The last article recorded the environment preparation before learning caffe and how to create the caffe version you need. This article records how to use the compiled caffe to train the mnist dataset, and the step numbers follow the order of the previous article " Practice Details - Compiling and Installing Caffe Environment (CPU ONLY) with VS2015 under Windows ".
Two: use caffe for image classification and recognition training and test mnist data set
1. Download the MNIST dataset . The MNIST dataset contains four file information, see the table:
| document |
content |
| Training set images - 55000 training images, 5000 validation images |
|
| Numeric labels corresponding to images in the training set |
|
| Test set images - 10000 images |
|
| The digital label corresponding to the test set image |
After downloading the MNIST dataset package, open \caffe root directory\examples\mnist and create a folder mnist_data in it. And extract its four data packages into this directory.
Note: These four files cannot be used directly for training and testing of caffe. You need to use the convert_mnist_data-d.exe file in the compiled caffe project to convert the four files into leveldb or lmdb files supported by caffe. The convert_mnist_data-d.exe file exists in the caffe root directory\scripts\build\examples\mnist\Debug or Release directory. The selection distinction depends on whether Debug or Release is selected at compile time.
2. Create a command script to call the convert_mnist_data.exe data conversion tool
2.1 In the caffe root directory, create a new convert-mnist-data-train.bat file for converting training data, and add the following code to the file:
scripts\build\examples\mnist\Debug\convert_mnist_data-d.exe --backend=lmdb examples\mnist\mnist_data\train-images.idx3-ubyte examples\mnist\mnist_data\train-labels.idx1-ubyte examples\mnist\mnist_data\mnist_train_lmdb pause
Note: scripts\build\examples\mnist\Debug\convert_mnist_data-d.exe This file is a tool for data conversion. If it is compiled with Debug, the file will be convert_mnist_data-d.exe If it is compiled by Release, it will be convert_mnist_data.exe document. Where --backend=lmdb means to convert to lmdb format, and the conversion data format set here determines the format corresponding to the modified configuration file in later use. To convert to leveldb, rewrite it to --backend=leveldb. The parameter after backend=leveldb is the file path of the decompressed dataset.
2.2 Create a new convert-mnist-data-test.bat to convert the test data, and add the following code to the file:
scripts\build\examples\mnist\Debug\convert_mnist_data-d.exe --backend=lmdb examples\mnist\mnist_data\t10k-images.idx3-ubyte examples\mnist\mnist_data\t10k-labels.idx1-ubyte examples\mnist\mnist_data\mnist_test_lmdb Pause
2.3 Run two script files to call transform test/train data
2.3.1 Run convert test data-convert-mnist-data-test.bat
Cut into the caffe root directory and Shift + right mouse button to select "Open command window here" and enter
start convert-mnist-data-test.bat
Call exception:
If the above situation occurs, most of it is caused by the encoding format of the folder. Because of UTF-8, a space is automatically added at the beginning of the text. The solution is very simple. The format can be modified to ANSI format.
D:\DeepLearning\caffe\caffe>锘縮cripts\build\examples\mnist\Debug\convert_mnist_ data-d.exe --backend=lmdb examples\mnist\mnist_data\t10k-images.idx3-ubyte examp les\mnist\mnist_data\t10k-labels.idx1-ubyte examples\mnist\mnist_data\mnist_test _lmdb System can not find the route. D:\DeepLearning\caffe\caffe>Pause
The call succeeded:
The following code is an example of successful conversion of command feedback
D:\DeepLearning\caffe\caffe>scripts\build\examples\mnist\Debug\convert_mnist_dat a-d.exe --backend=lmdb examples\mnist\mnist_data\t10k-images.idx3-ubyte examples \mnist\mnist_data\t10k-labels.idx1-ubyte examples\mnist\mnist_data\mnist_test_lm db I0427 09:47:11.591769 8508 db_lmdb.cpp:40] Opened lmdb examples\mnist\mnist_dat a\mnist_test_lmdb I0427 09:47:11.593770 8508 convert_mnist_data.cpp:93] A total of 10000 items. I0427 09:47:11.593770 8508 convert_mnist_data.cpp:94] Rows: 28 Cols: 28 I0427 09:47:11.983791 8508 db_lmdb.cpp:112] Doubling LMDB map size to 2MB ... I0427 09:47:12.180804 8508 db_lmdb.cpp:112] Doubling LMDB map size to 4MB ... I0427 09:47:12.514822 8508 db_lmdb.cpp:112] Doubling LMDB map size to 8MB ... I0427 09:47:13.059854 8508 db_lmdb.cpp:112] Doubling LMDB map size to 16MB ... I0427 09:47:13.225862 8508 convert_mnist_data.cpp:113] Processed 10000 files. D:\DeepLearning\caffe\caffe>Pause
2.3.2 Running Transform Training Data
start convert-mnist-data-train.bat
The call succeeded:
D:\DeepLearning\caffe\caffe>scripts\build\examples\mnist\Debug\convert_mnist_dat a-d.exe --backend=lmdb examples\mnist\mnist_data\train-images.idx3-ubyte example s\mnist\mnist_data\train-labels.idx1-ubyte examples\mnist\mnist_data\mnist_train _lmdb I0427 09:50:03.852622 8384 db_lmdb.cpp:40] Opened lmdb examples\mnist\mnist_dat a\mnist_train_lmdb I0427 09:50:03.854622 8384 convert_mnist_data.cpp:93] A total of 60000 items. I0427 09:50:03.854622 8384 convert_mnist_data.cpp:94] Rows: 28 Cols: 28 I0427 09:50:03.942627 8384 db_lmdb.cpp:112] Doubling LMDB map size to 2MB ... I0427 09:50:04.006631 8384 db_lmdb.cpp:112] Doubling LMDB map size to 4MB ... I0427 09:50:04.131639 8384 db_lmdb.cpp:112] Doubling LMDB map size to 8MB ... I0427 09:50:04.398653 8384 db_lmdb.cpp:112] Doubling LMDB map size to 16MB ... I0427 09:50:05.002688 8384 db_lmdb.cpp:112] Doubling LMDB map size to 32MB ... I0427 09:50:06.283761 8384 db_lmdb.cpp:112] Doubling LMDB map size to 64MB ... I0427 09:50:08.547890 8384 convert_mnist_data.cpp:113] Processed 60000 files. D:\DeepLearning\caffe\caffe>pause
After all data conversion is completed, you can find two more folders in the directory where the dataset files are stored, and there are two files in each folder, lock.mdb and data.mdb.
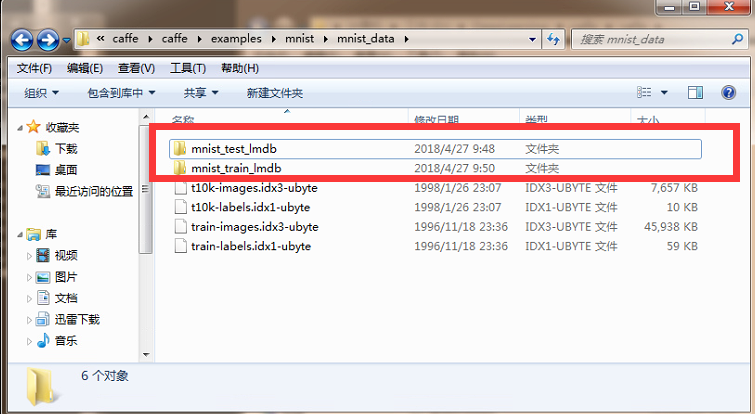
3. Run the test
3.1 Copy the converted test files and training files to the caffe root directory \examples\mnist folder as shown in the figure:

3.2 Write the call script
Create a new run.bat file in the caffe root directory, the code in the file:
D:\DeepLearning\caffe\caffe\scripts\build\tools\Debug\caffe-d.exe train --solver=examples\mnist\lenet_solver.prototxt pause
Note: D:\DeepLearning\caffe\caffe\scripts\build\tools\Debug\caffe-d.exe is best to use absolute path. Whether to use caffe-d.exe or caffe.exe depends on the way you compile. caffe-d.exe is stored under Debug, and caffe.exe is stored under Release directory.
3.3 Running the file
Just in case, as mentioned before, in step 2.1, the set conversion data format determines the format of the later call file, so we need to confirm whether the format in the lenet_train_test.prototxt file is consistent.
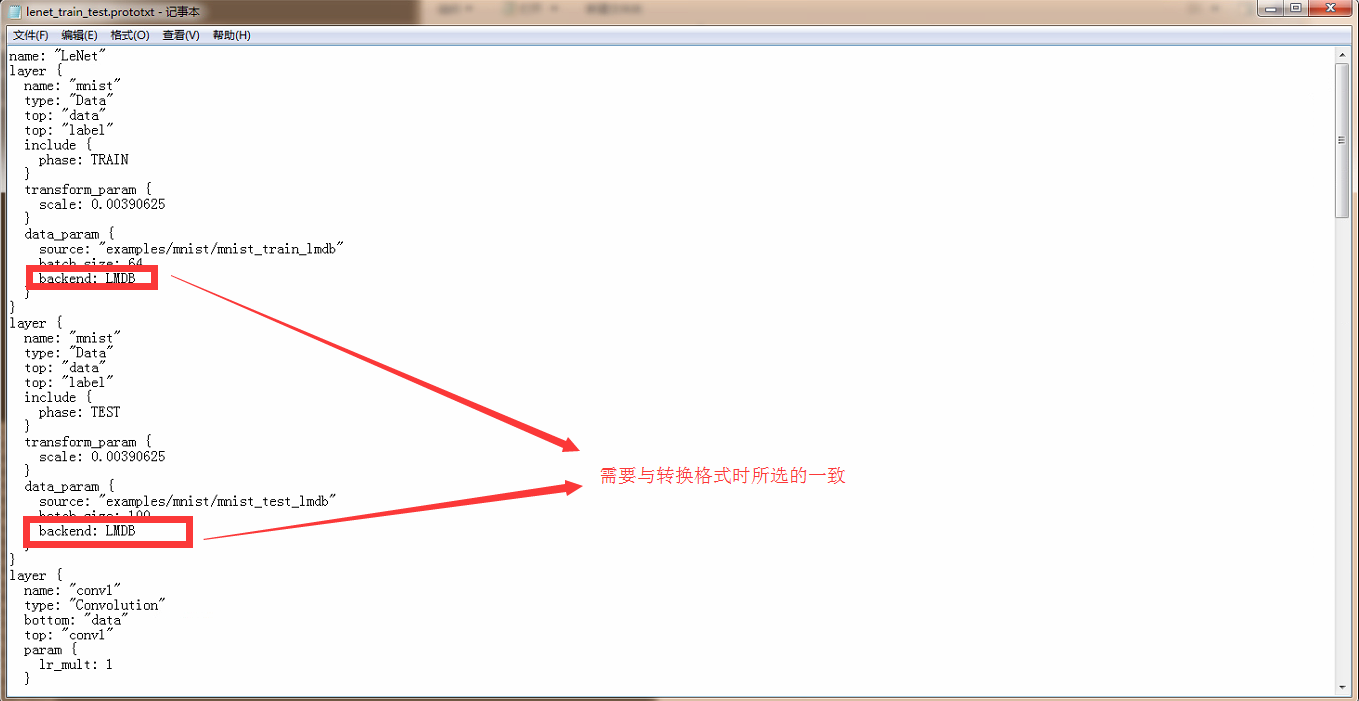
If the format here is inconsistent with the data set conversion, it needs to be modified to be consistent. The simple thing is to directly modify the configuration file format here to leveldb or lmdb. Otherwise, it is modified to be consistent with this when converting. If there is no problem, we directly run:
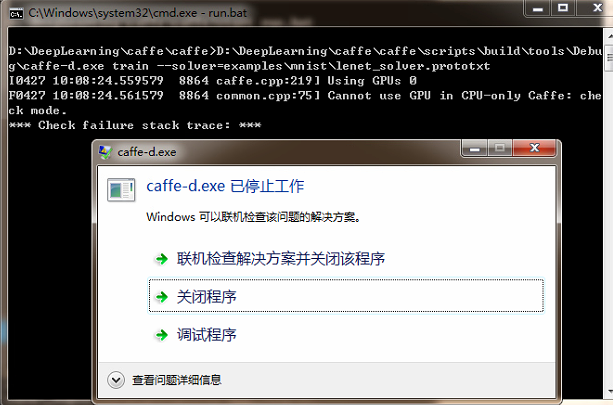
It was found that there was an error in the operation, and the error feedback was probably because the selected training method had a problem and the GPU could not be used. When we installed caffe, we said that we are using CPU training. So the exception here must be because of a configuration problem. Let's open the lenet_solver.prototxt file to see:
# The train/test net protocol buffer definition net: "examples/mnist/lenet_train_test.prototxt" # test_iter specifies how many forward passes the test should carry out. # In the case of MNIST, we have test batch size 100 and 100 test iterations, # covering the full 10,000 testing images. test_iter: 100 # Carry out testing every 500 training iterations. test_interval: 500 # The base learning rate, momentum and the weight decay of the network. base_lr: 0.01 momentum: 0.9 weight_decay: 0.0005 # The learning rate policy lr_policy: "inv" gamma: 0.0001 power: 0.75 # Display every 100 iterations display: 100 # The maximum number of iterations max_iter: 10000 # snapshot intermediate results snapshot: 5000 snapshot_prefix: "examples/mnist/lenet" # solver mode: CPU or GPU solver_mode: GPU -- should be CPU here because we are using CPU training
You can find the text display "# solver mode: CPU or GPU" through the code comments, which means that you can choose CPU or GPU, but since we configured the CPU in the early stage, we should modify it to CPU for training. After the modification is completed, we continue to execute run.bat
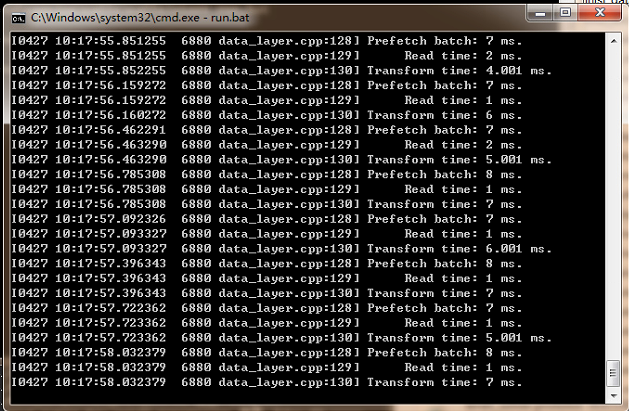
The feedback through the command window after running is that the feature is already being trained and extracted, and no error is reported to indicate success.