Qpython最基础应用,不需要导入任何模块,这里找了一个科学运算的简单例子。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
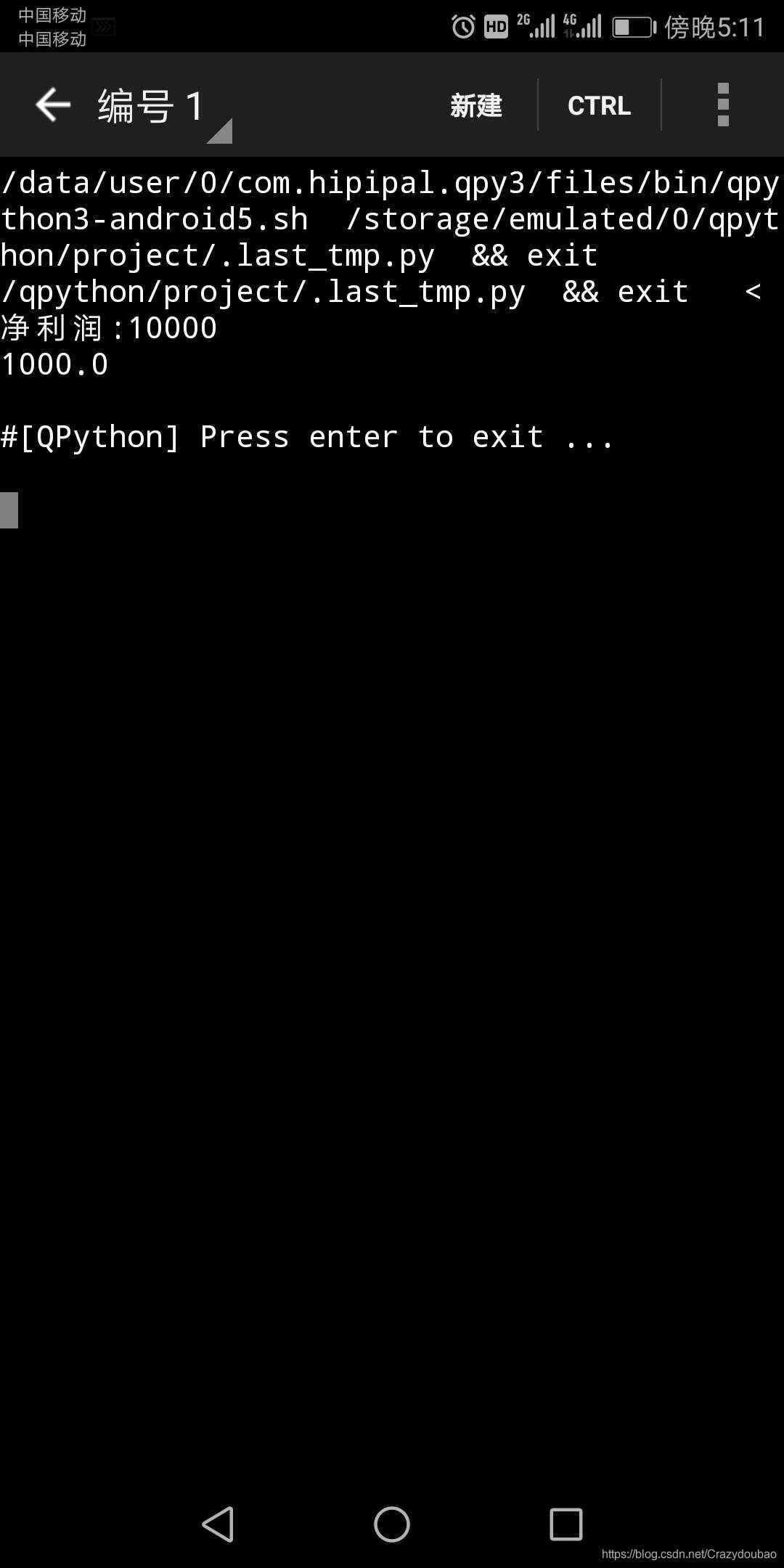
i = int(input('净利润:'))
arr = [1000000,600000,400000,200000,100000,0]
rat = [0.01,0.015,0.03,0.05,0.075,0.1]
r = 0
for idx in range(0,6):
if i>arr[idx]:
r+=(i-arr[idx])*rat[idx]
i=arr[idx]
print (r)
执行结果如下:
第二,Qpython也可以用来做复杂运算,可以用来计算圆周率π的值,采用的是蒙特卡洛法,大家可以自行了解一下原理。
import time
import random
hits=0
pi=0
DARTS=1000*1000
start=time.perf_counter()
for i in range(DARTS):
x,y=random.random(),random.random()
dist=pow(x ** 2+y**2,0.5)
if dist <= 1.0:
hits+=1
pi=4*(hits/DARTS)
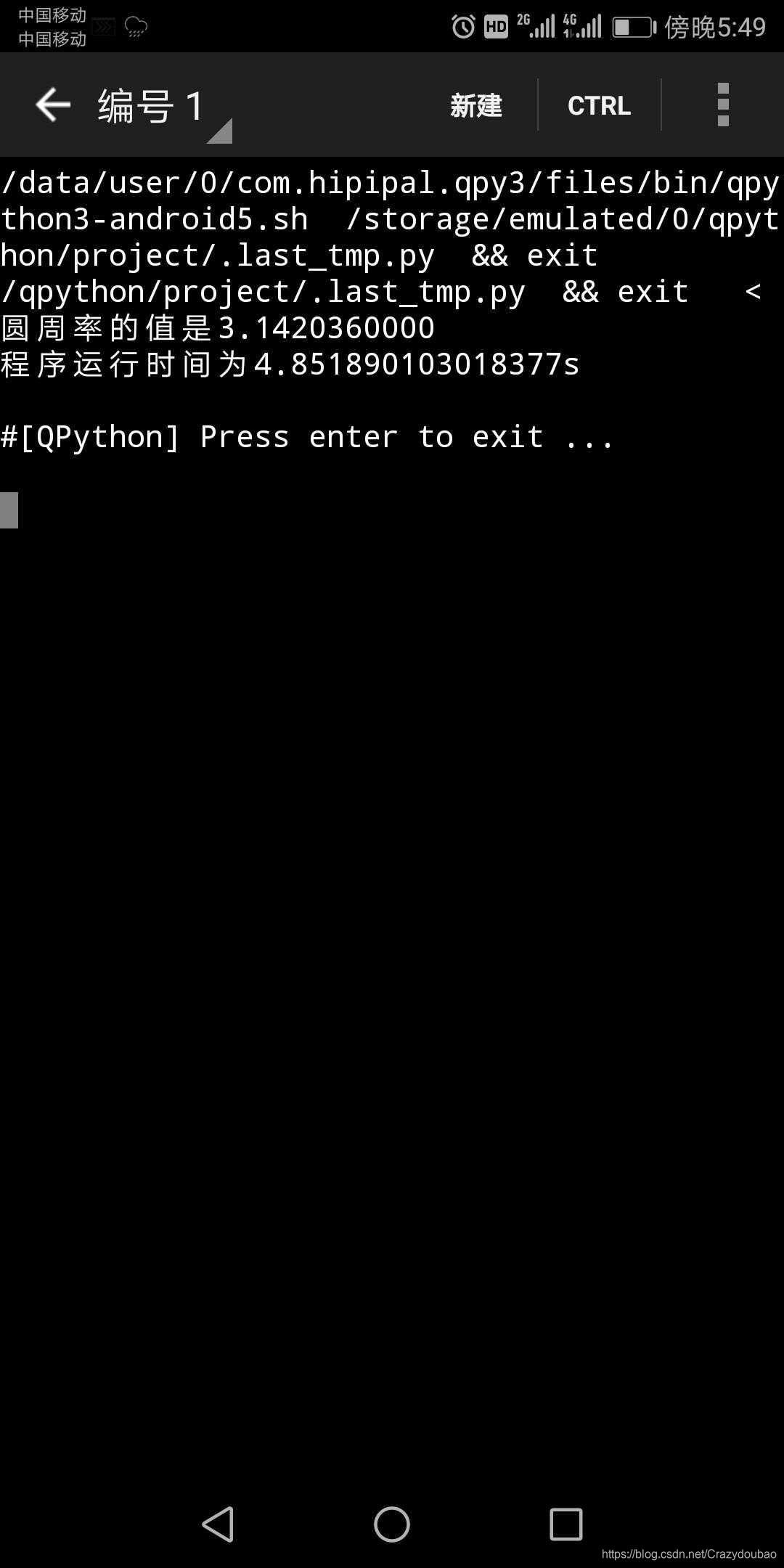
print("圆周率的值是{:.10f}".format(pi))
print("程序运行时间为{}s".format(time.perf_counter()-start))
DARTS赋值1000*1000,只是为了减少运行时间,当然赋值越多,计算越精确,时间也越多,据说Google已经计算到36亿位,各位小伙伴不嫌麻烦可以试试,执行结果如下:
第三,Qpython可以实现爬取网页,放了一个爬取百度首页的代码。
有以下两点要做
-
安装requests模块,点击QPYPI->pip console->输入pip3 install requests
-
安装bs4模块,点击QPYPI->pip console->输入pip3 install bs4
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r=r.raise_for_status()
r.encoding="utf-8"
return r.text
except:
return ""
url="http://www.baidu.com"
print(getHTMLText(url))
import requests
from bs4 import BeautifulSoup
url="http://www.baidu.com"
r=requests.get(url)
r.encoding="utf-8"
soup=BeautifulSoup(r.text,"html.parser")
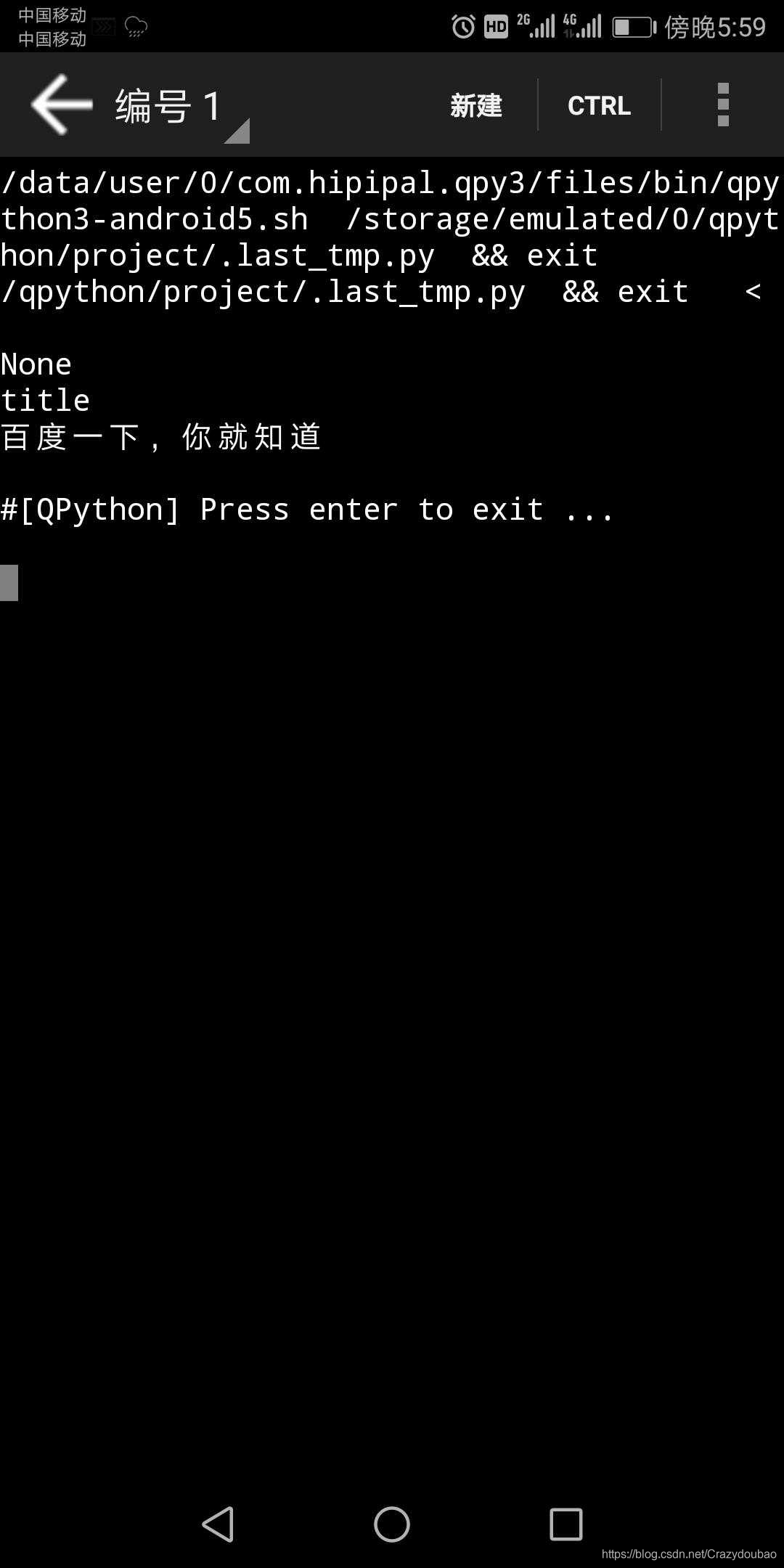
print(soup.title.arrts)
#输出标题属性
print(soup.title.name)
#输出标题名字
print(soup.title.string)
#输出标题的包含内容
这里犯了一个新手都犯的错误,文件名命名requests.py时,导致执行会报错,更改后OK。
执行结果如下:
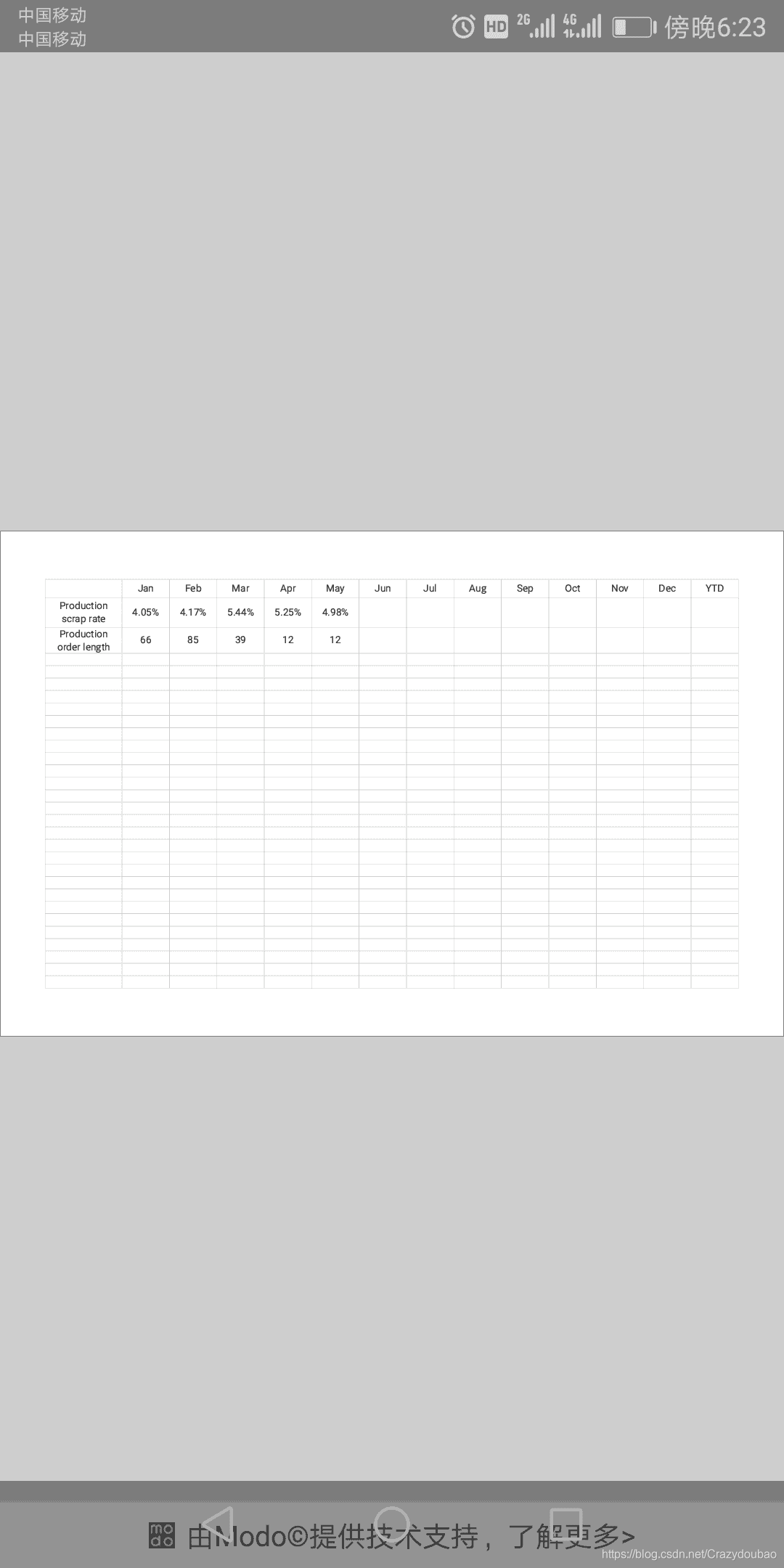
第四,Qpython可以操作Excel哦,先上代码。
import pandas as pd
#方法一:默认读取第一个表单
df=pd.read_excel('learning.xlsx',sheet_name='scraprate')
#这个会直接默认读取到这个Excel的第一个表单
data1=df.head()#默认读取前5行的数据
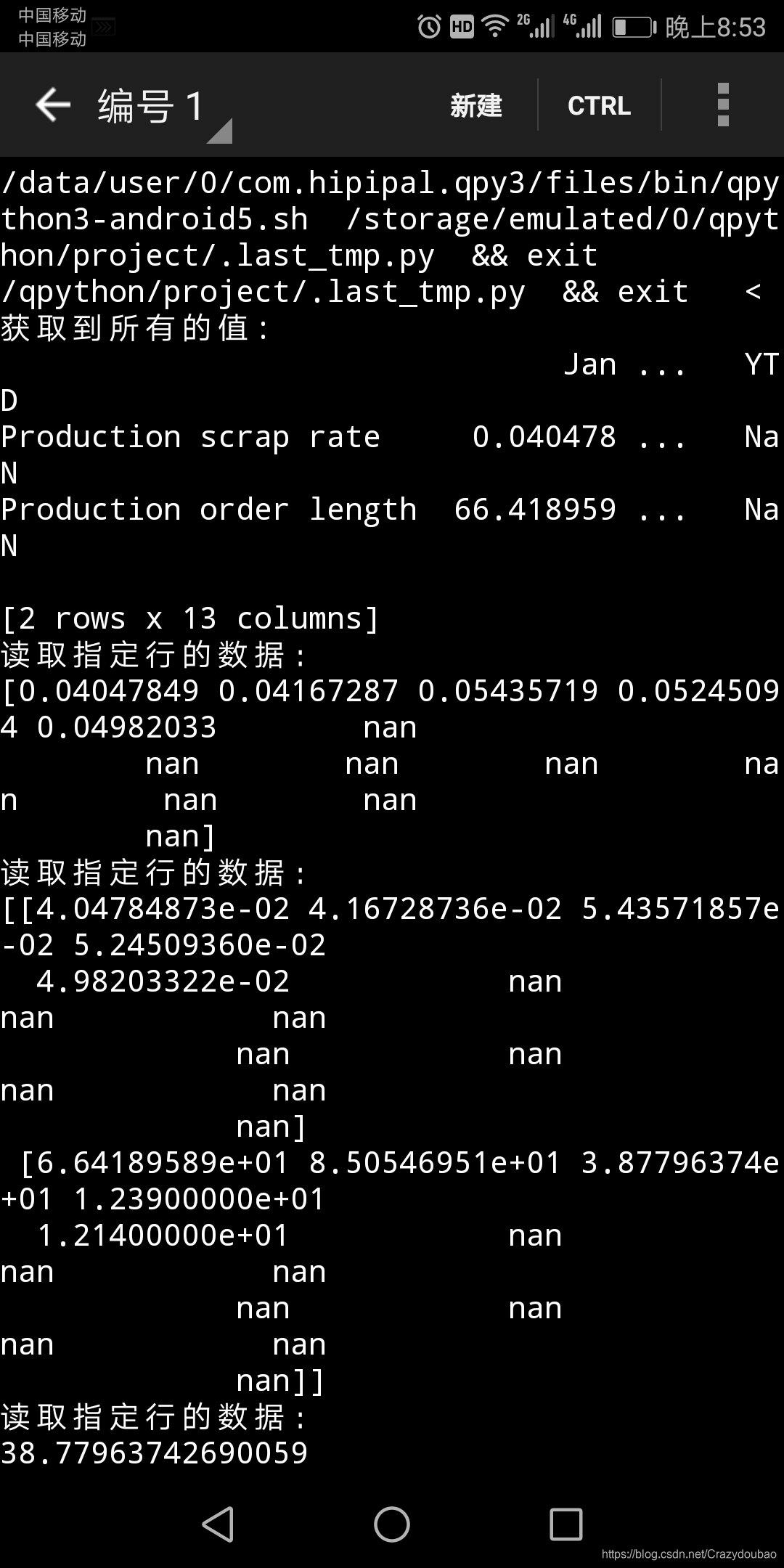
print("获取到所有的值:\n{0}".format(data1))
data2=df.ix[0].values#0表示第一行 这里读取数据并不包含表头,要注意哦!
print("读取指定行的数据:\n{0}".format(data2))
data3=df.ix[[0,1]].values#读取指定多行的话,就要在ix[]里面嵌套列表指定行数
print("读取指定行的数据:\n{0}".format(data3))
data4=df.ix[1,2]#读取第一行第二列的值,这里不需要嵌套列表
print("读取指定行的数据:\n{0}".format(data4))
data5=df.ix[[0,1],['Jan','Feb']].values#读取title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data5))
data=df.ix[:,['Jan','Feb']].values#读所有行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
print("输出行号列表",df.index.values)
print("输出列标题",df.columns.values)
print("输出值",df.sample(2).values)#这个方法类似于head()方法以及df.values方法
print("输出值\n",df['Jan'].values)
test_data=[]
for i in df.index.values:#获取行号的索引,并对其进行遍历:
#根据i来获取每一行指定的数据 并利用to_dict转成字典
row_data=df.ix[i,['Jan','Feb','Mar','Apr','May','Jun']].to_dict()
test_data.append(row_data)
print("最终获取到的数据是:{0}".format(test_data))
同样跟第三例子一样,导入pandas模块,执行结果如下:
放一个要用的Excel在如下文件夹
我会持续更新,加油!