Click the card below to follow the " CVer " public account
AI/CV heavy dry goods, delivered as soon as possible
Reprinted from: Heart of the Machine
Recently, CVPR 2022, the top computer vision conference, announced the admission results of the conference, and the paper jointly published by Meitu Imaging Research Institute (MT Lab) and Beihang University Cola Lab (CoLab) was accepted. This paper groundbreakingly proposes a distributed-aware single-stage model for solving the challenging multi-person 3D human pose estimation problem. This method simultaneously obtains the human body position information and the corresponding key point information in the 3D space through a network forward reasoning, thereby simplifying the prediction process and improving the efficiency. Furthermore, the method effectively learns the true distribution of human keypoints, which in turn improves the accuracy of the regression-based framework.
Multi-person 3D human pose estimation is a hot research topic at present, and it also has wide application potential. In computer vision, the problem of multi-person 3D human pose estimation based on a single RGB image is usually solved by a top-down or bottom-up two-stage method. However, the two-stage method suffers from a lot of redundant computation and complex The low efficiency of the post-processing has been criticized. In addition, the existing methods lack the knowledge of the distribution of human pose data, and thus cannot accurately solve the ill-posed problem from 2D pictures to 3D positions. The above two points limit the application of existing methods in practical scenarios.
A paper published at CVPR 2022 by Meitu Imaging Research Institute (MT Lab) and Beihang University's Cola Lab (CoLab) proposes a distributed-aware single-stage model, and uses this model to estimate multiple levels from a single RGB image. Human pose of an individual in 3D camera space .
In this method, the 3D human body pose is represented as the 2.5D human body center point and the 3D key point offset to adapt to the depth estimation of the image space. At the same time, this representation unifies the human body position information and the corresponding key point information, so that Single-stage multi-person 3D pose estimation becomes possible.

Paper address: https://arxiv.org/abs/2203.07697
In addition, the method learns the distribution of human key points during the model optimization process, which provides important guidance information for the regression prediction of key point locations, thereby improving the accuracy of the regression-based framework. This distribution learning module can be learned together with the pose estimation module through maximum likelihood estimation during the training process, and the module is removed during the testing process without increasing the computational load of model inference. In order to reduce the difficulty of learning the distribution of human key points, this method innovatively proposes an iterative update strategy to gradually approach the target distribution .
The model is implemented in a fully convolutional fashion and can be trained and tested end-to-end. In such a way, the algorithm can effectively and accurately solve the multi-person 3D human pose estimation problem, while achieving the accuracy close to the two-stage method, but also greatly improving the speed .
background
Multi-person 3D human pose estimation is a classic problem in computer vision, which is widely used in AR/VR, games, motion analysis, virtual fitting, etc. In recent years, with the rise of the concept of the metaverse, this technology has attracted more attention. At present, a two-stage method is usually used to solve this problem: the top-down method , that is, the position of multiple human bodies in the picture is detected first, and then the single-person 3D pose estimation model is used for each detected person to predict its pose ; The upward method is to first detect the 3D key points of all people in the picture, and then assign these key points to the corresponding human body through correlation.
Although the two-stage method achieves good accuracy, it needs to sequentially acquire human body position information and key point position information through redundant computation and complex post-processing, which makes the rate usually difficult to meet the deployment requirements of actual scenarios, so many The algorithm process of human 3D pose estimation needs to be simplified.
On the other hand, estimating 3D keypoint locations, especially depth information, from a single RGB image in the absence of prior knowledge of the data distribution is an ill-conditioned problem. This makes the traditional single-stage model applied to 2D scenes cannot be directly extended to 3D scenes. Therefore, learning and obtaining the data distribution of 3D key points is the key to high-precision multi-person 3D human pose estimation .
In order to overcome the above problems, this paper proposes a distribution-aware single-stage model (DAS) to solve the ill-posed problem of multi-person 3D human pose estimation based on a single image. The DAS model represents the 3D human pose as the 2.5D human center point and the 3D human key point offset, which effectively adapts the depth information prediction based on the RGB image domain. At the same time, it also unifies the human body position information and key point position information, which makes it possible to estimate the single-stage multi-person 3D pose based on monocular images.
In addition, the DAS model learns the distribution of 3D key points during the optimization process, which provides valuable guidance information for the regression of 3D key points, thereby effectively improving the prediction accuracy. In addition, in order to alleviate the difficulty of estimating the distribution of key points, the DAS model adopts an iterative update strategy to gradually approach the real distribution target. In this way, the DAS model can efficiently and accurately obtain multiple data from monocular RGB images at one time. Individual 3D human pose estimation results.
A single-stage multi-person 3D pose estimation model
In terms of implementation, the DAS model is constructed based on the regression prediction framework. For a given image, the DAS model outputs the 3D human pose of the person contained in the image through a forward prediction. The DAS model represents the center point of the human body as the center point confidence map and the center point coordinate map, as shown in Figure 1 (a) and (b),
Among them, the DAS model uses the center point confidence map to locate the position of the human body projection center point in the 2D image coordinate system, and uses the center point coordinate map to predict the absolute position of the human body center point in the 3D camera coordinate system. The DAS model models human body keypoints as keypoint offset maps, as shown in Figure 1(c).
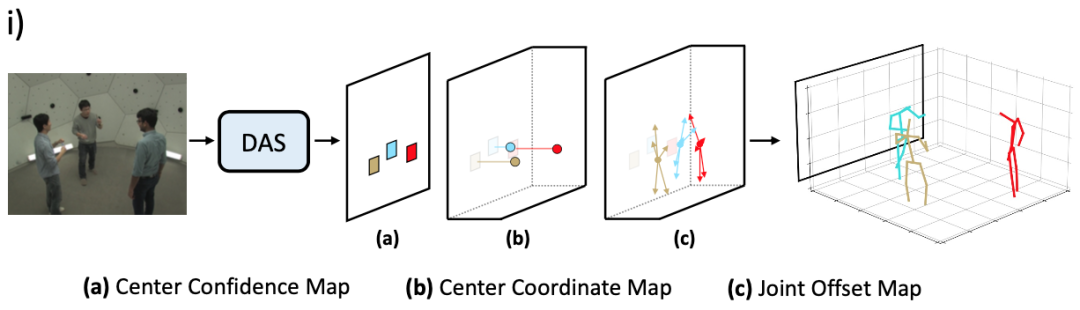
Figure 1: Flowchart of a distributed-aware single-stage model for multi-person 3D human pose estimation.
The DAS model models the confidence map of the center point as a binary map, and each pixel in the map indicates whether the center point of the human body appears at that position, if it does, it is 1, otherwise it is 0. The DAS model models the center point coordinate map as a dense map, where each pixel in the map encodes the x, y, and z coordinates of the center of the character appearing at that location. The keypoint offset map is modeled in a similar way to the center point coordinate map. Each pixel in the map encodes the offset of the human body keypoint at that position relative to the human body center point in the x, y, and z directions. The DAS model can output the above three information graphs in parallel in the network forward process, thus avoiding redundant computation.
In addition, the DAS model can easily reconstruct the 3D poses of multiple people using these three information maps, and also avoids complex post-processing procedures. Compared with the two-stage method, such a compact and simple one-stage model can achieve more excellent efficiency .
Distribution-aware learning model
For the optimization of the regression prediction framework, the existing work mostly uses the traditional L1 or L2 loss function, but the research found that this type of supervised training is actually based on the assumption that the data distribution of the key points of the human body satisfies the Laplace distribution or the Gaussian distribution. performed model optimization [12]. However, in actual scenarios, the real distribution of human key points is extremely complex, and the above simple assumptions are far from the real distribution.
Different from existing methods, the DAS model learns the true distribution of 3D human body keypoint distribution during the optimization process, guiding the process of keypoint regression prediction . Considering the problem that the real distribution is not traceable, the DAS model uses Normalizing Flow to achieve the goal of probability estimation of the model prediction results to generate a distribution suitable for the model output, as shown in Figure 2.
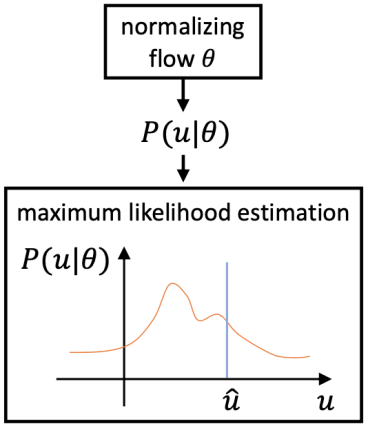
Figure 2: Normalized flow.
The distribution-aware module can be learned together with the key point prediction module through the maximum likelihood estimation method in the training process. After the learning is completed, the distribution-aware module will be removed in the prediction process. Such a distribution-aware algorithm can Improve the accuracy of regression prediction models without adding extra computation.
In addition, the feature used for human body key point prediction is extracted at the center point of the human body. This feature has a weak representation ability for human key points far away from the center point, and the spatial inconsistency of the target will cause a large error in prediction. . To alleviate this problem, the algorithm proposes an iterative update strategy, which uses the historical update results as a starting point and integrates the predicted values near the intermediate results to gradually approach the final goal, as shown in Figure 3.
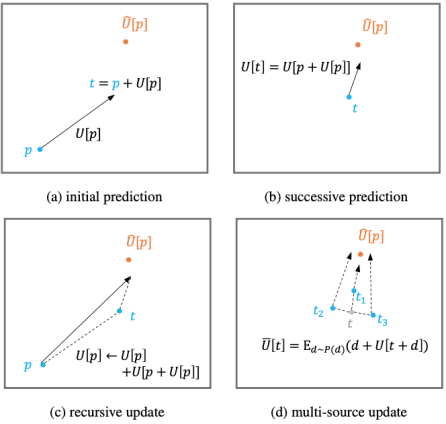
Figure 3: Iterative optimization strategy.
The algorithm model is implemented by Fully Convolutional Networks (FCNs), and both training and testing processes can be performed in an end-to-end manner, as shown in Figure 4.
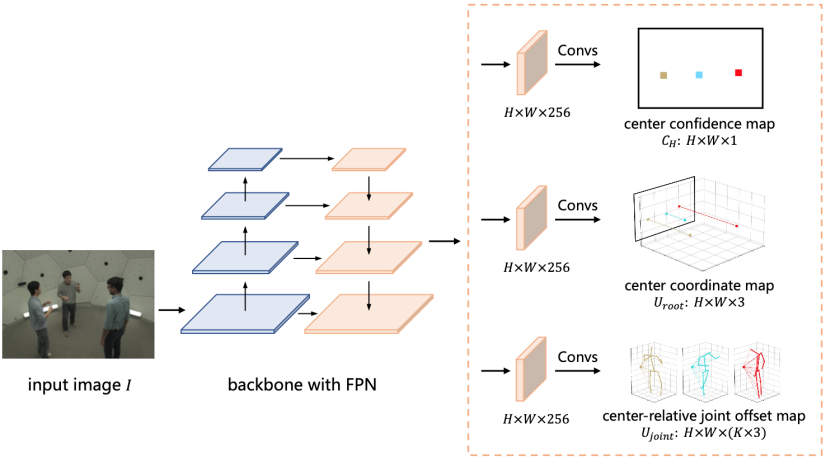
Figure 4: Distributed-aware single-stage multi-person 3D human pose estimation network structure.
According to the experimental results, as shown in Figure 5, compared with the existing state-of-the-art two-stage method, the single-stage algorithm can achieve close to or even better accuracy, and can greatly improve the speed, which proves that it can solve many problems. Superiority in the problem of human 3D human pose estimation.
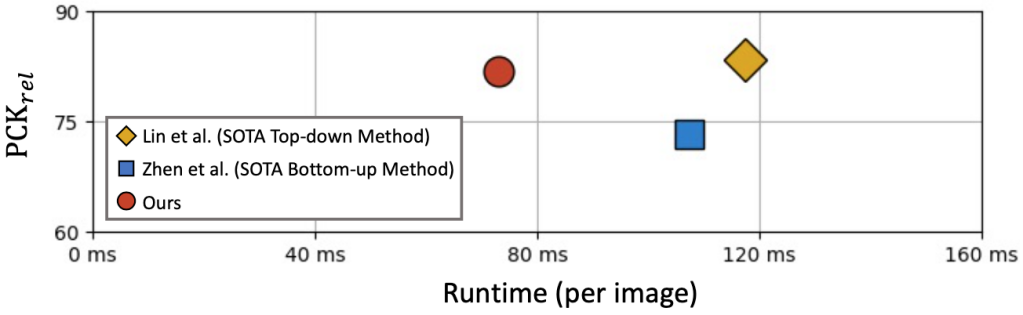
Figure 5: Comparison results with the existing SOTA two-stage algorithm.
Detailed experimental results can be found in Tables 1 and 2.
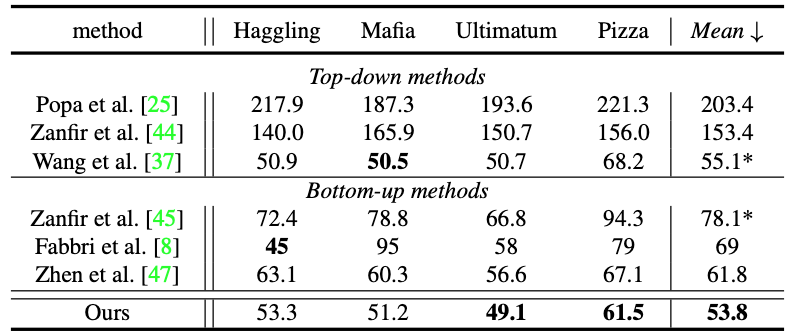
Table 1: Comparison of CMU Panoptic Studio dataset results.
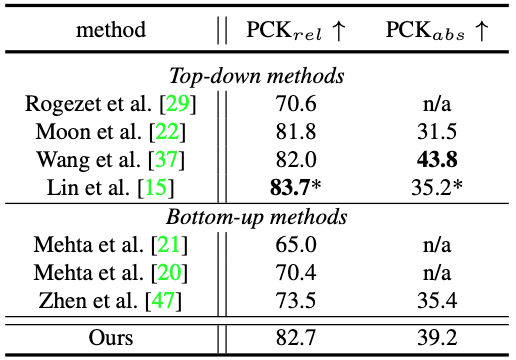
Table 2: Comparison of MuPoTS-3D dataset results.
According to the visualization results of the single-stage algorithm, as shown in Figure 6, the algorithm can adapt to different scenarios, such as pose changes, human body truncation, and cluttered backgrounds, to produce accurate prediction results, which further illustrates the robustness of the algorithm.
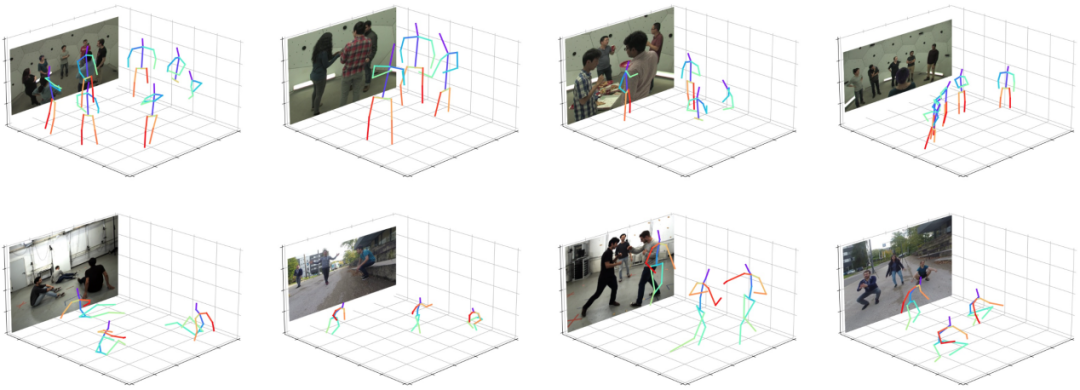
Figure 6: Visualization of results.
Summarize
In this paper, researchers from Meitu and Beihang University innovatively propose a distributed-aware single-stage model to solve the challenging multi-person 3D human pose estimation problem. Compared with the existing top-down and bottom-up two-stage models, this model can simultaneously obtain the human body position information and the corresponding human body key point position information through one network forward reasoning, thereby effectively simplifying the prediction process. , while overcoming the disadvantages of existing methods in terms of high computational cost and high model complexity.
In addition, the method successfully introduces the standardized flow into the multi-person 3D human pose estimation task to learn the distribution of human key points during the training process, and proposes an iterative regression strategy to ease the difficulty of distribution learning to gradually approach the goal. In this way, the algorithm can obtain the true distribution of the data to effectively improve the regression prediction accuracy of the model.
research team
This paper is jointly proposed by researchers from Meitu Imaging Research Institute (MT Lab) and Beijing University of Aeronautics and Astronautics (CoLab). Meitu Imaging Research Institute (MT Lab) is Meitu's team dedicated to algorithm research, engineering development and productization in computer vision, machine learning, augmented reality, cloud computing and other fields. It provides core algorithm support and promotes the development of Meitu products through cutting-edge technologies. It is known as the "Meitu Technology Center". It has participated in top international computer vision conferences such as CVPR, ICCV, and ECCV for many times, and has won more than ten first and second prizes.
Citation:
[1] JP Agnelli, M Cadeiras, Esteban G Tabak, Cristina Vilma Turner, and Eric Vanden-Eijnden. Clustering and classifica- tion through normalizing flows in feature space. Multiscale Modeling & Simulation, 2010.
[12] Jiefeng Li, Siyuan Bian, Ailing Zeng, Can Wang, Bo Pang, Wentao Liu, and Cewu Lu. Human pose regression with residual log-likelihood estimation. In ICCV, 2021.
[15] Jiahao Lin and Gim Hee Lee. Hdnet: Human depth estima- tion for multi-person camera-space localization. In ECCV, 2020.
[47] Jianan Zhen, Qi Fang, Jiaming Sun, Wentao Liu, Wei Jiang, Hujun Bao, and Xiaowei Zhou. Smap: Single-shot multi-person absolute 3d pose estimation. In ECCV, 2020.
[48] Xingyi Zhou, Dequan Wang, and Philipp Kra ̈henbu ̈hl. Ob- jects as points. arXiv preprint arXiv:1904.07850, 2019.
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-人体姿态估计交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-人体姿态估计 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如人体姿态估计+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看