)The result of its operation is:
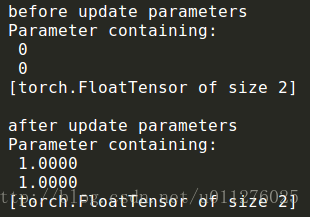
It can be seen that optimizer.step()the update of the network weight is realized by using. (And you can choose different update methods, such as: Adam, SGD, etc.)
NOTE6: torch.autograd.backward() Usage Tips
When computing multiple gradient additions (subtractions), use backward(torch.FloatTensor([-1]))can be implemented simply.
NOTE6: Monitor memory usage to prevent memory leaks
code show as below:
import gc
import resource
gc.collect()
max_mem_used = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
print("{:.2f} MB".format(max_mem_used / 1024))