
Guided reading
Brother Jim joined VMware China in 2007 and has experienced the booming development of the entire enterprise market from server virtualization, private cloud, public cloud, container cloud, hybrid cloud to cloud native. An extension of the software-defined-everything concept. In 2021, Brother Jim will join Trends Technology and join the wave of software-defined AI computing power. This article does not intend to talk about concepts and logic, but tries to use five actual customer scenarios to see how to optimize AI computing power and solve pain points through software-defined methods for the reference of all bosses.
GPU servers are very expensive compared to CPU servers, about the difference between the exchange rate of US dollars and RMB (take an 8-card GPU server as an example), and in the era of chip shortage, the GPU delivery cycle is still relatively long! Faced with the contradiction between expensive resources, computing power is the engine of AI, and AI business must be carried out, how to better utilize and manage GPU resources becomes particularly critical. Let's take a look at these five typical scenarios .
◆ ◆ ◆ ◆
Scenario 1: AI development and testing
◆ ◆ ◆ ◆
Most customers take the way of allocating one or several GPU cards to a developer to meet the needs of development and debugging. What is the problem in this case? Cards are bound to people. After the cards are allocated, there is a lot of idle time. Developers spend more than 70% of their time reading papers and writing codes, and less than 30% of their time using GPU resources for computing and debugging. Using the software-defined GPU technology, the card is unbound from the human . When a task calls GPU resources, it is really occupied. After the task ends, the resources are released and returned to the resource pool.
The following figure is a development scenario of JupyterLab. The mode of VSCode server/PyCharm is similar to this. In the actual customer case, after using the software-defined GPU, the resources can be reduced to about 25% ! 50 people's development team, 16 cards to get .
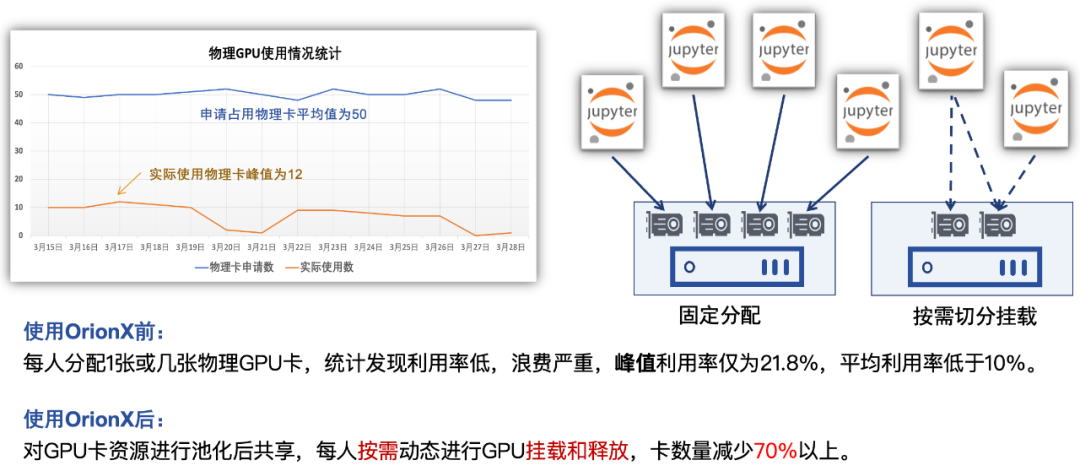
Figure 1: An example of OrionX dynamically calling card resources in AI development
◆ ◆ ◆ ◆
Scenario 2: AI inference business in production environment
◆ ◆ ◆ ◆
According to the survey, the vast majority of user services run on independent GPU cards in order to ensure the isolation of services, not be interfered by other AI services, and ensure service SLAs . In this case, the computing power and video memory usage of GPU cards are often less than 20%, which results in a lot of waste of resources - nearly 80% of computing power and video memory are actually wasted in vain , and there are also related Electricity, operation and maintenance costs. In a software-defined way, it provides fine-grained GPU resource multiplexing on a single card to ensure the isolation, reliability and performance of business operations. Most of the customers who adopt the pooled solution of Trends Technology to launch production business can get more than 3 times the increase in revenue .
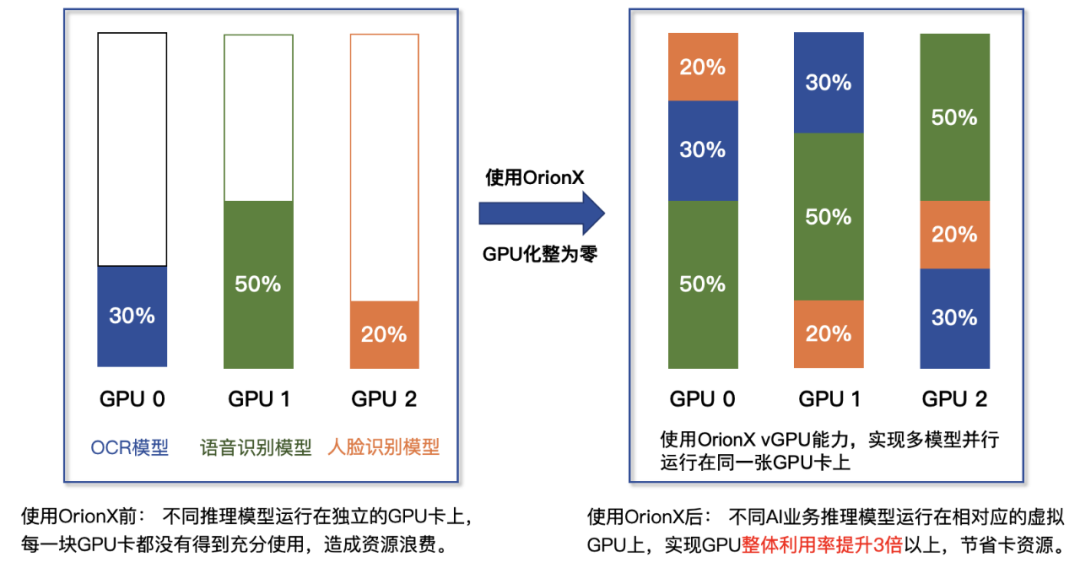
Figure 2: Single-card multi-service multiplexing example of OrionX in production environment
◆ ◆ ◆ ◆
Scenario 3: Day and Night Multiplexing
◆ ◆ ◆ ◆
In the first two scenarios, whether it is AI development or AI online reasoning, it is basically busy during the day, and the card utilization rate is relatively high. At night , the card resources are basically in an idle state, wasted in vain! At a securities client, we tried to solve this problem with OrionX. Through the software-defined method, resources are allocated and scheduled flexibly, and card resources are used to perform training tasks at night, which greatly improves the utilization of idle time (nighttime) resources.
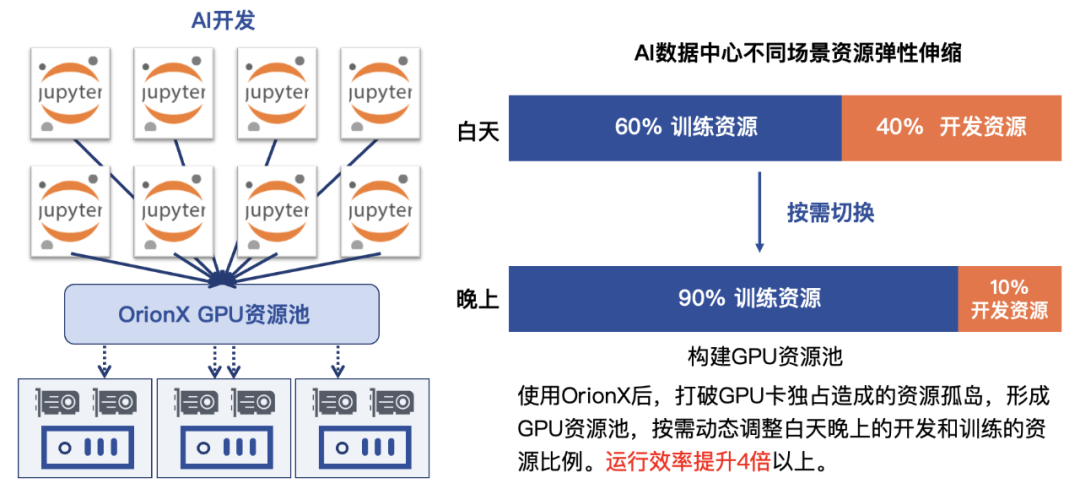
Figure 3: Example of day and night multiplexing of cards on demand by OrionX
◆ ◆ ◆ ◆
Scenario 4: The resource ratio of CPU and GPU
◆ ◆ ◆ ◆
Most AI development involves data preparation, preprocessing, model training, parameter tuning, model deployment, online reasoning, continuous monitoring, data collection, and iterative optimization. In the entire business process, some tasks require a lot of CPU and do not require GPU resources. When the CPU is operating, the GPU is actually idle; in an autonomous driving customer, we saw that in the simulation scenario, an 8-card In a GPU server, when the CPU is exhausted (occupying 100%), only 3 GPU cards can be used at most , and the remaining 5 GPU cards are idle and cannot be fully utilized. For the same reason, there may also be a situation where the GPU card is heavily occupied and the CPU resources are idle. By utilizing software-defined AI computing power, the CPU and GPU are decoupled to solve the problem of CPU/GPU resource mismatch .
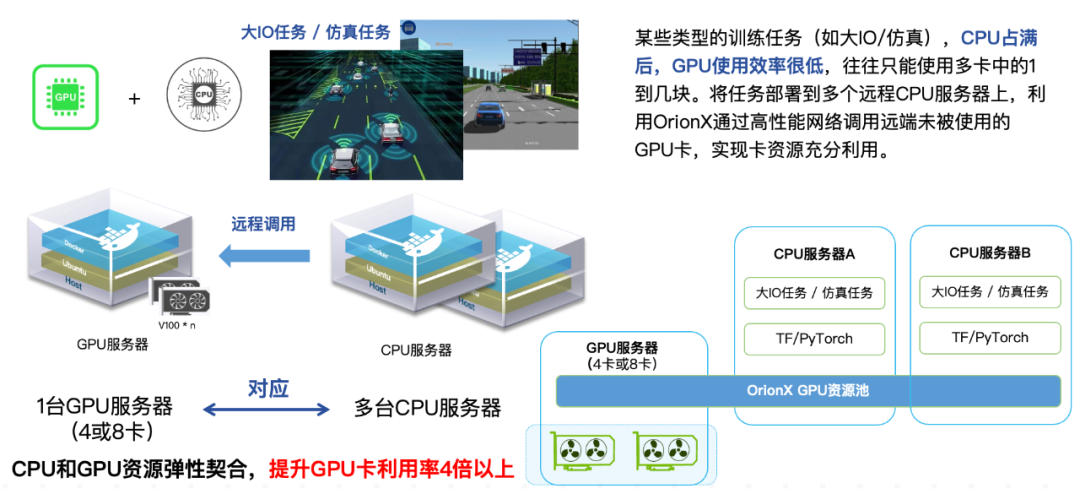
Figure 4: OrionX optimized CPU and GPU resource allocation example
◆ ◆ ◆ ◆
Scenario 5: Video memory overscore
◆ ◆ ◆ ◆
This is a real case we encountered with a financial customer. We saw a big data AI analysis process running on a T4 card with 16G video memory, which requires about 20% of the computing power, 12Gb video memory, service Resident is used to process identification and analysis of insurance policies. In this case, the remaining 80% of the card's computing power and 4Gb (25%) of video memory are idle and cannot be used, becoming resource fragments .
To use resource fragments, one idea is to find the computing power task suitable for the fragments and also run on this card (not necessarily easy to find). Using software-defined virtual memory technology, use part of the memory to supplement the video memory , allowing two tasks to run on this card at the same time. The resources remain unchanged, and the flux reaches 1.8 times!
You may also think that if the physical memory required by the model is not enough when running a training task, can the memory be used to supplement the loading? Yes. You can load and run, but you have to pay a certain performance loss. In addition to having to change the model or purchase a physical card with large video memory, this solution provides another possible choice.

Figure 5: Example of OrionX memory over-score improving resource utilization
The above five scenarios of using the software-defined GPU method to optimize AI computing power are just the tip of the iceberg we have seen. The business value that software-defined GPUs can bring remains to be explored by enterprise customers in various fields.
In addition, I have to mention the additional Bonus of this technology to reduce carbon emissions and protect the earth's homeland !
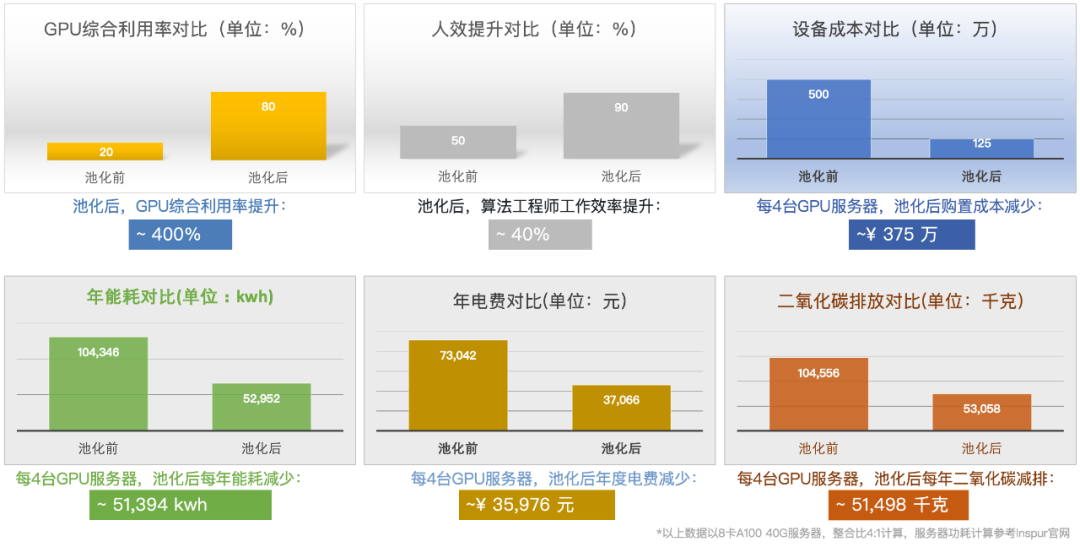
Figure 6: OrionX KPI benefit comparison example
Finally, a summary. The core of software-defined is to turn various hardware (CPU, memory, disk, I/0, etc.) into a "resource pool" that can be dynamically managed through a software-defined method , thereby improving resource utilization, simplifying system management, and realizing Resource integration makes IT more adaptable to business changes.
Software-defined AI computing power, on the one hand, can turn a physical acceleration chip (GPU or ASIC) into several or dozens of small computing units that are isolated from each other , and can also aggregate acceleration chips distributed on different physical servers. Give an operating system (physical machine/virtual machine) or container to complete distributed tasks. In addition, a CPU server without an acceleration chip (GPU or ASIC) can also call an acceleration card (GPU or ASIC) on a remote server to complete AI operations, realizing the decoupling of the CPU and GPU devices. The essence of software-defined is to provide more resilient hardware by means of software .