Fall in love and kill good friends-arrays and linked lists
As the two storage methods of linear tables-linked lists and arrays, these have their own advantages and disadvantages for good friends who love and kill each other. Next, we sort out these two methods.
In an array , all elements are stored consecutively in a section of memory, and each element occupies the same memory size. This makes the array have the ability to quickly access data through subscripts.
However, the shortcomings of continuous storage are also obvious. The cost of adding and deleting elements is very high for increasing capacity, and the time complexity is O(n).
To increase the array capacity, you need to apply for a new memory first, and then copy the original elements. If necessary, you may have to delete the original memory.

When deleting an element, you need to move all elements after the deleted element to ensure that all elements are continuous. When adding an element, you need to move the specified position and all the following elements, and then insert the new element to the specified position. If the capacity is insufficient, you need to expand the capacity first.
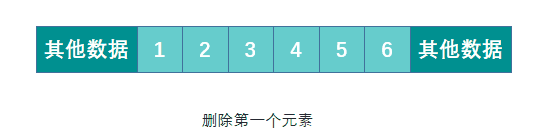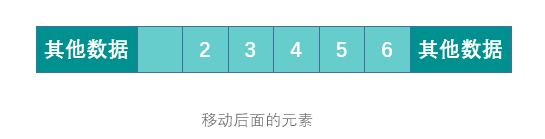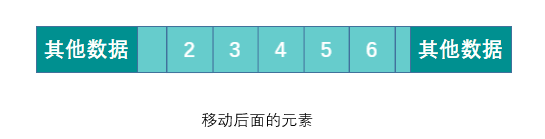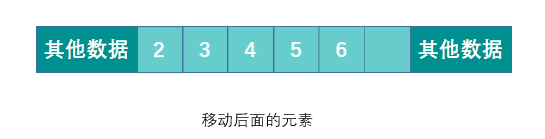
Summarize the advantages and disadvantages of arrays:
- Advantages: Fast random reading and writing can be realized according to the offset.
- Disadvantages: Expansion, adding and deleting elements is extremely slow.
The linked list is composed of several nodes, and each node contains a data field and a pointer field. The node structure is shown in the figure below:
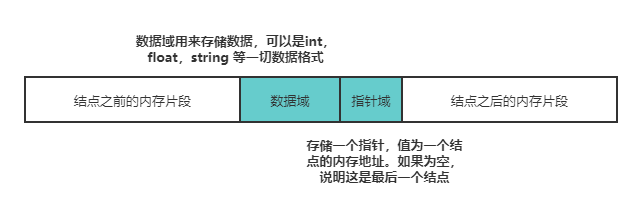
Generally speaking, there will be only one node in the linked list whose pointer field is empty, and that node is the end node . The pointer fields of other nodes will store the memory address of a node. There will only be one node in the linked list whose memory address is not stored in the pointer field of other nodes, and this node is called the head node .
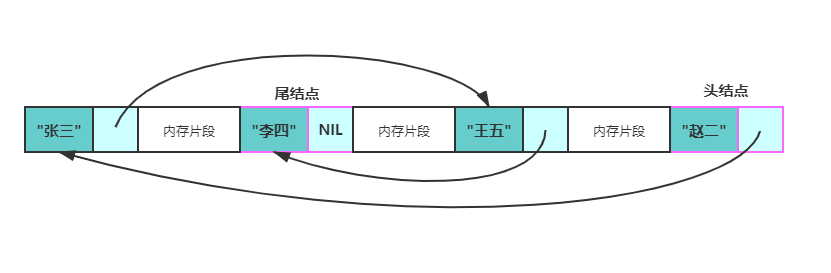
The storage method of the linked list allows it to be inserted and deleted efficiently at the specified position, and the time complexity is O(1).
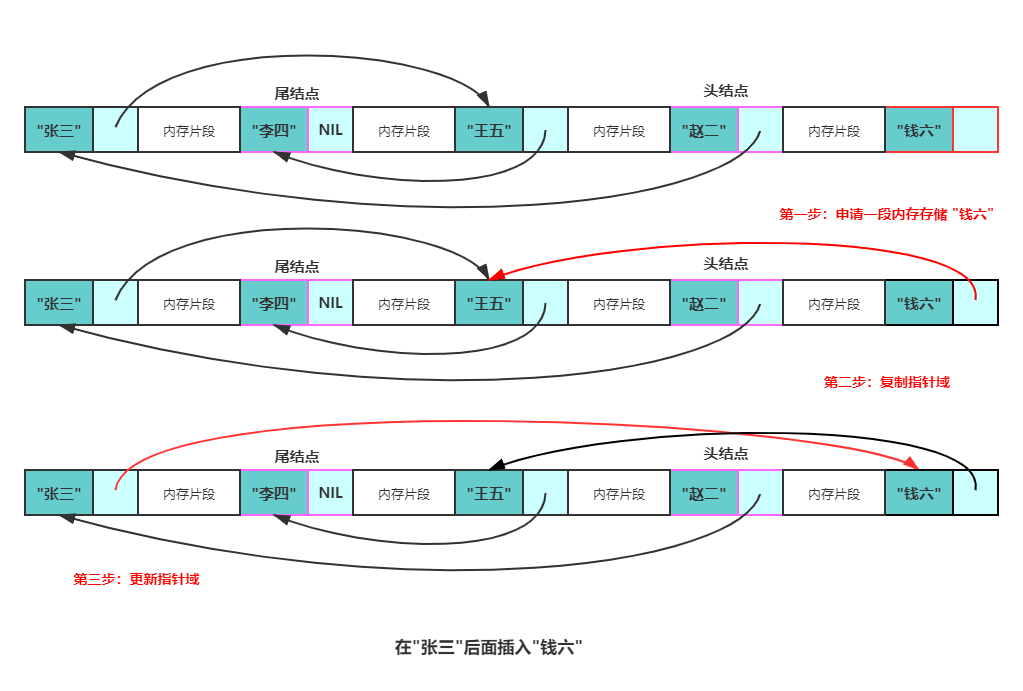
There are three steps to add a node q after node p:
- Apply for a section of memory to store q (you can use the memory pool to avoid frequent application and destruction of memory).
- Copy the pointer field data of p to the pointer field of q.
- Update the pointer field of p to the address of q.
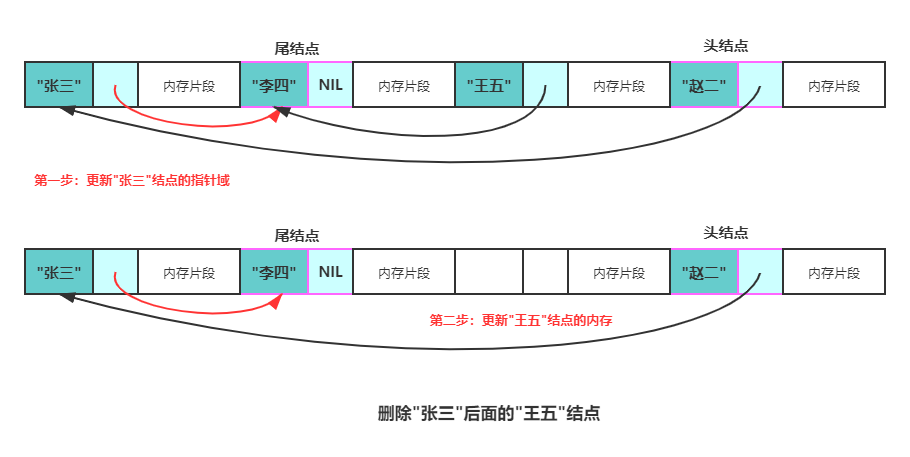
There are two steps to delete the node q after the node p:
- Copy the pointer field of q to the pointer field of p.
- Release the memory of the q node.
The main code of the linked list
#include <bits/stdc++.h>
using namespace std;
//定义一个结点模板
template<typename T>
struct Node {
T data;
Node *next;
Node() : next(nullptr) {}
Node(const T &d) : data(d), next(nullptr) {}
};
//删除 p 结点后面的元素
template<typename T>
void Remove(Node<T> *p) {
if (p == nullptr || p->next == nullptr) {
return;
}
auto tmp = p->next->next;
delete p->next;
p->next = tmp;
}
//在 p 结点后面插入元素
template<typename T>
void Insert(Node<T> *p, const T &data) {
auto tmp = new Node<T>(data);
tmp->next = p->next;
p->next = tmp;
}
//遍历链表
template<typename T, typename V>
void Walk(Node<T> *p, const V &vistor) {
while(p != nullptr) {
vistor(p);
p = p->next;
}
}
int main() {
auto p = new Node<int>(1);
Insert(p, 2);
int sum = 0;
Walk(p, [&sum](const Node<int> *p) -> void { sum += p->data; });
cout << sum << endl;
Remove(p);
sum = 0;
Walk(p, [&sum](const Node<int> *p) -> void { sum += p->data; });
cout << sum << endl;
return 0;
}
Summary of interview questions
The inability to efficiently obtain the length and the inability to quickly access the elements based on the offset are two disadvantages of the linked list. However, in interviews, we often encounter problems such as obtaining the kth element from the bottom, obtaining the element in the middle position, judging whether there are loops in the linked list, judging the length of the loop, and other issues related to length and position. These problems can be solved through the flexible use of dual pointers.
Tips: Double pointer is not a fixed formula, but a way of thinking~
1. "The problem with the kth element from the bottom"
There are two pointers p and q, both of which point to the head node at the beginning. First, let p move k times along next. At this time, p points to the k+1th node, q points to the head node, and the distance between the two pointers is k. Then, move p and q at the same time until p points to empty, then q points to the kth node from the bottom. You can refer to the following figure to understand:
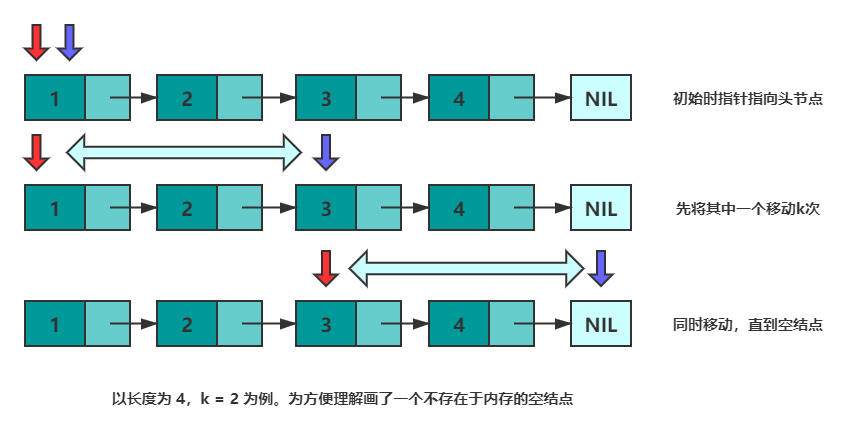
class Solution {
public:
ListNode* getKthFromEnd(ListNode* head, int k) {
ListNode *p = head, *q = head; //初始化
while(k--) { //将 p指针移动 k 次
p = p->next;
}
while(p != nullptr) {//同时移动,直到 p == nullptr
p = p->next;
q = q->next;
}
return q;
}
};
2. The problem of obtaining intermediate elements
There are two pointers fast and slow, which initially point to the head node. Each time you move, fast walks backwards twice and slow walks backwards once, until fast cannot walk backwards twice. This makes after each round of movement. The distance between fast and slow will increase by one . Suppose the linked list has n elements, then at most n/2 rounds are moved. When n is an odd number when, slow just point intermediate node , when n is an even number when, slow exactly point to two intermediate nodes forward a (how it can be considered under the junction point to a point?).
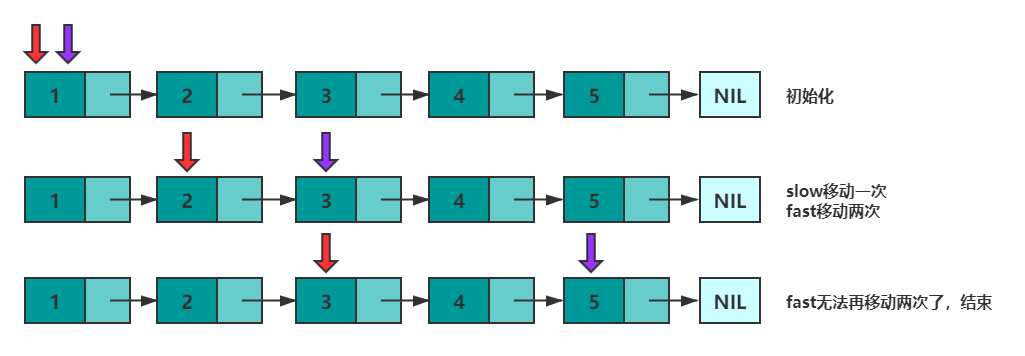
The following code realizes that the slow pointer points to the lower node when n is an even number .
class Solution {
public:
ListNode* middleNode(ListNode* head) {
ListNode *p = head, *q = head;
while(q != nullptr && q->next != nullptr) {
p = p->next;
q = q->next->next;
}
return p;
}
};
3. Is there a ring problem?
If the next pointer of the end node points to any other node, then there is a ring in the linked list.
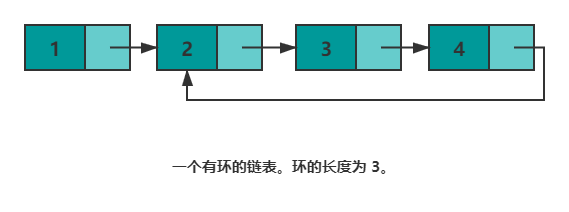
In the previous part, the characteristics of the fast and slow pointers are summarized-the distance between the two will increase by one after each round of movement. The following will continue to use this feature to solve the ring problem.
When a linked list has a ring, the fast and slow pointers will fall into the ring and move infinitely, and then it becomes a problem of tracking . Imagine running in the playground. As long as you keep running, the fast will always catch up with the slow. When both pointers enter the ring, each round of movement increases the distance from the slow pointer to the fast pointer by one, and at the same time the distance from the fast pointer to the slow pointer also decreases by one. As long as it keeps moving, the fast pointer will always catch up with the slow pointer.
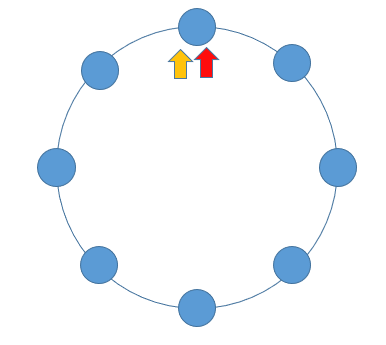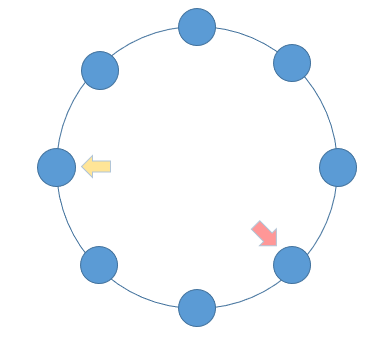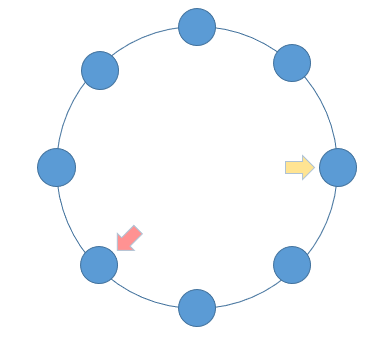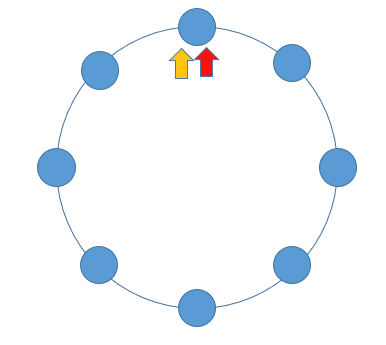
According to the above expression, if there is a ring in a linked list, then the fast and slow pointers will inevitably meet. The implementation code is as follows:
class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode *slow = head;
ListNode *fast = head;
while(fast != nullptr) {
fast = fast->next;
if(fast != nullptr) {
fast = fast->next;
}
if(fast == slow) {
return true;
}
slow = slow->next;
}
return nullptr;
}
};
4. If there is a loop, how to judge the length of the loop?
The method is to continue moving after the fast and slow pointers meet until they meet for the second time. The number of movements between two encounters is the length of the loop.