redis中持久化有两种,一种是RDB持久化,另一种是AOF持久化,如果同时开启的话,会先进行AOF持久化,默认情况下redis.conf配置中AOF持久化是关闭的。下面具体聊一下这两种持久化方式。
为什么需要持久化
因为对redis的数据操作都是在内存中的,因此如果redis宕机或者重启后,没有持久化机制,就无法恢复原先数据,持久化的作用就是为了保存数据,更快的做数据恢复,提高系统的可用性。
RDB持久化
RDB持久化的目的:将Redis在内存中的数据库状态保存在磁盘上,避免数据丢失。
RDB既可以手动执行,也可以根据服务器配置选项定期执行。
RDB文件是一个经过压缩的二进制文件,通过文件可以还原数据库状态。
通过执行save/bgsave命令生成rdb文件。
那这两个命令有什么区别吗?
- save会阻塞redis服务器进程,直到RDB文件创建完成为止,在服务器进程阻塞期间,服务器不能处理任何命令请求。
- bgsave会fork出一个子进程,由子进程创建RDB文件,父进程继续处理客户端命令。
pid=fork()
if pid==0: //子进程创建rdb文件
rdbSave()
signal_parent() //创建rdb文件完成后向父进程发送信号
elif pid>0:
handle_request_and_wait_signal() //父进程继续处理客户端命令请求,通过轮询等待子进程的消息
else:
handle_fork_error()
载入RDB文件没有专门的命令,只要redis服务器在启动时检测到RDB文件存在,就会自动载入。载入期间,服务器一直处于阻塞状态,知道载入完成。
服务器在处理SAVE,BGSAVE,BGREWRITEAOF命令会有所不同
- 在BGSAVE命令执行期间,SAVE会被拒绝执行,这是为了避免父子进程同时调用rdbSave()方法,防止竞争条件
- BGSAVE执行期间,客户端发送的BGSAVE也会被拒绝执行。
- BGSAVE执行期间,客户端发送的BGREWRITEAOF会在它执行完之后再执行;如果BGREWRITEAOF正在执行,那么客户端发送的BGSAVE命令将会被拒绝执行。因为这两个命令实际工作都是由子进程执行,所以这两个命令在操作方面并没有冲突的地方,不能同时执行时因为两个并发执行写磁盘会严重影响性能。
RDB配置
save 90 1 # 表示90秒内至少执行过1次修改,就会触发RDB写磁盘 其他配置同理
save 300 10
save 60 1000
怎样检查保存条件是否已满足才去执行BGSAVE?
答:服务器周期性曹组函数ServerCron默认每个100ms就会执行一次,该函数用于对正在运行的服务器进行维护,其中一项工作就是检查save所设置的保存条件是否满足,如果满足才会去执行持久化。
使用od -c dump.rdb /od -cx dump.rdb命令可以打印rdb文件,-c参数是以ASCII编码打印,-x是以16进制打印文件
rdb文件结构
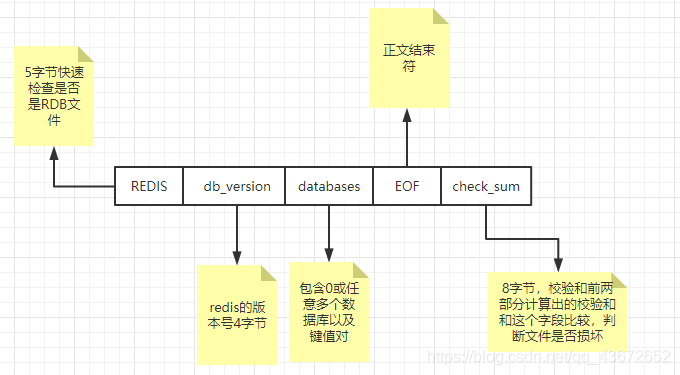
AOF持久化
AOF持久化:将redis服务器的写命令保存到磁盘,以此记录数据库的状态。
被写入的命令是以Redis请求协议格式保存的存文本格式。
AOF持久化的实现分为命令追加,文件写入,文件同步。
当AOD持久化功能开启的时候,服务器执行一个写命令之后就会以协议格式将这条写命令追加到服务器转改的aof_buf缓冲区的末尾。
具体执行什么时候执行还是由ServerCron监听,他来处理定时任务。
因为Redis服务器进程本身就是一个事件循环,循环处理文件事件和时间事件。文件事件时接收并处理客户端的命令请求,时间事件时负责执行ServerCron定时任务。
flushAppendOnlyFile函数决定是否将aof_buf缓冲区的命令写入到AOF文件中,他的行为通过配置文件中的appendfsync选项设置。
- always:将缓冲区的所有内容写入并同步到AOF文件
- everysec:如果距上次同步时间到现在超过1s,就对AOF进行同步
- no:只负责将缓冲区的写命令写入,不负责同步,何时同步由操作系统决定。
如果服务器宕机,会出现安全性问题
no: 丢失所有数据 持久化效率高
everysec:丢失前1s的数据,持久化效率高
always:丢失一个事件循环命令,持久化效率低
使用AOF文件还原数据库状态的过程
- 服务器启动载入程序
- 创建伪客户端
- 从AOF文件分析并读取一条写命令
- 伪客户端执行写命令
- 是否执行完所有写命令:否->继续执行,是->载入完毕
AOF重写
文件重写的目的:为了解决AOF文件体积膨胀的问题,Redis提供了AOF重写功能,将一个新的AOF文件不包含荣誉命令,替代旧的大文件。
实现原理
首先从数据库读出现在的键值,然后用一条命令去记录键值对,代替之前多条命令记录。
注意:为了避免在重写过程中造成客户端输入缓冲区溢出,重写程序需要处理集合,有序集合,哈希,列表键等,先检查所包含的元素数量是否超过redis.h/REDIS_AOF_REWRITE_TIMES_PER_CMD常量的值,如果超过限制,需要多条添加元素的命令。
由于AOF是单线程,重写也是单独一个线程调用重写函数,执行时间较长,可能导致服务器阻塞无法处理客户端的请求,因此redis将AOF重写程序放到子进程中执行,在子进程进行重写期间,服务器进程还可以继续处理客户端发来的命令请求,子进程带有进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性。
问题:
但是因为子进程在进行重写期间,服务器还需要继续处理命令请求,而新的命令可能会对现有的数据库状态进行修改,从而造成数据库状态和重写后的AOF文件中记录的状态不一致。
解决方法:
使用一个AOF重写缓冲区,AOF重写缓冲区在子进程创建之后开始使用,当Redis服务器执行完一个写命令后,会同时将写命令放入AOF缓冲区(aof_buf)和AOF重写缓冲区,当子进程完成AOF重写之后,会向父进程发一个信号,告诉他我已经重写完了,父进程收到这个信号之后,会调用一个信号处理函数,让AOF重写缓冲区中的数据全部写入到新的AOF文件中,对新文件重命名,原子地覆盖旧的文件。
参考:《Redis设计与实现 黄建宏》