记录spark unionAll的报错:Union can only be performed on tables with the compatible column types
Traceback (most recent call last):
File "/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 63, in deco
File "/opt/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o348.union.
: org.apache.spark.sql.AnalysisException: Union can only be performed on tables with the compatible column types. string <> array<string> at the 6th column of the second table;;
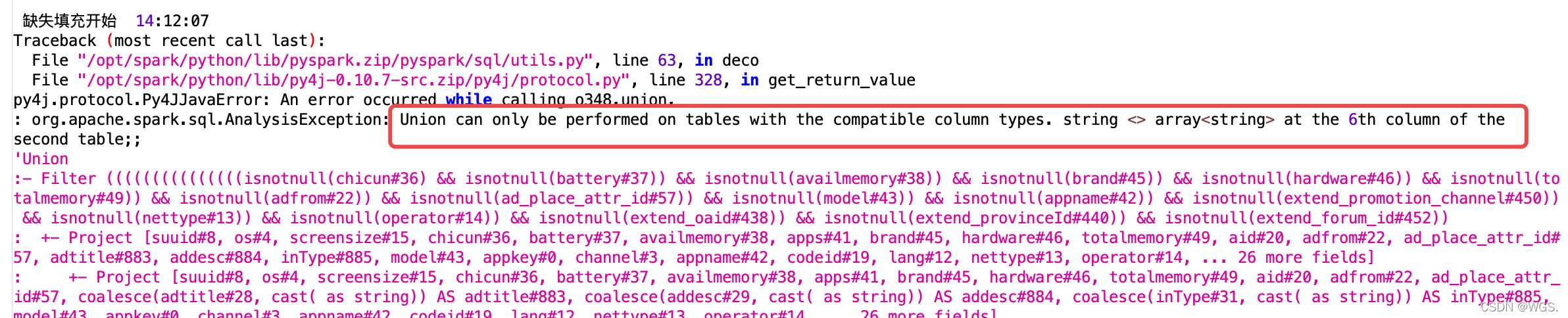
Union can only be performed on tables with compatible column types.
Say I have a column with index 6, the string type and the array type are inconsistent, that is, the columns of the two tables of the union are inconsistent
spark union note:
-
The union operation is not equivalent to the union of sets, it does not deduplicate data.
-
The union function does not merge by column name, butBy locationmerge. That is, the column names of the DataFrame can be different, but the columns in the corresponding positions will be merged together.
Spark's default behavior, union, is standard SQL behavior, and thus is matched by position. This means that the schemas in both DataFrames must contain the same fields, and the same fields have the same order.
Error code location:
df = dfnotna.unionAll(dfna)
Set as problem:
print(dfnotna.columns)
print(dfna.columns)
['suuid', 'os', 'screensize', 'chicun', 'battery', 'availmemory', 'apps', 'brand', 'hardware', 'totalmemory', 'aid', 'adfrom', 'ad_place_attr_id', 'adtitle', 'addesc', 'inType', 'model', 'appkey', 'channel', 'appname', 'codeid', 'lang', 'nettype', 'operator', 'time', 'country', 'city', 'province', 'extend', 'actname', 'extend_suuid', 'extend_oaid', 'extend_aid', 'extend_provinceId', 'extend_adveruserid', 'extend_payment', 'extend_information', 'extend_w', 'extend_h', 'extend_cost', 'extend_personal_ads_type', 'position', 'extend_productId', 'extend_promotion_channel', 'extend_slotBinding', 'extend_forum_id', 'extend_forum_duration', 'extend_open_type', 'extend_app_back_run_time', 'newid']
['newid', 'suuid', 'os', 'screensize', 'chicun', 'battery', 'availmemory', 'apps', 'brand', 'hardware', 'totalmemory', 'aid', 'adfrom', 'ad_place_attr_id', 'adtitle', 'addesc', 'inType', 'model', 'appkey', 'channel', 'appname', 'codeid', 'lang', 'nettype', 'operator', 'time', 'country', 'city', 'province', 'extend', 'actname', 'extend_suuid', 'extend_oaid', 'extend_aid', 'extend_provinceId', 'extend_adveruserid', 'extend_payment', 'extend_information', 'extend_w', 'extend_h', 'extend_cost', 'extend_personal_ads_type', 'position', 'extend_productId', 'extend_promotion_channel', 'extend_slotBinding', 'extend_forum_id', 'extend_forum_duration', 'extend_open_type', 'extend_app_back_run_time']
Solution: The order of the merged columns should be consistent
df = dfnotna.select(*dfna.columns).unionAll(dfna)