This article was first published on the Nebula Graph Community public account

Solutions
The most convenient way to solve the problem of not being able to connect to the cluster after K8s deploys the Nebula Graph cluster is to run nebula-algorithm / nebula-spark in the same network namespace as nebula-operator, show hosts metaand 域名:端口fill in the address in MetaD format into the configuration. .
Note: Version 2.6.2 or later is required here, nebula-spark-connector / nebula-algorithm only supports MetaD addresses in the form of domain names.
Here's the actual network configuration:
- Get MetaD address
(root@nebula) [(none)]> show hosts meta
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local" | 9559 | "ONLINE" | "META" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
Got 1 rows (time spent 1378/2598 us)
Mon, 14 Feb 2022 08:22:33 UTC
The Host name needs to be recorded here so that it can be used in subsequent configuration files.
- Fill in the configuration file of nebula-algorithm
Refer to the documentation https://github.com/vesoft-inc/nebula-algorithm/blob/master/nebula-algorithm/src/main/resources/application.conf . There are two ways to fill in the configuration file: modify the TOML file or add configuration information in the nebula-spark-connector code.
Method 1: Modify the TOML file
# ...
nebula: {
# algo's data source from Nebula. If data.source is nebula, then this nebula.read config can be valid.
read: {
# 这里填上刚获得到的 meta 的 Host 名,多个地址的话用英文字符下的逗号隔开;
metaAddress: "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559"
#...
Method 2: Call the code of nebula-spark-connector
val config = NebulaConnectionConfig
.builder()
// 这里填上刚获得到的 meta 的 Host 名
.withMetaAddress("nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("foo_bar_space")
.withLabel("person")
.withNoColumn(false)
.withReturnCols(List("birthday"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
Ok, so far, the process looks pretty straightforward. So why is such a simple process worth an article?
Configuration information is easy to ignore
We just talked about the specific practical operation, but there are some theoretical knowledge here:
a. MetaD implicitly needs to ensure that the address of StorageD can be accessed by the Spark environment;
b. The StorageD address is obtained from MetaD;
c. In Nebula K8s Operator, the source of the StorageD address (service discovery) stored in MetaD is the StorageD configuration file, which is the internal address of K8s.
background knowledge
The reason for a. is relatively straightforward and is related to the architecture of Nebula: the data of the graph is stored in the Storage Service. Usually, the query of the statement is transparently transmitted through the Graph Service, only the connection of GraphD is enough, and nebula-spark- The scenario where the connector uses Nebula Graph is to scan the whole graph or subgraph. At this time, the design of separation of computing and storage allows us to bypass the query and computing layer to directly and efficiently read graph data.
So the question is, why do you need and only need the MetaD address?
This is also related to the architecture. The Meta Service contains the distribution data of the full graph and the distribution of each shard and instance of the distributed Storage Service. Therefore, on the one hand, only Meta has the information of the full graph (required), on the other hand Because this part of the information (only) can be obtained from Meta. Here is the answer for b .
- Detailed Nebula Graph architecture information can refer to the architecture trilogy series
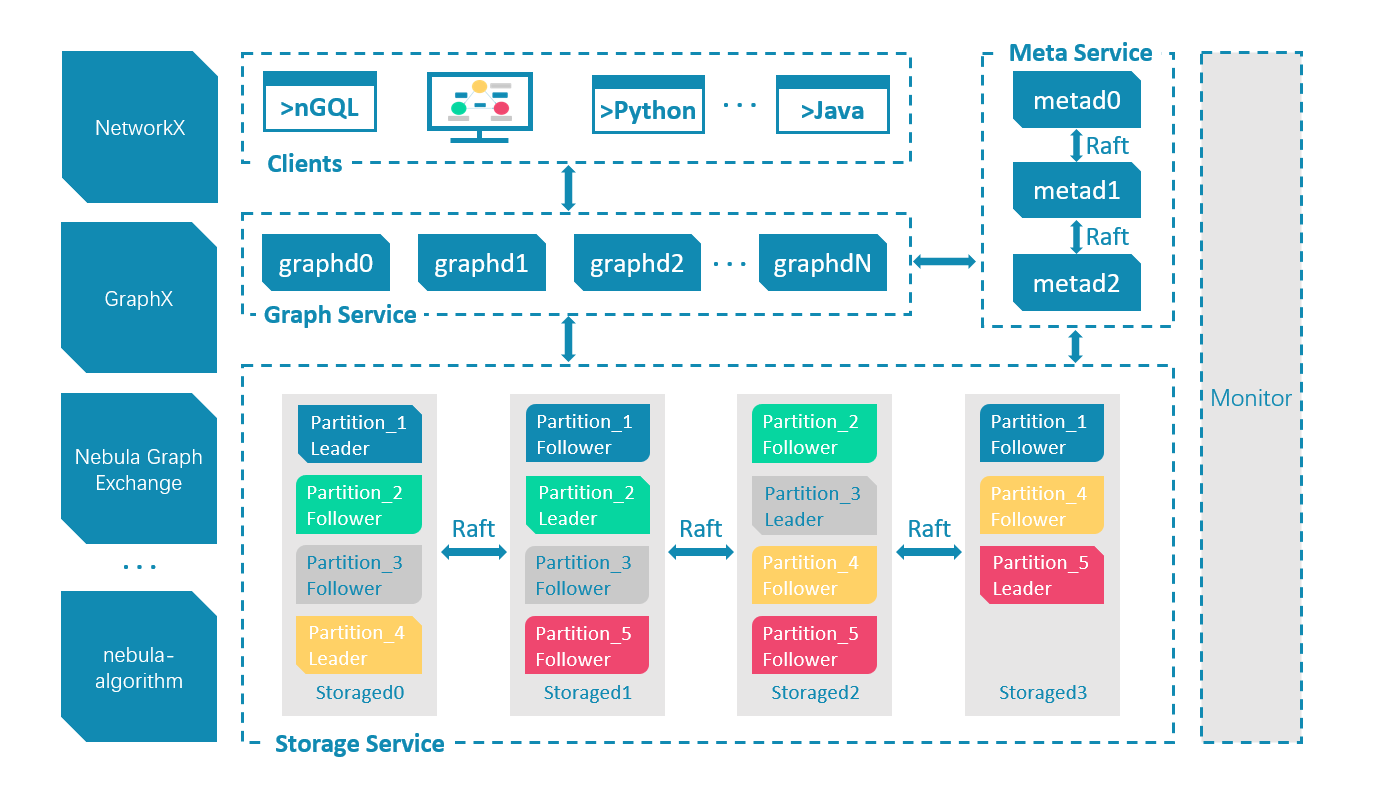
Let's take a look at the logic behind c.
c. In the Nebula K8s Operator, the source of the StorageD address (service discovery) stored in MetaD is the StorageD configuration file, which is the internal address of k8s.
This is related to the service discovery mechanism in Nebula Graph: in the Nebula Graph cluster, both the Graph Service and the Storage Service report their information to the Meta Service through heartbeat, and the source of the service's own address comes from their corresponding The network configuration in the configuration file.
-
For the address configuration of the service itself, please refer to the document: Storage networking configuration
-
For detailed information about service discovery, please refer to the article of Four Kings: Graph Database Nebula Graph Cluster Communication: Starting with Heartbeat .

Finally, we know that the Nebula Operator is an application that automatically creates, maintains, and scales the K8s control plane of the Nebula cluster according to the configuration in the K8s cluster. It needs to abstract some internal resource-related configurations, including GraphD and StorageD instances. The actual addresses they are configured with are actually headless service addresses .
These addresses (as follows) cannot be accessed by K8s external network by default, so for GraphD and MetaD, we can easily create services to expose them.
(root@nebula) [(none)]> show hosts meta
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local" | 9559 | "ONLINE" | "META" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
Got 1 rows (time spent 1378/2598 us)
Mon, 14 Feb 2022 09:22:33 UTC
(root@nebula) [(none)]> show hosts graph
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
| "nebula-graphd-0.nebula-graphd-svc.default.svc.cluster.local" | 9669 | "ONLINE" | "GRAPH" | "d113f4a" | "2.6.2" |
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
Got 1 rows (time spent 2072/3403 us)
Mon, 14 Feb 2022 10:03:58 UTC
(root@nebula) [(none)]> show hosts storage
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
| "nebula-storaged-0.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
| "nebula-storaged-1.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
| "nebula-storaged-2.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
Got 3 rows (time spent 1603/2979 us)
Mon, 14 Feb 2022 10:05:24 UTC
However, because the aforementioned nebula-spark-connector obtains the address of StorageD through Meta Service, and this address is discovered by the service, the StorageD address actually obtained by nebula-spark-connector is the above headless service. address, which cannot be accessed directly from the outside.
Therefore, if we have the conditions, we only need to let Spark run in the same K8s network as Nebula Cluster, and everything will be solved. Otherwise, we need to:
-
Expose the L4 (TCP) addresses of MetaD and StorageD by means of Ingress.
You can refer to the documentation of Nebula Operator: https://github.com/vesoft-inc/nebula-operator
-
These headless services can be resolved to the corresponding StorageD through reverse proxy and DNS.
So, is there a more convenient way?
Unfortunately, the most convenient way is still as described at the beginning of the article: let Spark run inside the Nebula Cluster. In fact, I'm trying to push the Nebula Spark community to support the configurable StorageAddresses option, and with it, the aforementioned 2. is unnecessary.
More convenient nebula-algorithm + nebula-operator experience
In order to facilitate the students who are early adopters of nebula-graph and nebula-algorithm on K8s, here is a small tool Neubla-Operator-KinD written by Amway himself . Operator and all dependencies (including storage provider) widgets. Not only that, but it automatically deploys a small Nebula cluster. You can see the steps below:
The first step is to deploy K8s + nebula-operator + Nebula Cluster:
curl -sL nebula-kind.siwei.io/install.sh | bash

The second step, follow what's next in the tool documentation
a. Use the console to connect to the cluster and load the sample dataset
b. Run a graph algorithm in this K8s
- Create a Spark environment
kubectl create -f http://nebula-kind.siwei.io/deployment/spark.yaml
kubectl wait pod --timeout=-1s --for=condition=Ready -l '!job-name'
- After the waits above are ready, enter the spark pod.
kubectl exec -it deploy/spark-deployment -- bash
- Download nebula-algorithm such as
2.6.2this version. For more versions, please refer to https://github.com/vesoft-inc/nebula-algorithm/.
Precautions:
- The official release version is available here: https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/
- Because of this issue: https://github.com/vesoft-inc/nebula-algorithm/issues/42 Only
2.6.2or newer versions support domain name access to MetaD.
# 下载 nebula-algorithm-2.6.2.jar
wget https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/2.6.2/nebula-algorithm-2.6.2.jar
# 下载 nebula-algorthm 配置文件
wget https://github.com/vesoft-inc/nebula-algorithm/raw/v2.6/nebula-algorithm/src/main/resources/application.conf
- Modify the mete and graph address information in nebula-algorithm.
sed -i '/^ metaAddress/c\ metaAddress: \"nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559\"' application.conf
sed -i '/^ graphAddress/c\ graphAddress: \"nebula-graphd-0.nebula-graphd-svc.default.svc.cluster.local:9669\"' application.conf
##### change space
sed -i '/^ space/c\ space: basketballplayer' application.conf
##### read data from nebula graph
sed -i '/^ source/c\ source: nebula' application.conf
##### execute algorithm: labelpropagation
sed -i '/^ executeAlgo/c\ executeAlgo: labelpropagation' application.conf
- Execute LPA algorithm in basketballplayer graph space
/spark/bin/spark-submit --master "local" --conf spark.rpc.askTimeout=6000s \
--class com.vesoft.nebula.algorithm.Main \
nebula-algorithm-2.6.2.jar \
-p application.conf
- The result is as follows:
bash-5.0# ls /tmp/count/
_SUCCESS part-00000-5475f9f4-66b9-426b-b0c2-704f946e54d3-c000.csv
bash-5.0# head /tmp/count/part-00000-5475f9f4-66b9-426b-b0c2-704f946e54d3-c000.csv
_id,lpa
1100,1104
2200,2200
2201,2201
1101,1104
2202,2202
Next, you can Happy Graphing!
Exchange graph database technology? To join the Nebula exchange group, please fill in your Nebula business card first , and the Nebula assistant will pull you into the group~~
Pay attention to the public account