Click on "Computer Vision Workshop" above and select "Star"
Dry goods delivered as soon as possible

Author丨Swimming Fish
Source丨Algorithm Advanced
An introduction to sample imbalance
1.1 The phenomenon of sample imbalance
Sample (category) Sample imbalance (class-imbalance) refers to the situation in which the number of training samples of different categories in the classification task is very different. Generally, the sample category ratio (Imbalance Ratio) (majority class vs minority class) is significantly larger than 1:1 (such as 4:1) can be classified as a problem of sample imbalance. In reality, sample imbalance is a common phenomenon, such as: financial fraud transaction detection, the order samples of fraudulent transactions are usually a very small part of the total number of transactions, and for some tasks, a few samples are more important.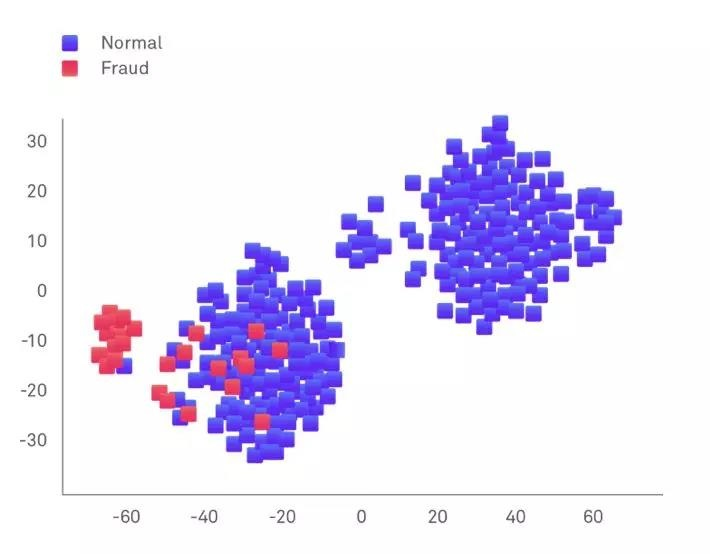
Note: This article mainly discusses the category imbalance of classification tasks, and the sample imbalance of regression tasks is described in " Delving into Deep Imbalanced Regression "
1.2 The fundamental impact of imbalance
Many times when we encounter the problem of sample imbalance, the immediate response is to "break" this imbalance. But what is the effect of sample imbalance? Is it necessary to solve it?
For example, in a case of fraud identification, the ratio of good and bad samples is 1000:1, and if we directly use this ratio to learn the model, because most of the samples thrown into the model are good, It is easy to learn a model that predicts all samples as good, and the probability accuracy of this prediction is still very high. What the model ultimately learns is not how to distinguish good from bad, but learns the prior information that "good is far more than bad", and it is enough to judge all samples as "good" based on this information. This deviates from the original intention of model learning to distinguish between good and bad.
Therefore, the fundamental impact of sample imbalance is that the model will learn the prior information of the proportion of samples in the training set, so that the actual prediction will focus on the majority class (which may lead to better accuracy for the majority class, while Minority classes are worse). As shown in the figure below (for example code, please see: github.com/aialgorithm ), the classification boundary in the case of class imbalance will be biased towards the area that "occupies" the minority class. More importantly, this will affect the model's learning of more essential features and affect the robustness of the model.
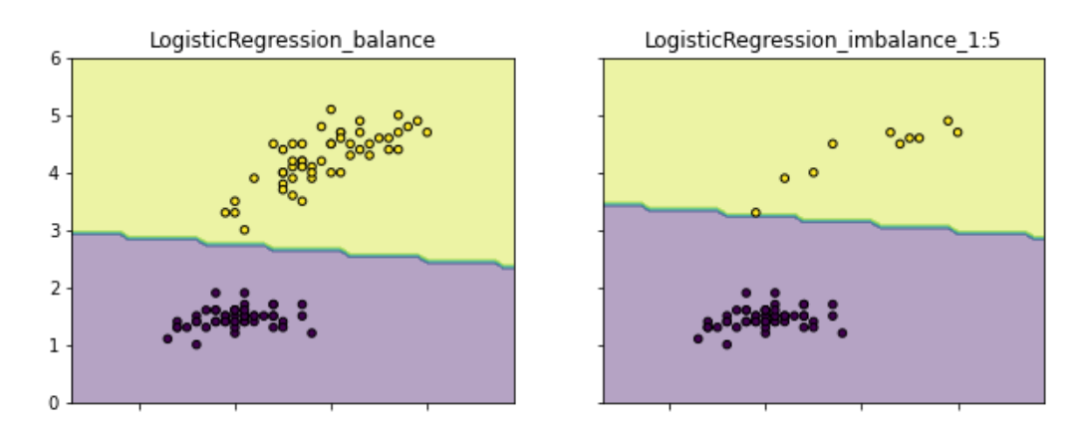
To sum up, by solving the sample imbalance, we can reduce the prior information of the model learning sample ratio, so as to obtain a model that can learn to distinguish the essential characteristics of good and bad .
1.3 Judging the necessity of resolving imbalances
Starting from the classification effect, the above example shows that the impact of imbalance on the classification results is not necessarily bad. When do we need to solve the sample imbalance ?
Judging whether the task is complex: The complexity of the complexity learning task is proportional to the sensitivity of sample imbalance (see "Survey on deep learning with class imbalance"). For simple linearly separable tasks, whether the sample is balanced has little effect. It should be noted that the complexity of the learning task is relative , and it must be comprehensively evaluated from the aspects of feature strength, data noise, and model capacity.
It is judged whether the distribution of training samples is consistent and stable with the distribution of real samples . If the distribution is consistent, the prior with this correct point has little effect on the prediction result. However, it also needs to be considered that if the real sample distribution changes later, the prior of this sample proportion will have side effects.
Judging whether the number of samples of a certain category is very rare, the model is likely to learn poorly, and the category imbalance needs to be solved, such as choosing some data enhancement methods, or trying a single-classification model such as anomaly detection.
Second, the sample imbalance solution
Basically, under the premise that the learning task is somewhat difficult, the unbalanced solution can be summed up as follows: by a certain method, the loss (or gradient) contribution of different categories of samples to the model learning is relatively balanced . In order to eliminate the bias of the model to different categories and learn more essential features. This paper discusses the solutions from the aspects of data samples, model algorithms, target (loss) functions, and evaluation indicators .
2.1 Sample level
2.1.1 Undersampling and oversampling
The most direct way to deal with it is to adjust the number of samples. Commonly used ones can be:
Undersampling: Reduce the number of majority classes (eg random undersampling, NearMiss, ENN).
Oversampling: Increase the number of samples of the minority class as much as possible (such as random oversampling, and 2.1.2 data augmentation methods) to achieve a balanced number of classes.
You can also combine the two for mixed sampling (such as Smote+ENN).
For details, please refer to [scikit-learn's imbalanced-learn.org/stable/user_guide.html and github's awesome-imbalanced-learning]
2.1.2 Data Augmentation
Data Augmentation is to process the representation of more data from the original data without substantially increasing the data, improve the quantity and quality of the original data, and approach the value generated by more data volume, thereby improving the quality of the original data. The learning effect of the model (in fact, it is also a method of oversampling. For the specific introduction and code, see [Data Enhancement] ). Common methods are listed below:
Data Augmentation Based on Sample Transformation
Sample transformation data enhancement is to use preset data transformation rules to augment existing data, including single-sample data enhancement and multi-sample data enhancement.
Single-sample enhancement (mainly used for images) : There are mainly geometric operations, color transformation, random erasure, adding noise and other methods to generate new samples, see the imgaug open source library.
Multi-sample enhancement : It is to construct the neighborhood of known samples in the feature space by combining and transforming multiple samples, mainly including the Smote class (see imbalanced-learn.org/stable/references/over_sampling.html), SamplePairing, Mixup and other methods value sample.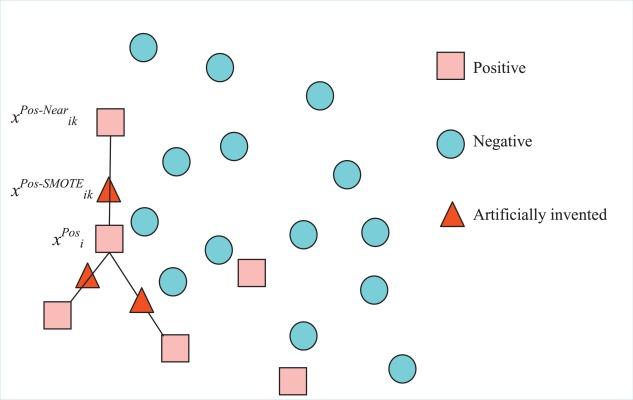
Data Augmentation Based on Deep Learning
Generative models such as Variational Auto-Encoding network (VAE) and Generative Adversarial Network (GAN), whose method of generating samples can also be used for data augmentation. Compared with the traditional data augmentation technology, this method based on network synthesis has a more complicated process, but the generated samples are more diverse.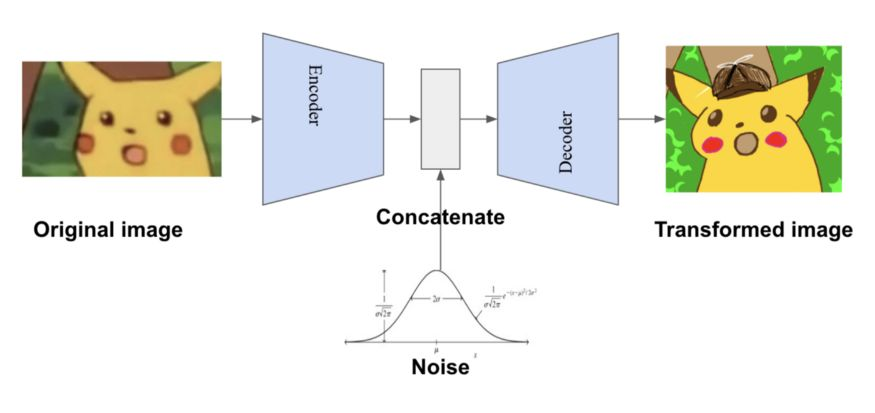
The methods to solve the imbalance at the data sample level need to pay attention to:
Random undersampling can lead to discarding samples with important information. If the computing performance is sufficient, sampling methods such as ENN, NearMiss, etc. can be considered for the distribution information of the data (usually the distance-based neighborhood relationship).
Random oversampling or data augmentation samples may also emphasize (or introduce) one-sided noise, leading to overfitting. It is also possible to introduce samples with little information. At this point, what needs to be considered is to adjust the sampling method, or select a better subset of the enhanced data through a semi-supervised algorithm (the idea of Pu-Learning can be used for reference) to improve the generalization ability of the model.
2.2 Layers of Loss Functions
The mainstream method at the loss function level is the commonly used cost-sensitive learning, which gives different penalties (weights) for different classification errors, and does not increase the computational complexity while adjusting the category balance. The following common methods:
2.2.1 class weight
This is the most commonly used 'class weight' method of the scikit model, If ‘balanced’, class weights will be given by n_samples / (n_classes * np.bincount(y)). If a dictionary is given, keys are classes and values are corresponding class weights. If None is given, the class weights will be uniform., class weight can provide different weights for samples of different categories (minority categories have higher weights), so that the model can balance the learning of various categories. As shown in the figure below, the minority class is given a higher weight to avoid the phenomenon that the decision is biased towards the majority class (the class weight can also be used as a hyperparameter search in addition to being set to balanced. For example code, see github.com/aialgorithm):
clf2 = LogisticRegression(class_weight={0:1,1:10}) # 代价敏感学习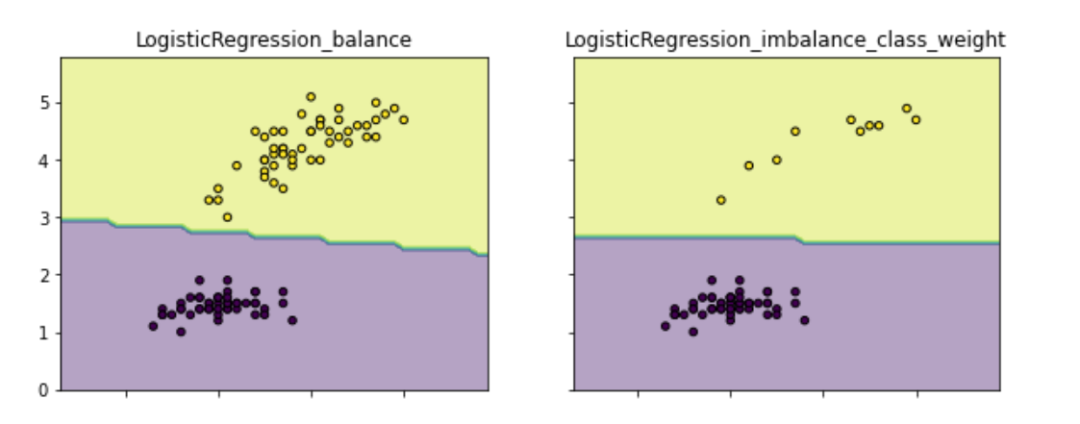
2.2.2 OHEM and Focal Loss
In this work, we first point out that the class imbalance can be summarized to the imbalance in difficulty and the imbalance in difficulty can be summarized to the imbalance in gradient norm distribution.
--The original text can be found in "Gradient Harmonized Single-stage Detector"
The general idea of the above is that the imbalance of categories can be attributed to the imbalance of difficult and easy samples, and the imbalance of difficult and easy samples can be attributed to the imbalance of gradients . Following this line of thought, both OHEM and Focal loss do two things: hard sample mining and class balancing. (There are other methods such as GHM, PISA, etc., you can understand by yourself)
The core of the OHEM (Online Hard Example Mining) algorithm is to select some hard examples (samples with diversity and high loss) as training samples to improve the learning effect of the model in a targeted manner. For the class imbalance problem of data, OHEM is more targeted.
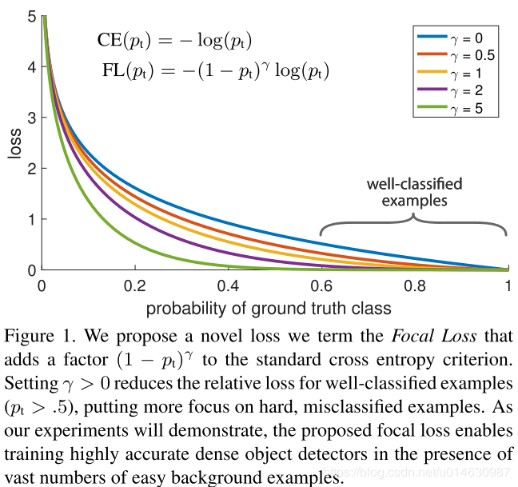
The core idea of Focal loss is to add different weights of categories and weights of difficult (high loss) samples (the following formula) on the basis of the cross entropy loss function (CE) to improve the model learning effect.
2.3 Model level
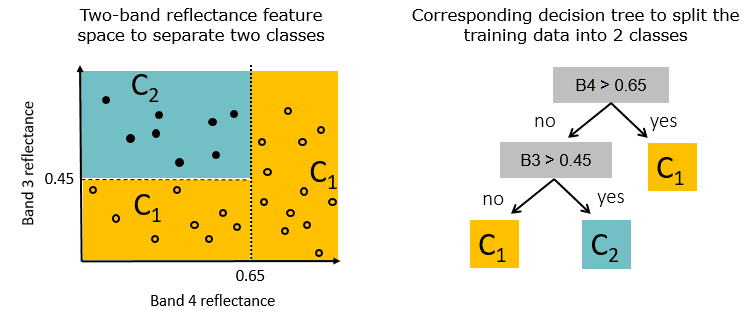
In terms of models, it is mainly to choose some models that are less sensitive to imbalance, for example, to compare the logistic regression model (lr learns the minimum loss of the full training samples, and naturally tends to reduce the loss caused by the majority of samples), the decision tree is in the The performance of unbalanced data is relatively better. The tree model divides the data recursively according to the gain (as shown in the figure below). The division process considers the local gain. The global sample is unbalanced, and the local space is not necessarily, so it is less sensitive ( but still biased). Related experiments can be found at arxiv.org/abs/2104.02240.
To solve the problem of imbalance, the more excellent method is based on sampling + ensemble tree model, which can perform well on class imbalanced data.
2.3.1 Sampling + ensemble learning
In simple terms, this type of method trains several classifiers for ensemble learning by repeatedly combining minority class samples with the same number of sampled majority class samples.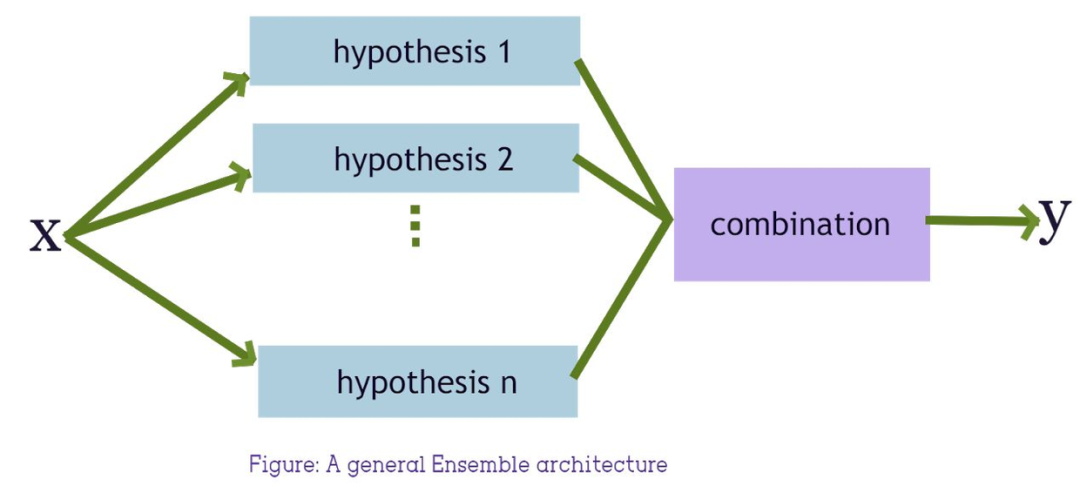
BalanceCascade BalanceCascade is based on Adaboost as the base classifier. The core idea is to use a training set with an equal number of majority classes and minority classes in each round of training, and then use the classifier to predict all the majority classes by controlling the classification threshold. FP (False Positive) rate, delete all the correctly judged classes, and then enter the next round of iteration to continue to reduce the number of majority classes.
EasyEnsemble EasyEnsemble is also based on Adaboost as the base classifier, that is, the majority class sample set is randomly divided into N subsets, and each subset sample is the same as the minority class sample, and then each majority class sample subset and minority class samples are combined respectively, The AdaBoost base classification model is used for training, and finally bagging integrates the base classifiers to obtain the final model. Example code can be found here: www.kaggle.com/orange90/ensemble-test-credit-score-model-example
Usually, when the noise of the dataset is small, BalanceCascade can be used, which can obtain better performance with a smaller number of base classifiers (serial-based ensemble learning methods are sensitive to noise and easy to overfit). In the case of large noise, EasyEnsemble, a serial + parallel-based ensemble learning method, bagging multiple Adaboost processes can offset some noise effects. In addition, there are other integration methods such as RUSB, SmoteBoost, balanced RF, etc. that can be understood by yourself.
2.3.2 Anomaly Detection
In the case of extreme class imbalance (such as only a few dozen samples in the minority class), it may be better to consider the classification problem as an anomaly detection problem.
Anomaly detection is the discovery of abnormal data that is inconsistent with the distribution of the dataset through data mining methods, also known as outliers, outlier detection, and so on. Unsupervised anomaly detection can be roughly divided into several categories according to its algorithm ideas: cluster-based methods, statistics-based methods, depth-based methods (isolated forests), classification models (one-class SVM), and neural network-based methods. (Autoencoder AE) and so on. The specific method introduction and code can be seen [Quick overview of abnormal detection methods]
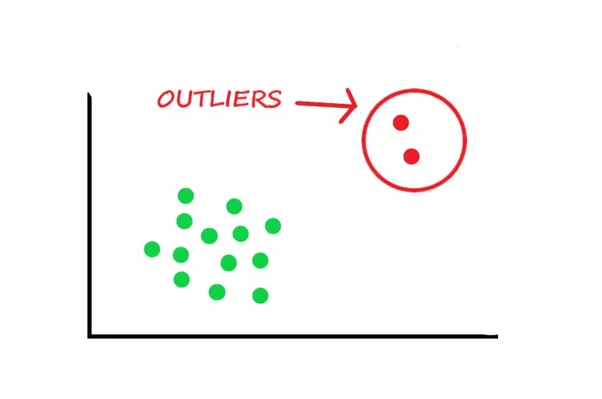
2.4 Decision-making and evaluation indicators
The focus of this section is how to make better decisions and objectively evaluate model performance under imbalanced data when we train the model with imbalanced data. For precision, recall, F1, and confusion matrix commonly used in classification, the different degrees of sample imbalance will significantly change the performance of these indicators.
For the prediction of the model under the category imbalance, we can move the classification threshold to adjust the model's preference for different categories (such as the model prefers to predict negative samples, biased to 0, and the corresponding classification threshold is also adjusted downward) to achieve decision-making the purpose of category balance. Here, the threshold for better performance can usually be selected through the PR curve.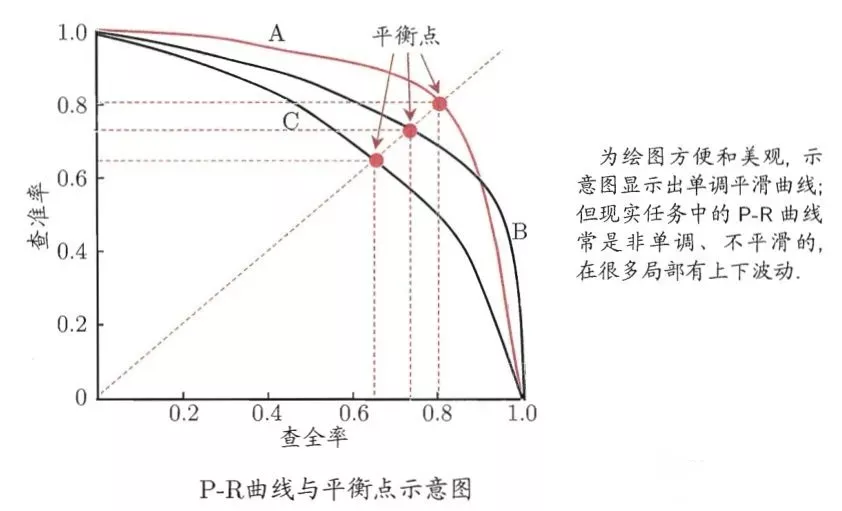
For model evaluation under category imbalance, AUC and AUPRC (better) can be used to evaluate model performance. The meaning of AUC is the area of the ROC curve, and the physical meaning of its value is: given two random samples, one positive and one negative, the predicted score of the positive sample is greater than the probability of the negative sample. AUC is insensitive to the proportion of positive and negative samples. Even if the proportion of positive and negative samples changes greatly, the area of the ROC curve will not change greatly. For details, see [Assessment Indicators]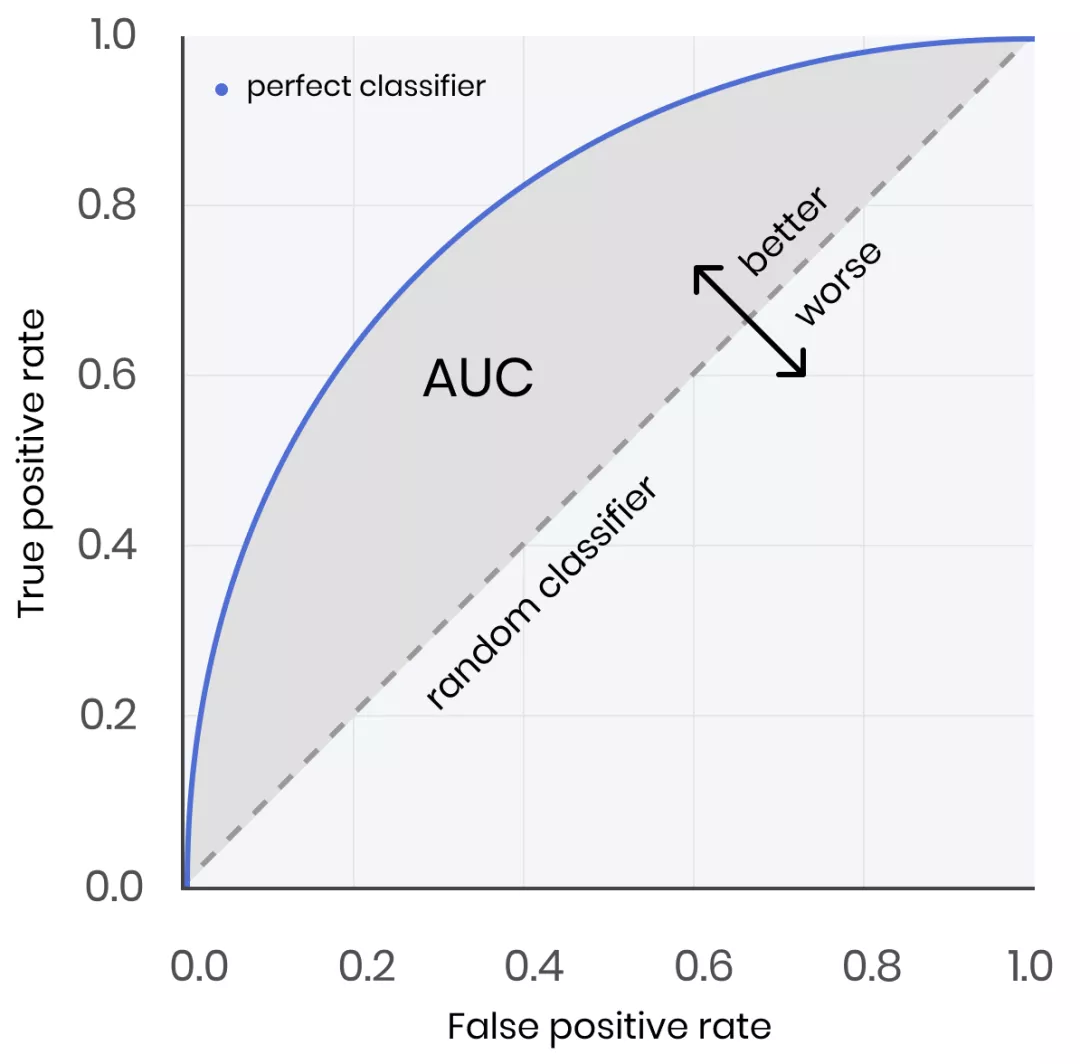
summary:
By solving the sample imbalance, we can reduce the prior information of the model learning sample ratio, so as to obtain a model that can learn to distinguish the essential characteristics of good and bad.
The unbalanced solution can be attributed to: by a certain method, the loss (or gradient) contribution of different categories of samples to the model learning is relatively balanced. Specifically, it can be optimized from the aspects of data samples, model algorithms, objective functions, evaluation indicators, etc. Among them, data enhancement, cost-sensitive learning and sampling + integrated learning are more commonly used, and the effect is relatively obvious. In fact, the solution to the unbalanced problem is also a process of selecting, combining and adjusting methods based on the actual situation, and optimizing them in the verification process.
This article is for academic sharing only, if there is any infringement, please contact to delete the article.
Dry goods download and study
Backstage reply: Barcelona Autonomous University courseware, you can download the 3D Vison high-quality courseware accumulated by foreign universities for several years
Background reply: computer vision books, you can download the pdf of classic books in the field of 3D vision
Backstage reply: 3D vision courses, you can learn excellent courses in the field of 3D vision
3D visual quality courses recommended:
1. Multi-sensor data fusion technology for autonomous driving
2. A full-stack learning route for 3D point cloud target detection in the field of autonomous driving! (Single-modal + multi-modal/data + code)
3. Thoroughly understand visual 3D reconstruction: principle analysis, code explanation, and optimization and improvement
4. The first domestic point cloud processing course for industrial-level combat
5. Laser-vision -IMU-GPS fusion SLAM algorithm sorting
and code
explanation
Indoor and outdoor laser SLAM key algorithm principle, code and actual combat (cartographer + LOAM + LIO-SAM)
9. Build a structured light 3D reconstruction system from scratch [theory + source code + practice]
10. Monocular depth estimation method: algorithm sorting and code implementation
11. The actual deployment of deep learning models in autonomous driving
12. Camera model and calibration (monocular + binocular + fisheye)
13. Heavy! Quadcopters: Algorithms and Practice
14. ROS2 from entry to mastery: theory and practice
Heavy! Computer Vision Workshop - Learning Exchange Group has been established
Scan the code to add a WeChat assistant, and you can apply to join the 3D Vision Workshop - Academic Paper Writing and Submission WeChat exchange group, which aims to exchange writing and submission matters such as top conferences, top journals, SCI, and EI.
At the same time , you can also apply to join our subdivision direction exchange group. At present, there are mainly ORB-SLAM series source code learning, 3D vision , CV & deep learning , SLAM , 3D reconstruction , point cloud post-processing , automatic driving, CV introduction, 3D measurement, VR /AR, 3D face recognition, medical imaging, defect detection, pedestrian re-identification, target tracking, visual product landing, visual competition, license plate recognition, hardware selection, depth estimation, academic exchanges, job search exchanges and other WeChat groups, please scan the following WeChat account plus group, remarks: "research direction + school/company + nickname", for example: "3D vision + Shanghai Jiaotong University + Jingjing". Please remark according to the format, otherwise it will not be approved. After the addition is successful, the relevant WeChat group will be invited according to the research direction. Please contact for original submissions .

▲Long press to add WeChat group or contribute

▲Long press to follow the official account
3D vision from entry to proficient knowledge planet : video courses for 3D vision field ( 3D reconstruction series , 3D point cloud series , structured light series , hand-eye calibration , camera calibration , laser/vision SLAM, automatic driving, etc. ), summary of knowledge points , entry and advanced learning route, the latest paper sharing, and question answering for in-depth cultivation, and technical guidance from algorithm engineers from various large factories. At the same time, Planet will cooperate with well-known companies to release 3D vision-related algorithm development positions and project docking information, creating a gathering area for die-hard fans that integrates technology and employment. Nearly 4,000 Planet members make common progress and knowledge to create a better AI world. Planet Entrance:
Learn the core technology of 3D vision, scan and view the introduction, unconditional refund within 3 days

There are high-quality tutorial materials in the circle, which can answer questions and help you solve problems efficiently
I find it useful, please give a like and watch it