Summary
We explore the common, non-hierarchical visual transducer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without redesigning the hierarchical backbone for pretraining. With minimal adjustments to fine-tuning, our vanilla backbone detector can achieve competitive results. Surprisingly, we observed that: (i) building a simple feature pyramid from single-scale feature maps (without common FPN designs) is sufficient; (ii) using windowed attention (without shift) is sufficient Spread blocks across windows. By training common ViT master interventions as Masked Autoencoders (MAE), our detector ViTDet can compete with all previous leading methods based on hierarchical backbones, reaching 61.3 APbox on COCO dataset using only ImageNet-1K pre-training. We hope that our study will draw attention to the research on common backbone detectors. Code will be released soon.
1 Introduction
Modern object detectors usually consist of a detection task-agnostic backbone feature extractor and a set of necks and heads that contain detection-specific priors. Common components in neck/head may include Region of Interest (RoI) operations, Region Proposal Network (RPN) or Anchors, Feature Pyramid Network (FPN), etc. If the design of the neck/head for a particular task is decoupled from the design of the backbone, they may evolve in parallel. Empirically, object detection research benefits from largely independent exploration of a common backbone and detection-specific modules. For a long time, these backbones have been multi-scale, hierarchical architectures due to the practical design of Convolutional Networks (ConvNets), which heavily influences neck/head designs (e.g. FPN) for detecting multi-scale objects.
Over the past year, Vision Transformers (ViT) have become a powerful pillar of visual identity. Unlike typical ConvNets, the original ViT is a vanilla, non-hierarchical architecture that always maintains single-scale feature maps. Its "minimalist" quest encounters challenges when applied to object detection - for example, how do we handle multi-scale objects in downstream tasks with a simple backbone pretrained upstream? Is plain ViT too inefficient for high resolution inspection images? One solution to abandoning this pursuit is to reintroduce the layered design to the backbone. The solutions, such as Swin Transformers and related works, can inherit ConvNet-based detector designs and show successful results.
In this work, we pursue a different direction: we explore object detectors using only plain, non-hierarchical backbones. If this direction is successful, it will be able to use the original ViT backbone for object detection; this will decouple the pre-training design from the fine-tuning requirement, maintaining the independence of upstream and downstream tasks, as in ConvNet-based research. This direction also partially follows ViT's philosophy of "reducing inductive bias" in the pursuit of generic features. Since non-local self-attention computations can learn translation-invariant features, they can also learn scale-invariant features from some form of supervised or self-supervised pre-training.
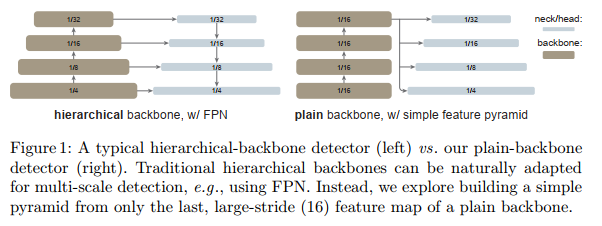
In our research, our goal is not to develop new components. Instead, we made minimal adjustments sufficient to overcome the above challenges. In particular, our detector only builds a simple feature pyramid from the last feature map of the vanilla ViT backbone (Fig. 1). This abandons the FPN design and abandons the requirement for a layered backbone. To efficiently extract features from high-resolution images, our detector uses simple non-overlapping window attention (no "shift", unlike). A small number of cross-window blocks (e.g., 4) that may be global attention or convolution are used to propagate information. These adjustments are made only during fine-tuning and do not change the pre-training.
Our simple design has proven to yield surprising results. We find that in the case of a plain ViT backbone, the FPN design is not necessary and its benefits can be efficiently obtained by a simple pyramid constructed from a large-stride (16) single-scale map. We also found that window attention is sufficient as long as the information is spread well in the window of a small number of layers.
Even more surprising is that our common backbone detector named ViTDet can compete with leading hierarchical backbone detectors (eg Swin, MViT) in some cases. Pre-trained with Masked Autoencoder (MAE) [23], our vanilla backbone detector can outperform hierarchical detectors pre-trained with supervised supervision on ImageNet-1K/21K [11] (Fig. 3). For larger models, the gains are more prominent in size. The competitiveness of our detector is observed under different object detector frameworks including Mask R-CNN, Cascade Mask R-CNN [4] and their enhancements. We report 61.3 APbox on the COCO dataset [37] with a vanilla ViT-Huge backbone, pre-trained with only ImageNet-1K without labels. We also show competitive results on the long-tailed LVIS detection dataset. While these strong results may be partly attributable to the effectiveness of MAE pre-training, our study suggests that generic backbone detectors may be promising, challenging the entrenched location of hierarchical backbones for object detection.
In addition to these results, our approach retains the idea of separating the detector-specific design from the task-agnostic backbone. This philosophy contrasts with the trend of redesigning the Transformer backbone to support multi-scale hierarchies. In our case, detection-specific priors are only introduced during fine-tuning, without prior-tuning the backbone design in pre-training. This makes our detector compatible with ViT development along various directions that are not necessarily limited by hierarchical constraints, such as block design, self-supervised learning, and scaling. We hope our research can inspire future research on common backbone object detection.
2. Related work
** Object detector backbone. **Pioneered by the work of R-CNN [20], object detection and many other vision tasks employ a pre-training + fine-tuning paradigm: a general, task-independent backbone is pre-trained by supervised or self-supervised training, and its structure It was subsequently modified and adapted to downstream tasks. The main backbone in computer vision are various forms of ConvNets.
Early neural network detectors were initially presented based on single-scale feature maps. Although they use the default layered ConvNet backbone, in principle they apply to any normal backbone. SSD is one of the first works to exploit the hierarchical nature of the ConvNet backbone (eg, the last two stages of the VGG network). FPN pushes this direction further through lateral and top-down connections by using all stages of a hierarchical backbone. FPN designs are widely used in object detection methods.
ViT is a powerful alternative to standard ConvNets for image classification. The original ViT was a simple, non-layered architecture. Various layered Transformers have been proposed, such as Swin, MViT, PVT, and PiT. These methods inherit some of the designs of ConvNets, including hierarchical and translation-equivariant priors (eg, convolution, pooling, sliding windows). Therefore, it is relatively straightforward to replace the ConvNet with these backbones for object detection.
Ordinary backbone detector . The success of ViT has inspired the frontiers of pushing the common backbone of object detection. Recently, UViT was presented as a single-scale Transformer for object detection. UViT studies the network width, depth and input resolution of common ViT backbones under the object detection metrics. A progressive window attention strategy is proposed to address the high-resolution input problem. Unlike UViT, which modifies the architecture during pre-training, our research focuses on the original ViT architecture without prior specification for detection. Our study maintains the task-agnostic nature of the backbone, so it can support the wide range of available ViT backbones and their future improvements. Our approach separates the backbone design from the detection task, a key motivation for pursuing a generic backbone.
UViT uses single-scale feature maps as detector heads, while our method builds a simple pyramid over the single-scale backbone. In the context of our study, the entire detector must be single-scale, which is an unnecessary limitation. Note that the full UViT detector also has various forms of multi-scale priors (e.g., RPN and RoIAlign) as it is based on Cascade Mask R-CNN [4]. In our study, we focus on utilizing pre-trained common backbones and we do not restrict the design of the detector neck/head.
Object detection method . Object detection is a booming research area that employs methods with different properties—for example, two-stage versus one-stage, anchor-based versus anchor-free, region-based versus query-based (DETR). Research on different methods continues to advance the understanding of the object detection problem. Our research suggests that the themes of the "common vs. layered" backbone are worth exploring and may lead to new insights.
3. Method
Our goal is to remove the hierarchical constraints on the backbone and enable exploration of common backbone object detection. To this end, we aim to adapt a simple backbone to the object detection task only during fine-tuning with minimal modifications. After these adaptations, any detector head can in principle be applied, for which we chose to use Mask R-CNN and its extensions. Our goal is not to develop new components; instead, we focus on what new insights can be drawn from our explorations.
Simple feature pyramid . FPN is a common solution for building in-network pyramids for object detection. If the backbone is hierarchical, the motivation of FPN is to combine high-resolution features from early stages with stronger features from later stages. This is achieved through top-down and lateral connections in FPN [35] (Fig. 1 left).
If the backbone is non-hierarchical, the basis for FPN motivation is lost, since all feature maps in the backbone have the same resolution. In our scenario, we only use the last feature map in the backbone, which should have the strongest features. On this map, we apply a set of convolutions or deconvolutions in parallel to generate multi-scale feature maps. Specifically, using a scale of 1 16 \frac{1}{16}161(stride = 16) for the default ViT feature map, we use stride { 2 , 1 , 1 2 , 1 4 } \left\{2,1, \frac{1}{2}, \frac{1}{ 4}\right\}{ 2,1,21,41} , where the fractional stride represents deconvolution, resulting in multiple scales{ 1 32 , 1 16 , 1 8 , 1 4 } \left\{\frac{1}{32}, \frac{1}{16}, \frac{1}{8}, \frac{1}{4}\right\}{ 321,161,81,41} features. We call this the "Simple Feature Pyramid" (Figure 1 right).
The strategy of constructing multi-scale feature maps from a single map is related to that of SSD. However, our scenario involves upsampling from deep, low-resolution feature maps, which in contrast to take advantage of shallower feature maps. In hierarchical backbones, upsampling is usually assisted by lateral connections; in plain ViT backbones, we empirically find that this is not necessary (Section 4), and that simple deconvolution is sufficient. We hypothesize that this is because ViT can rely on positional embeddings to encode positions, and also because high-dimensional ViT patch embeddings do not necessarily discard information.
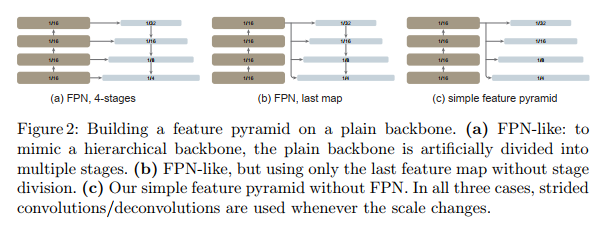
We will compare with two FPN variants also built on the common backbone (Fig. 2). In the first variant, the backbone is artificially divided into stages to mimic the stages of a hierarchical backbone, and lateral and top-down connections are applied (Fig. 2(a)). The second variant is similar to the first, but only uses the last map instead of the divided stage (Fig. 2(b)). We show that these FPN variants are not required (Section 4).
Backbone adaptation. Object detectors benefit from high-resolution input images, but computing global self-attention across the entire backbone is prohibitive and slow in memory. In this study, we focus on scenarios where the pretrained backbone performs global self-attention, and then adapts to higher-resolution inputs during fine-tuning. This contrasts with recent approaches to directly modify attention computation using bone intervention training (eg, [40, 16]). Our scenario enables us to use the original ViT backbone for detection without redesigning the pretrained architecture.
We explore using windowed attention with several cross-window blocks [52]. During fine-tuning, given a high-resolution feature map, we divide it into regular non-overlapping windows. Self-attention is computed within each window. This is called "constrained" self-attention in the original Transformer [52].
Unlike Swin, we don't "move" [40] windows across layers. To allow information to propagate, we use a very small number (by default, 4) of blocks that can span windows. We evenly divide the pretrained backbone into 4 block subsets (eg, 6 in each subset for the 24-block ViT-L). We apply a propagation strategy in the last block of each subset. We study these two strategies:
(i) Global Propagation. We perform global self-attention in the last block of each subset. Due to the small number of global blocks, the memory and computational costs are feasible. This is similar to the hybrid window attention used in conjunction with FPN in [32].
(ii) Convolutional propagation. As an alternative, we add an extra convolutional block after each subset. A convolution block is a residual block [26], consisting of one or more convolutions and an identity shortcut. The last layer in the block is initialized to zero, so the initial state of the block is an identity [21]. Initializing a block as an identity allows us to insert it anywhere in the pretrained backbone without corrupting the initial state of the backbone.
Our backbone adaptation is simple and makes detection fine-tuning compatible with global self-attention pre-training. As mentioned before, there is no need to redesign the pretrained architecture.
discuss. Object detectors contain components that can be task-agnostic, such as backbone, and other task-specific components, such as RoI headers. This model decomposition enables task-agnostic components to be pre-trained with non-detection data (e.g. ImageNet), which may provide an advantage since detection training data is relatively scarce.
From this perspective, it becomes reasonable to pursue a backbone that contains less inductive bias, as the backbone can be efficiently trained using large-scale data and/or self-supervision. In contrast, detection of task-specific components has relatively little data available and may still benefit from additional inductive bias. While the pursuit of detection heads with less induced bias is an active area of work, leading methods like DETR are difficult to train and still benefit from detection-specific priors.
Motivated by these observations, our work follows the spirit of the original plain ViT paper in the backbone of the detector. While the discussion in the ViT paper focuses on reducing the inductive bias of translation equivariance, in our case it is about reducing or even having no inductive bias on scale equivariance in the backbone. We hypothesize that the way common backbone achieves scale equivariance is to learn priors from the data, similar to how it learns translation equivariance and locality without convolution.
Our goal is to demonstrate the feasibility of this approach. Therefore, we choose to implement our method using standard detection-specific components (i.e., Mask R-CNN and its extensions). Exploring less induced bias in the detection head is an open and interesting direction for future work. We hope it can benefit from our work here and build upon it.
implement. We use vanilla ViT-B, ViT-L, ViT-H [13] as the pretrained backbone. We set the block size to 16, so the feature map scale is 1/16, i.e. stride = 16. Our detector head follows Mask R-CNN [24] or Cascade Mask R-CNN [4], whose architecture details are in the appendix. The input images are 1024×1024, augmented by large-scale dithering [18] during training. Due to this heavy regularization, we fine-tune up to 100 epochs in COCO. We use the AdamW optimizer [41] and use the baseline version to search for the best hyperparameters. More details are in the appendix.
4. Experiment
4.1 Ablation research and analysis
We conduct ablation experiments on the COCO dataset [37]. We train on train2017 split and evaluate on val2017 split. We report results for bounding box object detection (APbox) and instance segmentation (APmask).
By default, we use the simple feature pyramid and global propagation described in Section 3. We use 4 spreading blocks, evenly placed in the backbone. We initialize the backbone with MAE [23] pretrained on unlabeled IN-1K. We remove these defaults and discuss our key observations below.
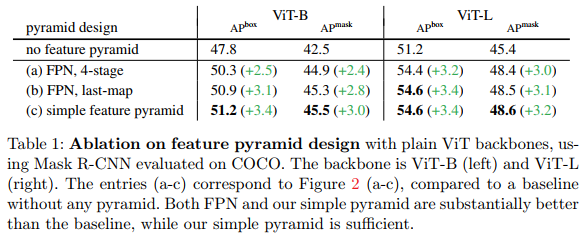
A simple feature pyramid is sufficient. In Table 1, we compare the feature pyramid construction strategies shown in Figure 2.
We study baselines without feature pyramids: both RPN and RoI heads are applied to the final single scale of the backbone ( 1 16 \frac{1}{16}161) feature map. This situation is similar to the original Faster R-CNN before FPN was proposed. All feature pyramid variants (Table 1ac) significantly outperform this baseline, improving AP by up to 3.4 points. We note that using a single-scale feature map does not imply that the detector is single-scale: RPN heads have multi-scale anchors, while RoI heads operate on multi-scale regions. Even so, feature pyramids are beneficial. This observation is consistent with observations made in the FPN paper regarding hierarchical backbones.
However, without the need for FPN design, our simple feature pyramid is sufficient for ordinary ViT backbones to enjoy the benefits of pyramids. To eliminate this design, we mimic the FPN architecture (ie, top-down and lateral connections), as shown in Fig. 2(a,b). Table 1 (a, b) shows that while both FPN variants achieve strong gains over the baseline without pyramids (as widely observed with the original FPN on hierarchical backbones), they do not No better than our simple feature pyramid. The original FPN [35] works by combining low-resolution, stronger feature maps with higher-resolution, weaker feature maps. This foundation is lost when the backbone is flat and there is no high-resolution map, which may explain why our simple pyramid is sufficient.
Our ablation shows that pyramidal feature atlases, rather than top-down/lateral connections, are the key to effective multi-scale detection. To see this, we look at a more aggressive simple pyramid case: we generate only the finest scale (1 4) feature map by deconvolution, then from this best map, we pool by strided average Subsampling the other scales in parallel. There are no unshared scaling parameters in this design. This very simple pyramid is almost as good: it has 54.5 AP (ViT-L), which is 3.3 higher than the baseline without the pyramid. This shows the importance of pyramid feature maps. For any variant of these feature pyramids, anchors (in the RPN) and regions (in the RoI header) are mapped to corresponding levels in the pyramid according to their scales, as shown in [35]. We hypothesize that this explicit scale-equivariant mapping, rather than top-down/lateral connections, is the main reason why feature pyramids can greatly benefit multi-scale object detection.
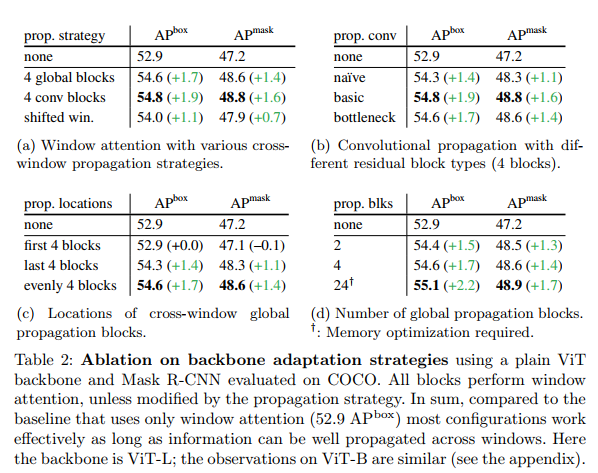
With the help of some propagation blocks, windowed attention is sufficient. Table 2 eliminates our backbone adaptation method. In short, above the baseline with pure window attention and no cross-window propagation blocks (Table 2, "None"), various propagation modalities can show decent gains.
In Table 2a, we compare our global and convolutional propagation strategies with the no-propagation baseline. They have gains of 1.7 and 1.9 over the baseline. We also compare with a “shifted window” (Swin [40]) strategy, where the window grid is shifted every other block by half the window size. The shifted window variant has a gain of 1.1 over the baseline, but worse than ours. Note that here we only focus on the "shifted window" aspect of Swin [40]: the backbone is still a vanilla ViT that only adapts shifted windowed attention during fine-tuning; it is not the Swin architecture, which we will compare later.
Table 2b compares different types of residual blocks used for convolution propagation. We study basic (two 3×3), bottleneck (1×1→3×3→1×1), and a primitive block with one 3×3 convolution. They are all improvements over the baseline, with specific block designs producing only minor differences. Interestingly, even though convolution is a local operation, if its receptive field covers two adjacent windows, it is in principle sufficient to connect all the pixels of the two windows. This connectivity is thanks to self-attention in both windows in subsequent blocks. This could explain why it can perform like a global spread.
In Table 2c, we investigate where the cross-window propagation should be located in the backbone. By default, an average of 4 global propagation blocks are placed. We put them in the first or last 4 blocks for comparison. Interestingly, performing the spread in the last 4 blocks is almost as good as placing evenly. This is consistent with the observation in [13] that ViT has a longer attention distance in later blocks and is more localized in earlier blocks. Conversely, performing propagation only in the first 4 blocks shows no gain: in this case, there is no propagation across the backbone window after these 4 blocks. This again shows that spreading across windows is helpful.
Table 2d compares the number of global propagation blocks to use. Even using only 2 blocks achieves good accuracy and significantly outperforms the baseline. For comprehensiveness, we also report a variant in which all 24 blocks in ViT-L use global attention. This is a marginal gain of 0.5 points over our 4-block default, while its training requires special memory optimizations (we use memory checkpointing [7]). This requirement makes scaling to larger models such as the ViT-H impractical. Our windowed attention solution plus some propagation blocks provides a practical, high-performance compromise.
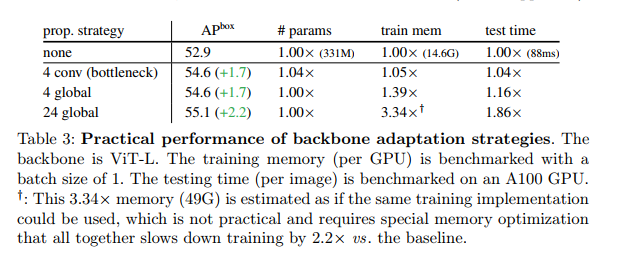
We benchmark this trade-off in Table 3. Using 4 propagation blocks makes a good trade-off. Convolutional propagation is the most practical, adding only ≤5% memory and time at the cost of 4% more parameters. Global propagation with 4 blocks is also feasible and does not increase the model size. Global self-attention for all 24 blocks is impractical.
In conclusion, Table 2 shows that various forms of propagation are helpful, while we can continue to use windowed attention in most or all blocks. Importantly, all these architectural tweaks are only performed during fine-tuning; they do not require redesigning the pretrained architecture.
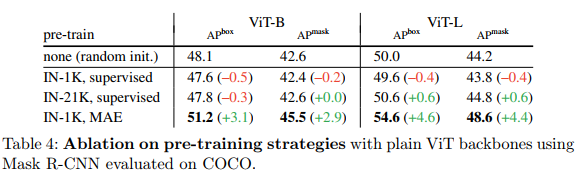
Masked Autoencoders provide a powerful pretrained backbone. Table 4 compares bone intervention training strategies. Supervised pretraining on IN-1K is slightly worse than no pretraining, similar to the observations in [18]. For ViT-L, the supervised pretraining of IN-21K is slightly better.
In contrast, MAE [23] pre-training on IN-1K (unlabeled) shows huge gains, with an APbox increase of 3.1 for ViT-B and 4.6 for ViT-L. We hypothesize that vanilla ViT [13] with less inductive bias may require higher capacity to learn translation and scaling equivariant features, and higher capacity models are prone to severe overfitting. MAE pretraining can help alleviate this problem. Next, we discuss more about MAE in context.
4.2 Comparison with Hierarchical Backbone
Modern detection systems involve many implementation details and subtleties. To focus on comparing backbones under conditions that are as fair as possible, we incorporate the Swin [40] and MViTv2 [32] backbones into our implementation.
settings . We use the same Mask R-CNN and Cascade Mask R-CNN [4] implementations for all ViT, Swin and MViTv2 backbones. We use FPN for the layered backbone of Swin/MViTv2. We search for the best hyperparameters for each backbone separately (see appendix). Our Swin results are better than their counterparts in the original paper; our MViTv2 results are better or comparable to those reported in [32].
Following the original papers [40, 32], both Swin and MViTv2 use relative positional bias [44]. For a fairer comparison, here we also adopt the relative position bias in the ViT backbone according to [32], but only during fine-tuning, without affecting pre-training. This addition increases AP by ~1 point. Note that our ablation in Section 4.1 has no relative positional bias.
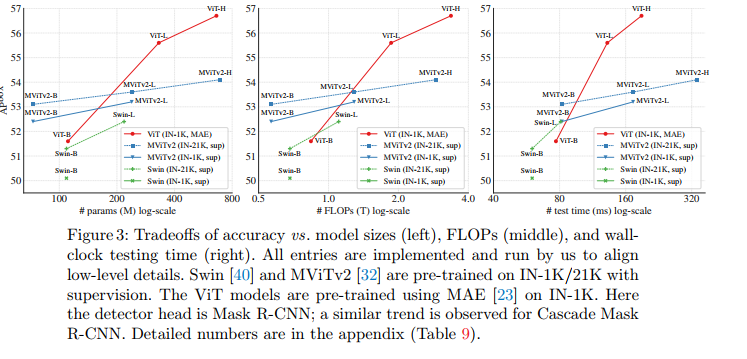
Results and Analysis . Table 5 shows the comparison. Figure 3 plots the tradeoffs. The comparison here involves two factors: the backbone and the pretraining strategy. Our vanilla backbone detector combined with MAE pre-training exhibits better scaling behavior. When the model is large, our method outperforms hierarchical models of Swin/MViTv2, including models pretrained with IN-21K supervision. Our results with ViT-H are 2.6 better than those with MViTv2-H. Also, plain ViT has better wall clock performance (Fig. 3 right, see ViT-H vs. MViTv2-H) because simpler blocks are more hardware friendly.
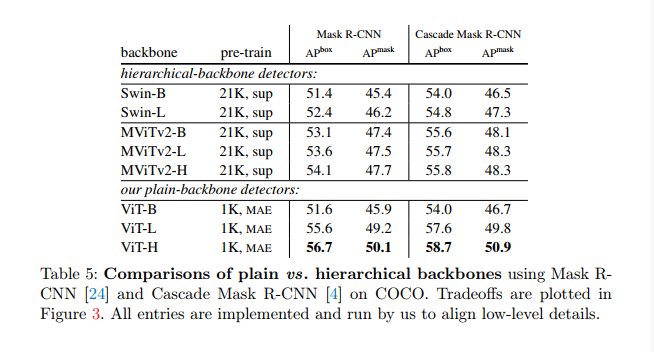
We also note that the hierarchical backbone usually involves an enhanced self-attention block design. Examples include shifted window attention in Swin [40] and focused attention in MViT v1/v2 [16,32]. Accuracy and parameter efficiency can also be improved if these block designs are applied to common backbone networks. While this may give our competitors an advantage, our approach is still competitive without these enhancements.
4.3 Comparison with previous systems
Next, we provide a system-level comparison with leading results reported in previous papers. We call our system ViTDet, or ViT Detector, and aim to use the ViT backbone for detection. Since these comparisons are system-level, these methods use a variety of different techniques. While we strive to balance comparisons (as described below), it is generally not feasible to conduct fully controllable comparisons; instead, we aim to place our method in the context of current leading methods.
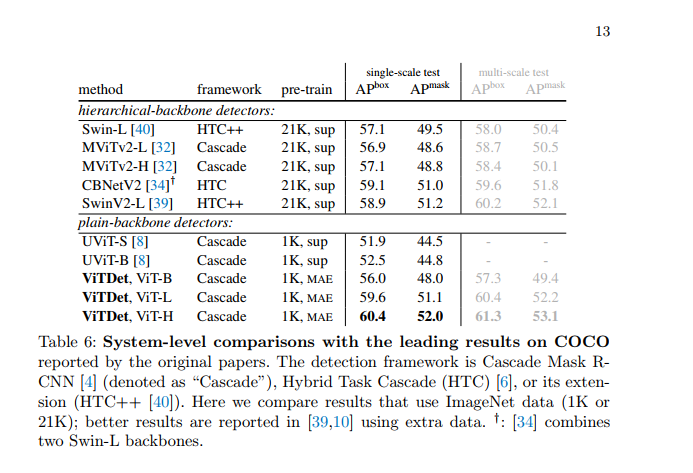
Comparison on COCO. Table 6 reports a system-level comparison of COCO. For a fairer comparison, we make two changes from our competitors: we take the soft-nms [3] used by all competitors [40, 32, 34, 39] in this table, and increase the input The size (from 1024 to 1280 ) comes after [34,39]. We note that we did not use these improvements in previous ablations. As in the previous subsection (Section 4.3), we use the relative positional deviation here.
To date, leading systems are based on hierarchical backbones (Table 6). We show for the first time that a common backbone detector can achieve highly accurate results on COCO and can compete with leading systems.
We also compare with the recent common backbone detection method UViT [8]. As discussed in Section 2, UViT and our work have different focuses. UViT aims to design a new general backbone that is conducive to detection, while our goal is to support general ViT backbones, including the original backbone in [13]. Despite the different focus, both UViT and our work show that plainbackbone detection is a promising direction with great potential.
Comparison on LVIS. We further report a system-level comparison on the LVIS dataset [22]. LVIS contains 2 million high-quality instance segmentation annotations for 1203 categories, exhibiting a natural long-tailed object distribution. Unlike COCO, the class distribution is severely imbalanced, with few training examples (eg, <10) for many classes.
We follow the same model and training details as the COCO system-level comparison and two common LVIS practices: we use a joint loss from [57] and sample images with repetition factor sampling [22]. We fine-tuned for 100 epochs on the v1 training split.
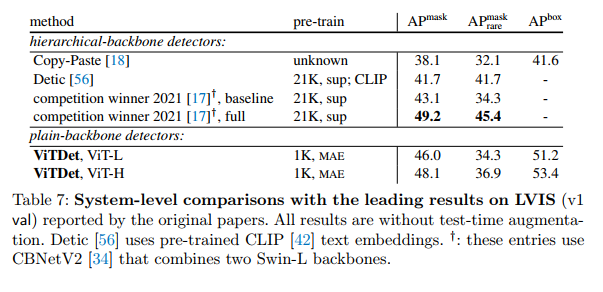
Table 7 shows the results of the v1 val split. Our plain backbone detector achieves competitive performance compared to all previous state-of-the-art results using hierarchical backbones. Ours is 5.0 points higher than the 2021 competition winner's "strong baseline" [17] (48.1 vs. 43.1 APmask), which uses HTC and CBNetV2 [34] that combines two Swin-L backbones. A particular problem with LVIS is about long-tailed distributions, which are beyond the scope of our study. Techniques specific to this problem, eg, using CLIP [42] text embeddings or other improvements in [17], can largely increase the AP for rare classes (APmask rare), thereby improving the overall AP. These are orthogonal to our method and can be complementary. Nonetheless, our results on LVIS again show that plainbackbone detectors can compete with hierarchical detectors.
5 Conclusion
Our exploration shows that plain-backbone detection is a promising research direction. This approach largely maintains the independence of the generic backbone and downstream task-specific designs - which is the case in ConvNet-based research but not Transformer-based research. We hope that separating pre-training from fine-tuning is an approach that generally benefits the community. For example, in natural language processing (NLP), general pre-training (GPT [43], BERT [12]) has greatly advanced the field and has been supporting various downstream tasks. In this study, our common backbone detector benefits from off-the-shelf pretrained models in MAE [23]. We hope this approach will also help bring the fields of computer vision and NLP closer together.