What is the detailed scheme for using Redis distributed locks?
A simple answer is to use a Redission client. The lock scheme in Redission is a perfect detailed scheme of Redis distributed locks.
So, why is the lock scheme in Redission perfect?
It just so happens that I have a lot of experience in using Redis to do distributed locks. In actual work, I have also explored many solutions for using Redis to do distributed locks, and I have learned countless blood and tears.
So, before talking about why the Redission lock is perfect, let me show you the problems I have encountered when using Redis as a distributed lock.
I once used Redis as a distributed lock to solve the problem of a user grabbing coupons. This business requirement is as follows: after a user has received a coupon, the number of coupons must be reduced by one accordingly. If the coupons are sold out, the user is not allowed to snatch any more.
When implementing, first read the number of coupons from the database to judge, when the coupon is greater than 0, allow the coupon to be received, and then reduce the number of coupons by one, and write it back to the database.
At that time, due to the large number of requests, we used three servers for offloading.
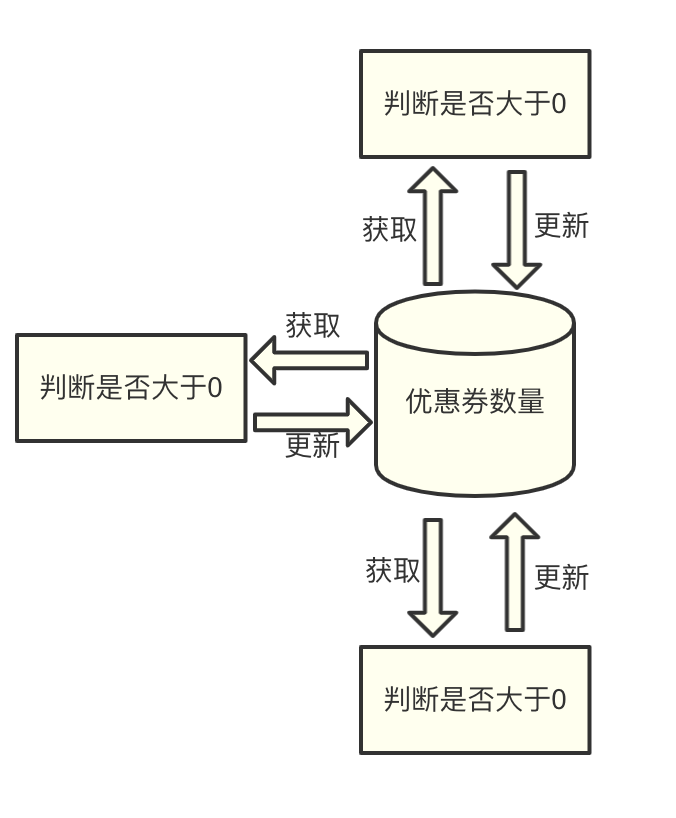
At this point a problem will arise:
If application A on one of the servers obtains the number of coupons, the number of coupons in the database is not updated in time due to processing related business logic; while application A is processing business logic, application B on the other server updates number of coupons. Then, when application A updates the number of coupons in the database, it will overwrite the number of coupons updated by application B.
Seeing this, some people may be strange, why not use SQL directly here:
update 优惠券表 set 优惠券数量 = 优惠券数量 - 1 where 优惠券id = xxx
The reason for this is that without distributed lock coordination, the number of coupons could be directly negative. Because when the number of coupons is 1, if two users initiate a request to grab a coupon through two servers at the same time, both satisfy the condition that the coupon is greater than 0, and then both execute this SQL statement, and the number of coupons directly becomes -1 now.
Some people say that optimistic locking can be used, such as using the following SQL:
update 优惠券表 set 优惠券数量 = 优惠券数量 - 1 where 优惠券id = xxx and version = xx
In this way, under a certain probability, it is very likely that the data cannot be updated all the time, resulting in a long retry.
Therefore, after comprehensive consideration, we adopted the Redis distributed lock, which is mutually exclusive to prevent multiple clients from updating the number of coupons at the same time.
At that time, our first thought was to use the setnx command of Redis. The setnx command is actually a shorthand for set if not exists.
When the key is set successfully, it returns 1, otherwise it returns 0. Therefore, the successful setting of setnx here can mean that the lock is acquired. If it fails, it means that there is already a lock, which can be regarded as a failure to acquire the lock.
setnx lock true
If you want to release the lock, execute the del command to delete the key.
del lock
Using this feature, we can let the system execute the setnx command in Redis before executing the coupon logic. Then according to the execution result of the instruction, it is judged whether the lock is acquired. If it is obtained, continue to execute the business, and then use the del instruction to release the lock after execution. If it is not acquired, wait for a certain period of time and then acquire the lock again.
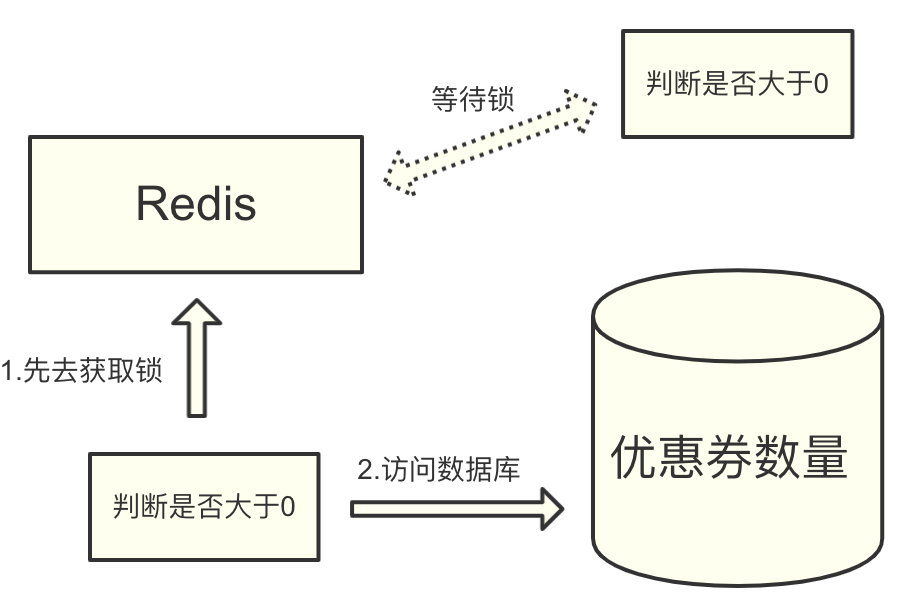
At first glance, this looks fine, and using the setnx instruction does have the desired effect of mutual exclusion.
However, this is assuming that all operating environments are normal. Once the operating environment is abnormal, the problem will appear.
Think about it, the application holding the lock suddenly crashes, or the server where it is located is down, what will happen?
This creates a deadlock - the application holding the lock cannot release the lock, and other applications have no chance to acquire the lock at all. This will cause huge online incidents, and we need to improve the solution to solve this problem.
How to solve it? We can see that the root cause of deadlock is that once there is a problem with the application holding the lock, the lock will not be released. Thinking in this direction, you can give the key an expiration time on Redis.
In this case, even if there is a problem, the key will be released after a period of time. Does this solve the problem? In fact, everyone does.
However, since the setnx command itself cannot set the timeout period, two methods are generally used to do this:
1. Using the lua script, after using the setnx command, use the expire command to set the expiration time for the key.
if redis.call("SETNX", "lock", "true") == 1 then
local expireResult = redis.call("expire", "lock", "10")
if expireResult == 1 then
return "success"
else
return "expire failed"
end
else
return "setnx not null"
end
2. Directly use the set(key,value,NX,EX,timeout) command to set the lock and timeout at the same time.
redis.call("SET", "lock", "true", "NX", "PX", "10000")
Either of the above two methods can be used.
The script to release the lock is the same in both ways, just call the del command of Redis directly.
So far, our locks have a mutual exclusion effect and will not cause deadlocks due to problems with some systems that hold the locks. Is this perfect?
Suppose there is such a situation, what if an application holding a lock exceeds the timeout period we set? Two situations will occur:
- It is found that the key set by the system in Redis still exists
- It is found that the key set by the system in Redis does not exist
The first situation is relatively normal. Because you have timed out the execution of the task after all, it is logical that the key is cleared normally.
But the most terrifying thing is the second case, it is found that the set key still exists. What does this mean? Indicates that the currently existing key is set by another application.
At this time, if the application holding the lock timeout calls the del command to delete the lock, the lock set by others will be deleted by mistake, which will directly cause problems in the system business.
So, in order to fix this, we need to keep making changes to the Redis script... destroy it, tired...

First, we want the application to set a unique value that only the application knows when it acquires the lock.
Through this unique value, when the system releases the lock, it can identify whether the lock is set by itself. If it is set by itself, release the lock, that is, delete the key; if not, do nothing.
The script is as follows:
if redis.call("SETNX", "lock", ARGV[1]) == 1 then
local expireResult = redis.call("expire", "lock", "10")
if expireResult == 1 then
return "success"
else
return "expire failed"
end
else
return "setnx not null"
end
or
redis.call("SET", "lock", ARGV[1], "NX", "PX", "10000")
Here, ARGV[1] is a parameter variable that can be passed in, and a unique value can be passed in. For example, a UUID value that only oneself knows, or through the snowball algorithm, a unique ID that only oneself holds is generated.
The script to release the lock is changed to this:
if redis.call("get", "lock") == ARGV[1]
then
return redis.call("del", "lock")
else
return 0
end
It can be seen that from a business point of view, our distributed lock can already meet the real business needs. It can be mutually exclusive, not deadlocked, and will not delete other people's locks by mistake. Only the locks on your own can be released by yourself.
Everything is so beautiful! ! !
Unfortunately, there is another hidden danger that we have not ruled out. This hidden danger is Redis itself.
You know, lua scripts are all used on Redis singletons. Once there is a problem with Redis itself, our distributed locks will be useless, and the distributed locks will be useless, which will have a significant impact on the normal operation of the business, which is unacceptable to us.
So, we need to make Redis highly available. Generally speaking, to solve the problem of high availability of Redis, master-slave clusters are used.
However, engaging in a master-slave cluster will introduce new problems. The main problem is that Redis's master-slave data synchronization is delayed. This delay will create a boundary condition: when Redis on the master has been locked, but the lock data has not been synchronized to the slave, the master is down. Then, the slave was upgraded to the master. At this time, the slave did not have the lock data set by the master before - the lock was lost... lost... lost...

At this point, we can finally introduce Redission (open source Redis client), let's see how it implements Redis distributed locks.
The idea of Redission to implement distributed locks is very simple. Whether it is a master-slave cluster or a Redis Cluster cluster, it will execute the script for setting Redis locks one by one for each Redis in the cluster, that is, each Redis in the cluster will contain settings. Good lock data.
Let's introduce it with an example.
Suppose there are 5 machines in the Redis cluster, and according to the evaluation, it is more appropriate to set the lock timeout time to 10 seconds.
In the first step, we first calculate the total waiting time of the cluster. The total waiting time of the cluster is 5 seconds (the timeout time of the lock is 10 seconds / 2).
Step 2, divide 5 seconds by the number of 5 machines, the result is 1 second. This 1 second is the acceptable wait time for each Redis connection.
Step 3, connect 5 Redis in turn, and execute the lua script to set the lock, and then make a judgment:
- If within 5 seconds, 5 machines have execution results, and more than half (that is, 3) machines successfully set the lock, it is considered that the lock is set successfully; if less than half of the machines successfully set the lock, it is considered to have failed.
- If it exceeds 5 seconds, no matter how many machines set the lock successfully, it is considered that the setting of the lock has failed. For example, it took 3 seconds to set up the first 4 machines successfully, but the last machine took 2 seconds to get no result, and the total waiting time has exceeded 5 seconds.
One more thing to say, in many business logics, there is actually no need for the timeout period of the lock.
For example, batch execution of processing tasks in the early morning may require distributed locks to ensure that tasks will not be executed repeatedly. At this point, it is unclear how long the task will take to execute. It doesn't make much sense to set the timeout for distributed locks here. However, if the timeout is not set, it will cause a deadlock problem.
Therefore, the general solution to this problem is that each client holding a lock starts a background thread, and continuously refreshes the key timeout time in Redis by executing a specific lua script, so that before the task execution is completed, key will not be cleared.
The script is as follows:
if redis.call("get", "lock") == ARGV[1]
then
return redis.call("expire", "lock", "10")
else
return 0
end
Among them, ARGV[1] is a parameter variable that can be passed in, which represents the unique value of the system that holds the lock, that is, only the client holding the lock can refresh the key's timeout period.
So far, a complete distributed lock has been implemented. The summary implementation is as follows:
- Use the set command to set the lock flag, there must be a timeout so that the client crashes and the lock can also be released;
- For those that do not need a timeout, you need to implement a thread that can continuously refresh the lock timeout;
- For each client that acquires the lock, the value set in Redis must be unique in order to identify which client set the lock;
- In a distributed cluster, directly set the same timeout and lock flag for each machine;
- In order to ensure that the locks set by the cluster do not time out due to network problems, the network waiting time and lock timeout time must be set reasonably.
This distributed lock satisfies the following four conditions:
- Only one client can hold the lock at any time;
- No deadlock can occur. There is a problem while a client is holding the lock and it is not unlocked. It can also ensure that other clients continue to hold the lock;
- Locking and unlocking must be done by the same client, and the lock added by the client can only be unlocked by itself;
- As long as most Redis nodes are healthy, clients can use locks normally.
Of course, in the script in Redission, in order to ensure the re-entrancy of the lock, some modifications have been made to the lua script, and now the complete lua script is pasted below.
The lua script to acquire the lock:
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
The corresponding refresh lock timeout script:
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end;
return 0;
The corresponding script to release the lock:
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil;
end;
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil;
So far, the detailed scheme for using Redis as a distributed lock has been written.
I wrote not only the rough experience of one step at a time, but also the details of each problem and solution. I hope everyone can gain something after reading it.
Finally, let me remind you that using Redis cluster as distributed lock is controversial, and you need to make better choices and trade-offs according to the actual situation when you actually use it.
Hello, I'm Shimonai.
The technical director of a listed company, managing a technical team of more than 100 people.
I wrote a lot of original articles, compiled some of the best articles, and made a PDF - " climbing ", which includes 15 technical articles (learning programming skills, architects, MQ, distributed ) and 13 non-technical articles (mostly programmer workplaces).
What is the quality of this document? I won't brag too much, many people say "benefit a lot" after reading it.
If you want to get "Climbing", you can scan the code in the picture below, follow my public account " Si Yuanwai ", and reply in the background: Climbing
