相比于C#,java爬虫,python爬虫更为方便简要,首先呢,python的urllib2包提供了较为完整的访问网页文档的API,再者呢对于摘下来的文章,python的beautifulsoap提供了简洁的文档处理功能,这就成就了他爬虫的优势。
那么今天呢就来给大家分享一个我喜欢但是不好用的java爬虫系列。
一:引入依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.11</version>
</dependency>
二:入门级别的demo,四步即可
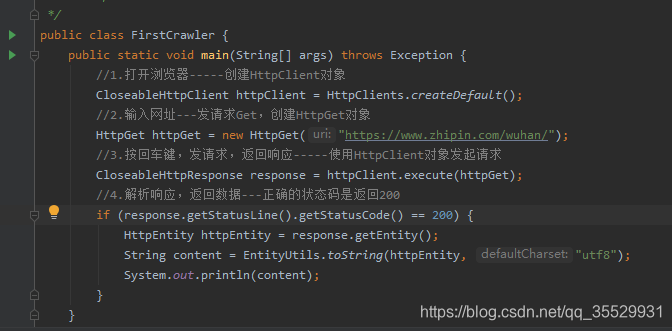
1)创建HttpClient对象:
CloseableHttpClient httpClient = HttpClients.createDefault();
2)发请求Get,创建HttpGet对象
HttpGet httpGet = new HttpGet("https://www.zhipin.com/wuhan/");
3)使用HttpClient对象发起请求
CloseableHttpResponse response = httpClient.execute(httpGet);
4)解析响应,返回数据—正确的状态码是返回200
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity, "utf8");
System.out.println(content);
}
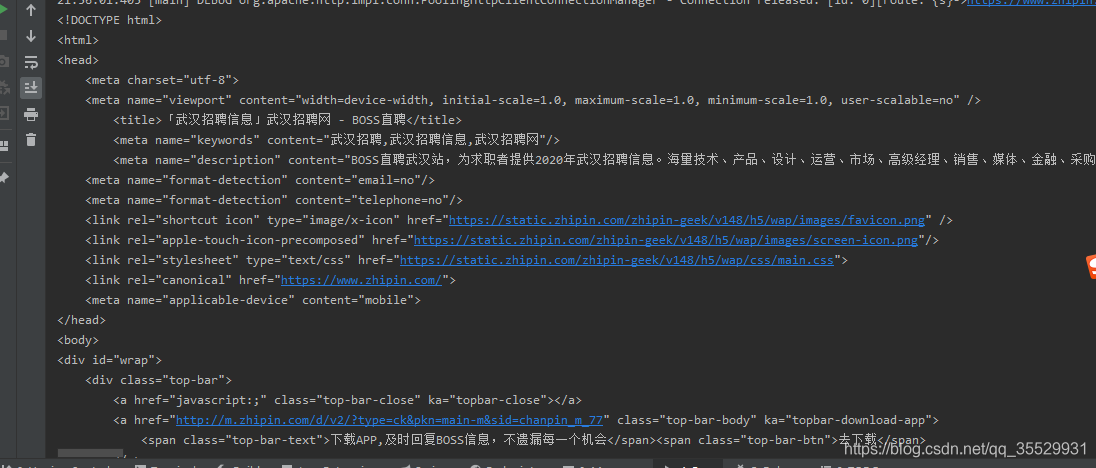
三:如下图所示,可以看到静态页面的内容被爬下来了。