foreword
High concurrency often occurs in business scenarios with a large number of active users and high user aggregation, such as: spike activity, regular red envelopes, etc.
In order to make the business run smoothly and give users a good interactive experience, we need to design a high-concurrency processing solution suitable for our business scenario based on factors such as the estimated concurrency of the business scenario.
In the years of e-commerce-related product development, I have been fortunate enough to encounter various pitfalls. There is a lot of blood and tears along the way. The summary here will serve as my own archive record and share it with Everyone.
server architecture
From the early stage of development to the gradual maturity of business, the server architecture also changes from relatively single to cluster, and then to distributed services.
A service that can support high concurrency requires a good server architecture, which requires balanced load, a master-slave cluster for databases, a master-slave cluster for nosql cache, and a CDN for static files.
Most of the servers need the cooperation and construction of operation and maintenance personnel. I will not say more about the specifics, so far.
The server architecture that needs to be roughly used is as follows:
- server
- Load balance (eg: nginx, Alibaba Cloud SLB)
- Resource monitoring
- distributed
- database
- Master-slave separation, clustering
- DBA table optimization, index optimization, etc.
- distributed
- nosql
- say again
- Master-slave separation, clustering
- mongodb
- Master-slave separation, clustering
- memcache
- Master-slave separation, clustering
- say again
- cdn
- html
- css
- js
- image
Concurrency testing
Businesses related to high concurrency require concurrency testing, and the amount of concurrency that the entire architecture can support can be evaluated through a large amount of data analysis.
To test high concurrency, you can use a third-party server or your own test server, use test tools to test concurrent requests, and analyze the test data to obtain an assessment that can support the number of concurrency. This can be used as an early warning reference.
Third Party Services:
- Alibaba Cloud Performance Test
Concurrency testing tools:
- Apache JMeter
- Visual Studio Performance Load Test
- Microsoft Web Application Stress Tool
Practical plan
General solution
The daily user traffic is large, but it is relatively scattered, and occasionally there are high gatherings of users;
Scenario: User check-in, user center, user order, etc.
Server architecture diagram: 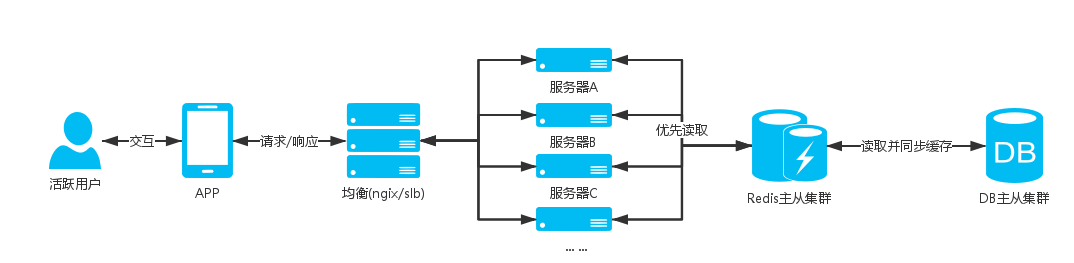
illustrate:
These services in the scenario are basically operated by users after entering the APP. Except for event days (618, Double 11, etc.), the number of users of these services will not be highly aggregated, and the tables related to these services are all big data tables. , the business is mostly query operations, so we need to reduce the query that users directly hit the DB; query the cache first, if the cache does not exist, then perform the DB query to cache the query results.
Updating user-related caches requires distributed storage. For example, using user IDs for hash grouping and distributing users to different caches, the total amount of such a cache collection will not be large and will not affect query efficiency.
Schemes such as:
- Users sign in to earn points
- Calculate the key distributed by users, find the user's check-in information today in redis hash
- If the check-in information is queried, return the check-in information
- If there is no query, the DB queries whether you have checked in today. If you have checked in, the check-in information will be synchronized to the redis cache.
- If today's check-in record is not queried in the DB, perform the check-in logic, operate the DB to add today's check-in record, and add check-in points (this entire DB operation is a transaction)
- Cache the check-in information to redis, and return the check-in information
注意There will be logical problems in concurrent situations, such as: checking in multiple times a day, and issuing multiple points to users.- My blog post [ High Concurrency in the Eyes of Big Talk Programmers ] has related solutions.
- User order
- Here we only cache the order information on the first page of the user, 40 pieces of data per page, and the user generally only sees the order data on the first page
- The user accesses the order list, if it is the first page to read the cache, if it is not to read the DB
- Calculate the key of user distribution, find user order information in redis hash
- If the user's order information is queried, return the order information
- If it does not exist, query the order data on the first page in DB, then cache redis and return the order information
- User Center
- Calculate the key of user distribution, find user order information in redis hash
- If user information is queried, return user information
- If there is no user DB query, then cache redis and return user information
- Other business
- The above examples are mostly for user storage cache. If it is public cache data, some issues need to be paid attention to, as follows
注意Common cache data needs to consider the possibility of a large number of hit DB queries under concurrency. You can use the management background to update the cache, or the lock operation of DB queries.- My blog post [ Dahua Redis Advanced ] shares update cache problems and recommended solutions.
The above example is a relatively simple high-concurrency architecture. It can be well supported if the concurrency is not very high. However, as the business grows and the user concurrency increases, our architecture will also be continuously optimized and evolved. The business is service-oriented, each service has its own concurrent architecture, its own balanced server, distributed database, nosql master-slave cluster, such as: user service, order service;
message queue
For activities such as instant kills and instant grabs, users flood in in an instant to generate high concurrent requests
Scenario: receive red envelopes regularly, etc.
Server architecture diagram: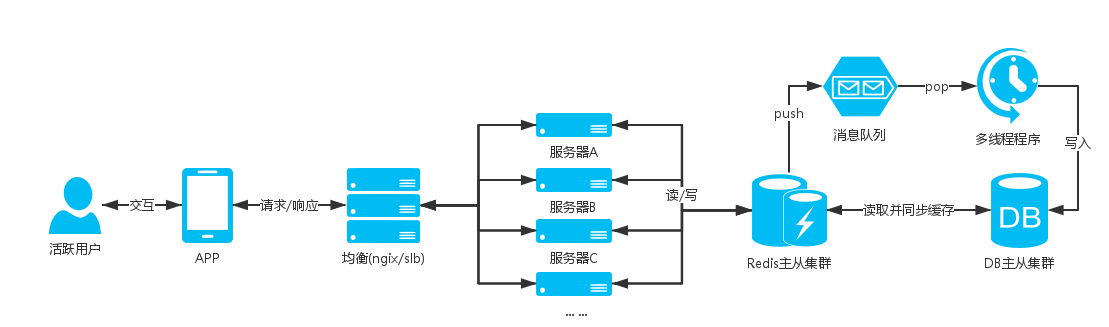
illustrate:
The scheduled receipt in the scenario is a high-concurrency business. For example, users will flood in at the appointed time in the seckill event, and the DB will receive a critical hit in an instant. If it can't hold it, it will crash, which will affect the entire business.
For this kind of business that is not only a query operation, but also has high concurrent data insertion or update, the general solution mentioned above cannot be supported, and the DB is directly hit when it is concurrent;
When designing this business, a message queue will be used. You can add the information of participating users to the message queue, and then write a multi-threaded program to consume the queue and issue red envelopes to users in the queue;
Schemes such as:
- Receive red envelopes regularly
- Generally used to use redis list
- When the user participates in the activity, push the user participation information to the queue
- Then write a multi-threaded program to pop data and carry out the business of issuing red envelopes
- In this way, users with high concurrency can participate in activities normally and avoid the danger of database server downtime.
Additional:
A lot of services can be done through message queues.
Such as: timing SMS sending service, use sset (sorted set), send timestamp as the sorting basis, SMS data queue is in ascending order according to time, and then write a program to read the first item in the sset queue periodically, whether the current time exceeds the sending time If the time is exceeded, the SMS will be sent.
L1 cache
The high concurrent request connection cache server exceeds the number of request connections the server can receive, and some users have the problem that the connection timeout cannot be read;
Therefore, there is a need for a solution that can reduce hits to the cache server when there is high concurrency;
At this time, there is a first-level cache solution. The first-level cache is to use the site server cache to store data. Note that only part of the data with a large amount of requests is stored, and the amount of cached data should be controlled, and the memory of the site server should not be used excessively. It affects the normal operation of the site application. The first-level cache needs to set the expiration time in seconds. The specific time is set according to the business scenario. The purpose is to make the data acquisition hit the first-level cache when there are high concurrent requests. Connect to the cached nosql data server to reduce the pressure on the nosql data server
For example, the APP first screen commodity data interface, these data are public and will not be customized for users, and these data will not be updated frequently, such as the large amount of requests of this interface, it can be added to the first-level cache;
Server Architecture Diagram: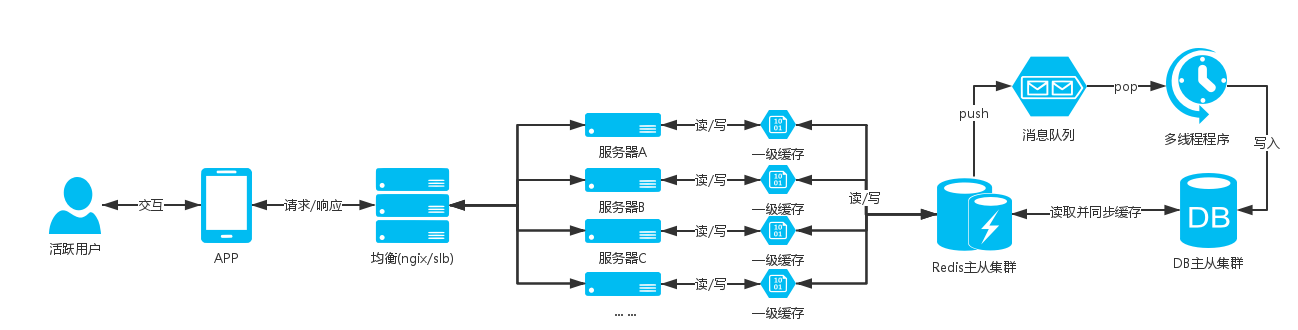
Reasonable specification and use of the nosql cache database, splitting the cache database cluster according to the business, this can basically support the business well. After all, the first-level cache uses the site server cache, so it should be used well.
static data
If the high concurrent request data does not change, if you can not request your own server to obtain data, it can reduce the resource pressure of the server.
If the update frequency is not high and the data can be delayed for a short time, the data can be statically converted into JSON, XML, HTML and other data files and uploaded to the CDN. When pulling data, the CDN is given priority to pull. Obtained from the cache and database, when the administrator operates the background to edit the data and then regenerate the static file and upload it to the CDN, so that the data can be obtained on the CDN server during high concurrency.
There is a certain delay in the synchronization of CDN nodes, so it is also very important to find a reliable CDN server provider
Other options
- For data that is not frequently updated, APP and PC browsers can cache the data locally, and then upload the version number of the current cached data each time the interface is requested. The server receives the version number to determine the version number and the latest data version number. Whether they are consistent, if they are different, query the latest data and return the latest data and the latest version number. If they are the same, return a status code to inform that the data is up-to-date.
减少服务器压力:资源、带宽
I specially sorted out the above technologies. There are many technologies that can’t be explained clearly in a few words, so I just asked a friend to record some videos. The answers to many questions are actually very simple, but the thinking and logic behind them are not simple. If you know it, you also need to know why. If you want to learn Java engineering, high performance and distributed, explain the profound things in simple language. Friends of microservices, Spring, MyBatis, and Netty source code analysis can add my Java advanced group: 433540541. In the group, there are Ali Daniel live-broadcasting technology and Java large-scale Internet technology videos for free to share with you.
Layered, segmented, distributed
Large-scale websites need to support high concurrency, which requires long-term planning and design.
In the early stage, the system needs to be layered. During the development process, the core business is divided into modular units, and distributed deployment can be carried out independently according to requirements. Team maintenance and development.
- Layered
- Divide the system into several parts in the horizontal dimension, each department is responsible for a relatively simple and relatively single responsibility, and then form a complete system through the dependence and scheduling of the upper layer on the lower layer
- For example, the e-commerce system is divided into: application layer, service layer, data layer. (How many levels are divided according to their own business scenarios)
- Application layer: website homepage, user center, commodity center, shopping cart, red envelope business, activity center, etc., responsible for specific business and view display
- Service layer: order service, user management service, red envelope service, commodity service, etc., provide service support for the application layer
- Data layer: relational database, nosql database, etc., providing data storage and query services
- The layered architecture is logical and can be deployed on the same physical machine in physical deployment. However, with the development of website business, it is necessary to separate and deploy the already layered modules and deploy them on different servers, so that the website can be deployed separately. Can support more user access
- Split
- Segment the business vertically, and divide a relatively complex business into different modular units
- Packaging into modules with high cohesion and low coupling not only facilitates the development and maintenance of software, but also facilitates the distributed deployment of different modules, improving the concurrent processing capability and functional expansion of the website
- For example, the user center can be divided into: account information module, order module, recharge module, withdrawal module, coupon module, etc.
- distributed
- Distributed applications and services, distributed deployment of layered or segmented business, independent application server, database, cache server
- When the business reaches a certain number of users, the server balances the load, the database, and the cache master-slave cluster.
- Distributed static resources, such as: static resource upload cdn
- Distributed computing, such as: using hadoop for distributed computing of big data
- Distributed data and storage, for example: each distributed node stores data in a decentralized manner according to hash algorithms or other algorithms
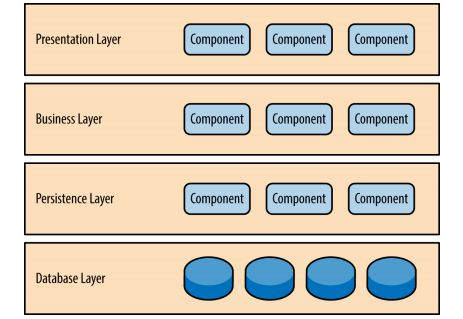
Website Layering - Figure 1 from the Web
cluster
Servers, application servers, databases, and nosql databases are independently deployed for user access to centralized services. The core business basically needs to build a cluster, that is, multiple servers deploy the same application to form a cluster, and provide services to the outside world through load balancing equipment. The server cluster can provide more concurrent support for the same service, so when there are more users When accessing, you only need to add a new machine to the cluster. In addition, when one of the servers fails, the request can be transferred to other servers in the cluster through the failover mechanism of load balancing, so it can improve the performance of the cluster. system availability
- Application server cluster
- nginx reverse proxy
- slb
- … …
- (relational/nosql) database clustering
- Master-slave separation, slave library cluster
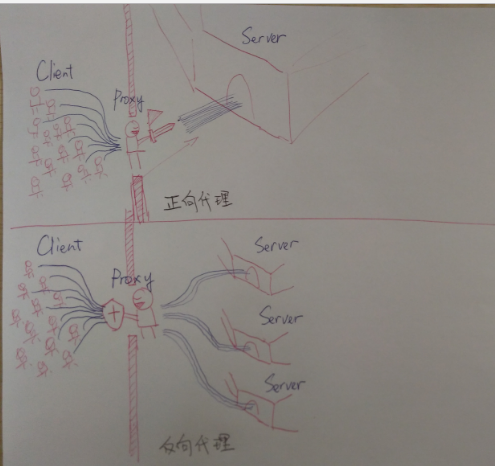
Load balancing via reverse proxy - Figure 2 from the web
asynchronous
In high-concurrency business, if database operations are involved, the main pressure is on the database server. Although master-slave separation is used, database operations are all performed on the master database. The maximum number of connections allowed by a single database server connection pool is limited. When the number of
connections reaches the maximum value, other requests that require connection data operations need to wait for idle connections, so that many requests will appear when there connection time out is
high concurrency. How do we design a development plan for such a high concurrency business Can the pressure on the database server be reduced?
- Such as:
- Automatic pop-up window check-in, concurrent request for check-in interface when Double 11 crosses 0:00
- Double 11 Red Packet Activity
- Double 11 orders put into storage
- Wait
- Design Considerations:
- Reverse thinking, the pressure is on the database, then the business interface will not perform database operations, and there will be no pressure
- Does data persistence allow for latency?
- How to make the business interface not directly operate the DB, but also make the data persistent?
- Design:
- For such high concurrency business involving database operations, it is necessary to consider using asynchrony
- The client initiates an interface request, the server responds quickly, the client displays the result to the user, and the database operation is synchronized asynchronously
- How to achieve asynchronous synchronization?
- Using the message queue, enqueue the stored content to the message queue, and the business interface quickly responds to the user's results (you can warmly remind that the arrival of the account is delayed during the peak period)
- Then write a separate program to dequeue the data from the message queue to perform the warehousing operation. After the warehousing is successful, the user-related cache is refreshed. If the warehousing fails, the log is recorded, which is convenient for feedback query and re-persistence.
- In this way, only one program (multi-threaded) can complete the database operation, which will not put pressure on the data.
- Replenish:
- In addition to being used in high-concurrency services, message queues can also be used in other services that have the same requirements, such as SMS sending middleware, etc.
- Asynchronous persistence of data under high concurrency may affect the user experience. You can switch from time to time or use asynchrony in a configurable way or automatically monitor resource consumption. In this way, you can use the database to improve user experience under normal traffic conditions.
- Asynchronous can also refer to asynchronous functions and asynchronous threads in programming. Sometimes asynchronous operations can be used, and operations that do not need to wait for the result are placed in asynchronous, and then the subsequent operations are continued, saving the time for this part of the waiting operation.
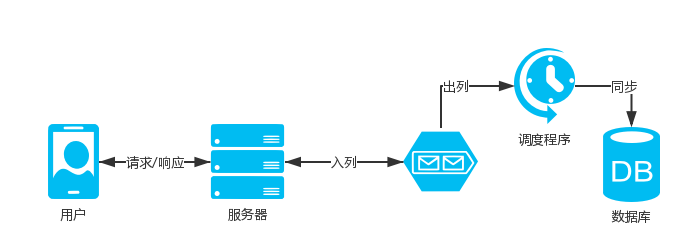
cache
Most of the high-concurrency business interfaces are for querying business data, such as: product list, product information, user information, red envelope information, etc. These data do not change frequently, and are persistent and
directly connected in the case of high concurrency in the database For query operations from the database, multiple slave database servers cannot withstand such a large number of connection requests (as mentioned earlier, the maximum number of connections allowed by a single database server is limited),
then we need to use this high-concurrency business interface. How to design it?
- Design Considerations:
- Or reverse thinking, the pressure is on the database, then we will not query the database
- The data does not change frequently, why do we keep querying the DB?
- The data does not change. Why does the client request the server to return the same data?
- Design:
- The data does not change frequently. We can cache the data. There are many ways to cache the data. Generally, the application server caches the memory directly. The mainstream: it is stored in the memcache and redis memory database.
- Cache is directly stored in the application server, and the reading speed is fast. The number of connections allowed by the in-memory database server can be supported to a large extent, and the data is stored in memory, and the reading speed is fast. Coupled with the master-slave cluster, it can support a large concurrency. Inquire
- According to the business scenario, use the local storage with the client. If our data content does not change frequently, why do we keep requesting the server to obtain the same data? We can match the data version number. If the version number is different, the interface will re-query the cache to return the data and version number. , if the same, do not query data and respond directly
- This can not only improve the interface response speed, but also save server bandwidth. Although some server bandwidth is billed by traffic, it is not absolutely unlimited. In high concurrency, server bandwidth may also cause slow request response problems.
- Replenish:
- Cache also refers to static resource client-side caching
- cdn caching, static resources are cached by uploading cdn, cdn nodes cache our static resources, reducing server pressure
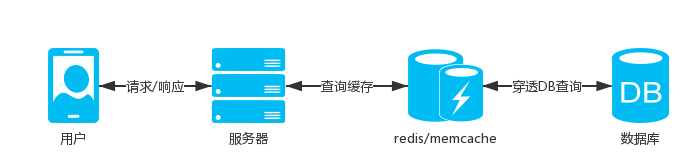
service oriented
SOAService Oriented Architecture Design微服务More fine-grained service, a series of independent services together form a system
Using service-oriented thinking, the core business or general business functions are separated into services and deployed independently, and functions are provided by providing external interfaces.
The most ideal design is to separate a complex system into multiple services, which together form the business of the system. Advantages: loose coupling, high availability, high scalability, and easy maintenance.
Through service-oriented design, independent server deployment, load balancing, and database clustering, services can support higher concurrency
- Service example:
- User behavior tracking record statistics
- illustrate:
- By reporting application modules, operation events, event objects, and other data, record the user's operation behavior
- For example: record that the user clicks on a certain product in a certain product module, or browses a certain product
- background:
- Since the service needs to record the various operation behaviors of users, and can be reported repeatedly, and the business to be accessed to the service is also the user behavior tracking of the core business, the request volume is large, and a large number of concurrent requests will be generated during peak periods.
- Architecture:
- nodejs WEB application server load balancing
- redis master-slave cluster
- mysql master
- nodejs+express+ejs+redis+mysql
- The server uses nodejs, nodejs is a single process (PM2 opens multiple worker processes according to the number of cpu cores), adopts an event-driven mechanism, is suitable for I/O-intensive business, and has strong ability to handle high concurrency
- Business Design:
- The amount of concurrency is large, so it cannot be directly stored in the warehouse, using: asynchronous synchronization data, message queue
- Request the interface to report data, and the interface will push the reported data to the redis list queue
- nodejs writes the library script, loops the pop redis list data, stores the data in the library, and performs related statistics Update, sleep for a few seconds when there is no data
- Because the amount of data will be relatively large, the reported data table is named and stored by day
- interface:
- Reporting data interface
- Statistics query interface
- Online follow up:
- The service business is basically normal
- There are tens of millions of data reported every day
redundant, automated
When the server where the high-concurrency business is located goes down, it is necessary to have a backup server for rapid replacement. When the application server is under high pressure, machines can be quickly added to the cluster, so we need a backup machine that can be on standby at any time. The most ideal way is to automatically monitor server resource consumption to alarm, automatically switch downgrade schemes, and automatically perform server replacement and addition operations. Through automation, the cost of manual operations can be reduced, and it can be operated quickly to avoid manual operations. 's mistakes.
- redundancy
- database backup
- Standby server
- automation
- Automated monitoring
- automatic alarm
- Automatic downgrade
Through the GitLab incident, we should reflect on the fact that backing up data does not mean it is foolproof. We need to ensure high availability. First, whether the backup is running normally and whether the backup data is available requires us to conduct regular checks or automated monitoring, and include How to avoid human error. (However, the open attitude of gitlab in the event, the positive handling method is still worth learning)
Summarize
High-concurrency architecture is a process of constant evolution. Three feet of ice caves are not cold in a day, and the construction of the Great Wall is not a day's work
. It is very important to lay a good infrastructure to facilitate future expansion.
Here, the architectural ideas under high concurrency are rearranged, and several practical examples are given. If you have any comments or suggestions on the content of the expression, please leave a message.