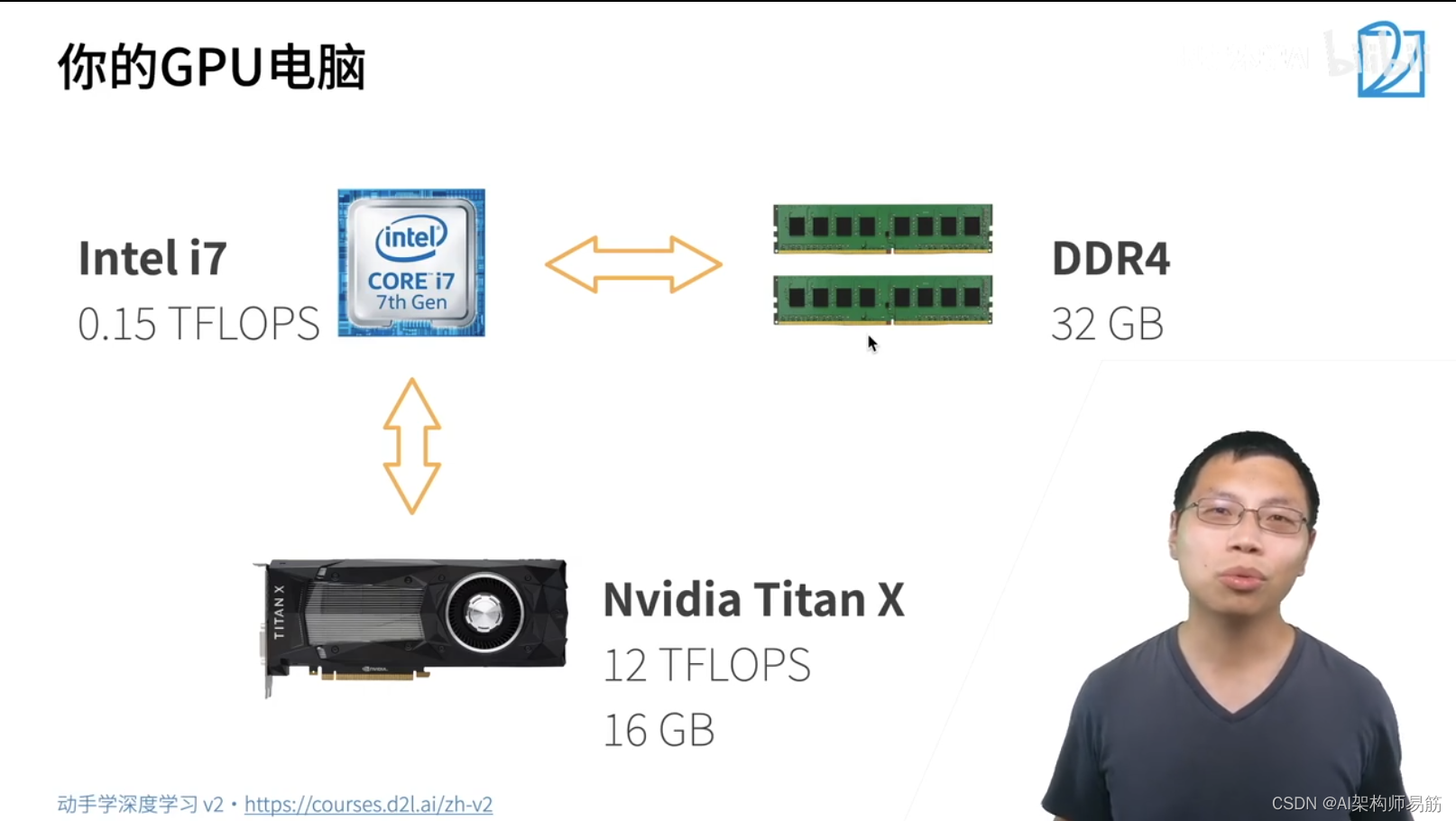
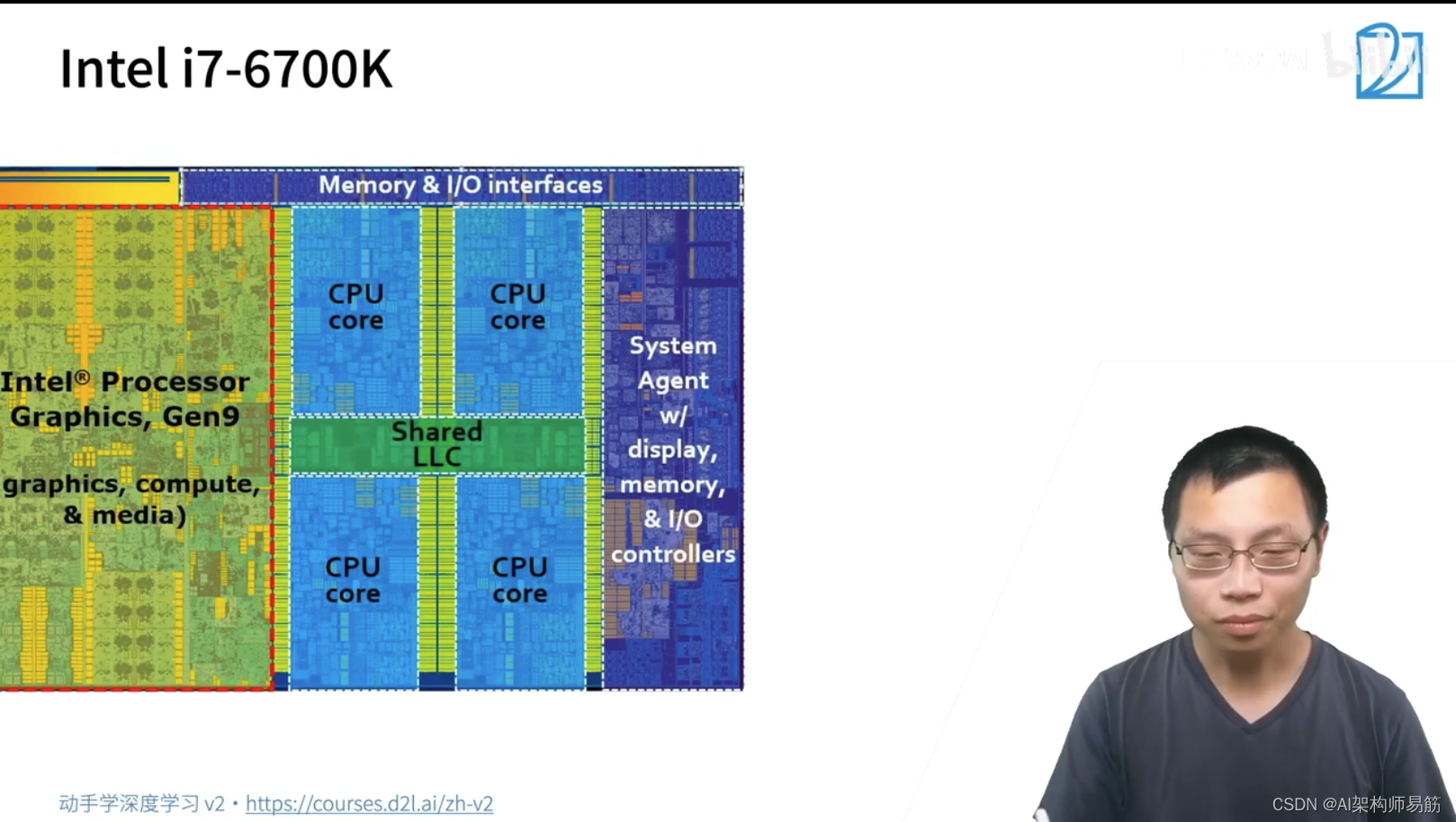
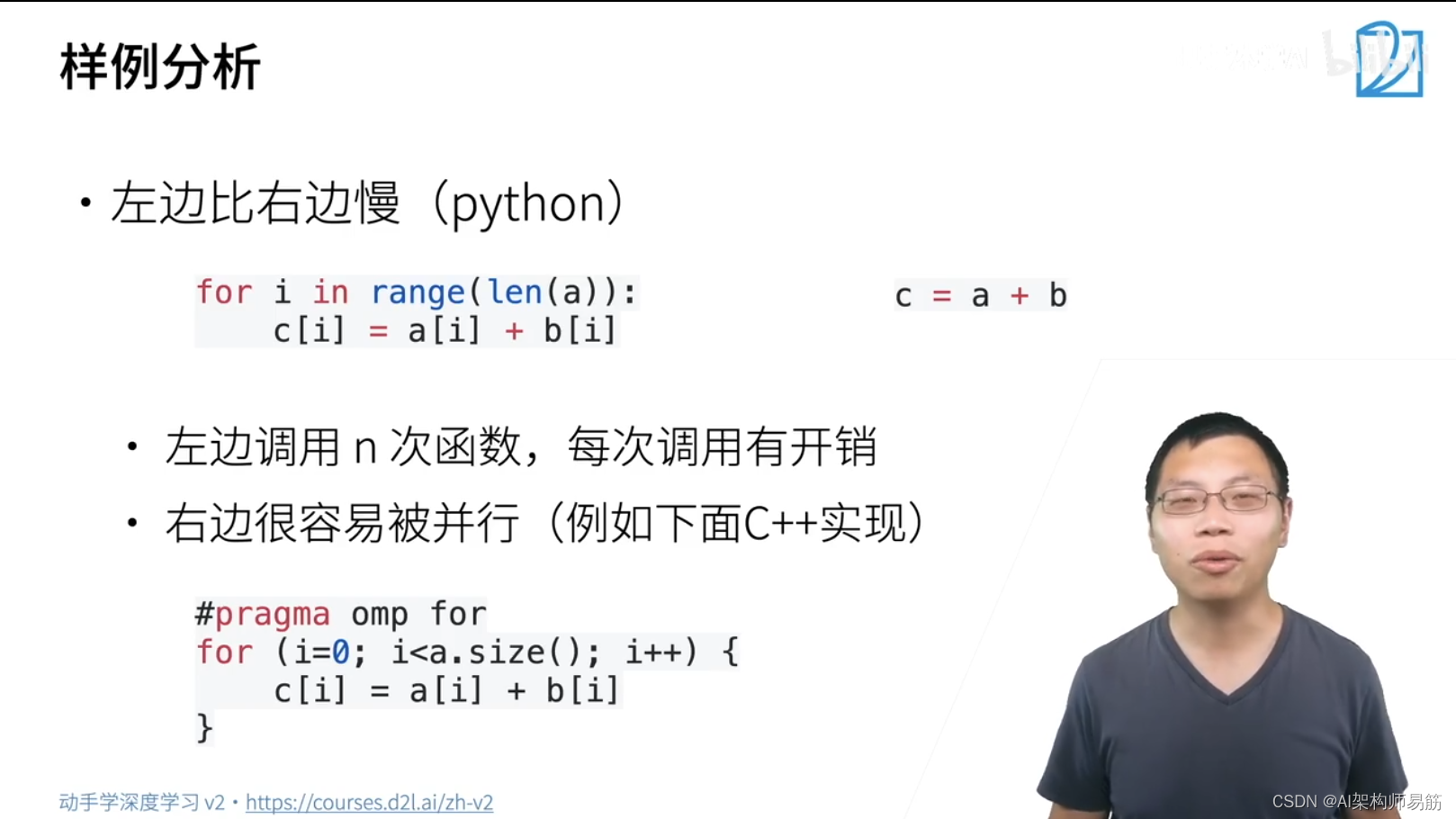
1. Deep Learning Hardware: CPU and GPU






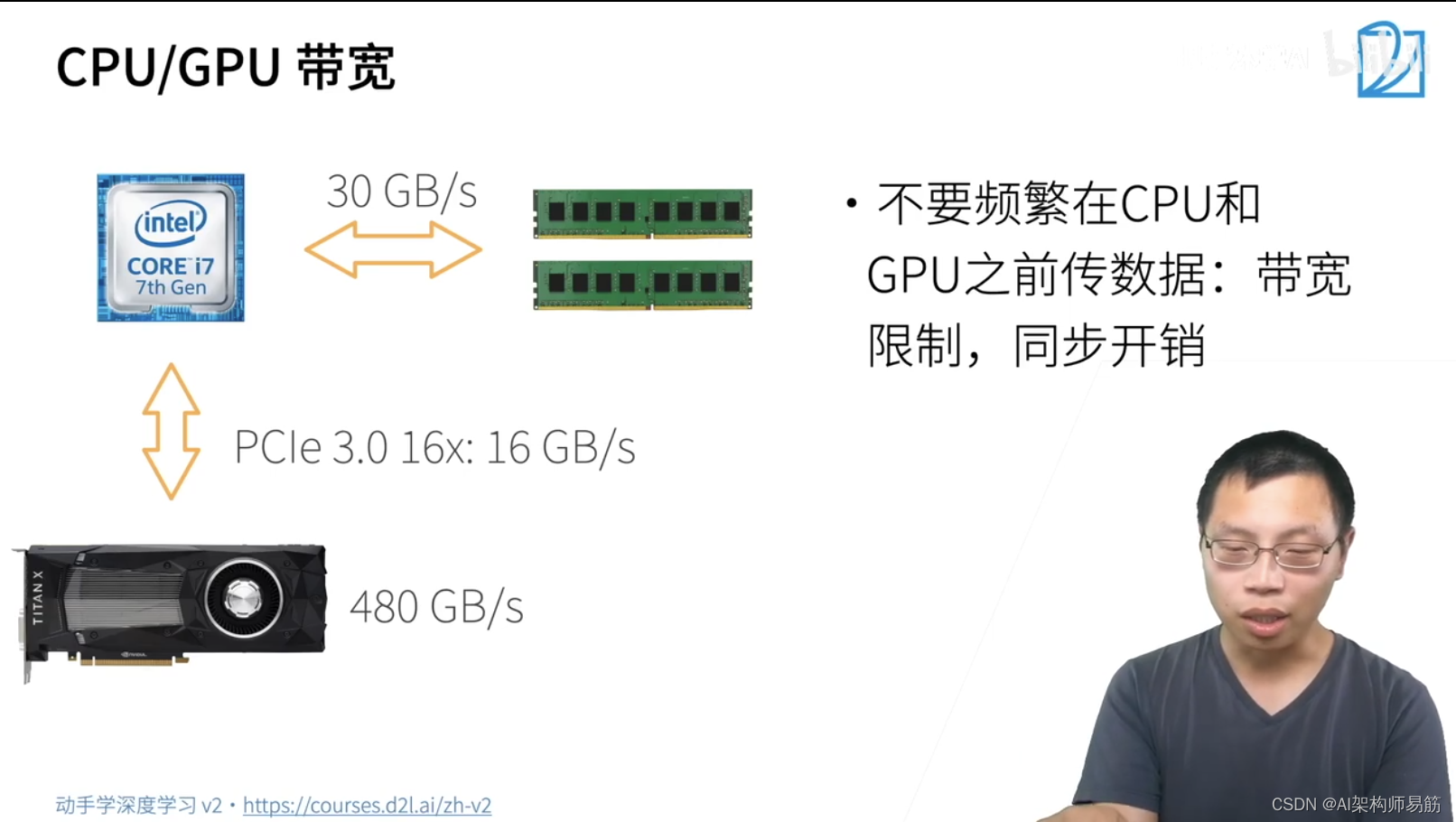



2. Q & A
-
- With more data, generalization can be improved.
-
- AlexNet uses a fully connected layer, and ResNet is smaller than AlexNet; but ResNet has a larger computational load than AlexNet.
-
- For deep neural networks, adding layers is also a hyperparameter.
-
- The development of hardware follows Moore's Law, and the amount of calculation is exponential in the early stage. The corresponding growth time, the complexity diagram is as follows.
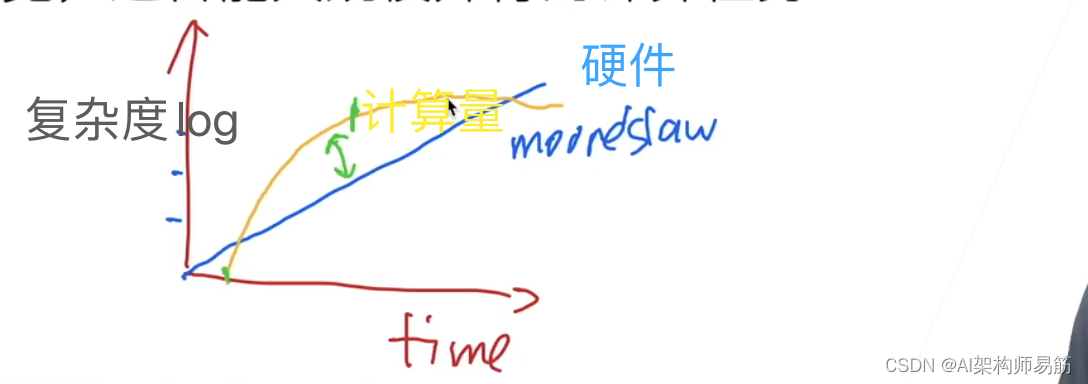
- The development of hardware follows Moore's Law, and the amount of calculation is exponential in the early stage. The corresponding growth time, the complexity diagram is as follows.
reference
https://www.bilibili.com/video/BV1TU4y1j7Wd/?spm_id_from=trigger_reload