Java Fork/Join框架
Fork/Join框架是一种能够并行执行任务支持并行编程方式的Java框架。如图1-1所示,这个框架通过递归将一个大任务分解成若干个并行执行的子任务,待到所有子任务都执行完成,再合并所有子任务结果,最终得到原大任务的结果。

图1-1 Fork/Join框架示意图
使用Fork/Join框架进行并行计算不仅简单高效而且具有良好的并行性能,Fork/Join并行算法的核心是分治算法的并行实现。
如图1-2所示,其中:fork操作是启动一个新的Fork/Join的并行子任务,而join操作则是等待所有子任务都执行完成。
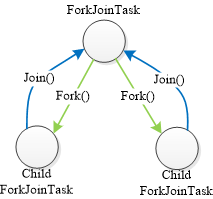
图1-2 fork、join操作关系图
Fork/Join框架首先它支持使用者自定义需要并行执行的基本子任务的粒度,并且直接通过编程就可以做到;其次Fork/Join在内部设计上使用双端队列+工作窃取的调度策略保证了每一个worker线程可以不断的窃取任务进行执行,从而提高系统资源的利用率,如图1-3所示。

图1-3 工作窃取示意图
Fork/Join框架不仅可以让使用者在执行并行任务时对需要并行执行的任务的细粒度进行控制,而且能够充分利用多核CPU、多线程来提高并行计算的能力,使程序员可以在保证并发执行任务的细粒度的同时,还能使程序获得更好的并行度。
Java Phaser工具类
在Java中Phaser是解决控制多线程执行多阶段任务时需要同步协调问题的一种“阶段器”。它类似于并行计算中的同步屏障,但比同步屏障多了一个阶段控制的功能,Phaser相比传统的同步栅栏更加灵活并且可复用,最主要还是其具备对在多任务并发执行时对不同阶段的任务进行控制的能力。
并行快速排序算法的设计
一、串行快速排序算法的描述
排序算法中的快速排序由C. A. R. Hoare在1960年提出,是一种通过数据比较对无序序列进行递归排序的算法。其基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
设待排序的序列(数组)为data[0]……data[length-1],首先任意选取一个元素(默认通常选取第一个元素data[0])作为基准数,然后将所有比基准数小的元素放置在基准数的前面,所有比基准数大的元素放在基准数的后面,由此以基准数最后所落位置i作为分界线,将序列分割成两个子序列(数组)data[0]……data[i-1]和data[i+1]……data[length-1]。这个过程称为一趟快速排序。
完整的快速排序算法通过对上述一趟快速排序过程进行反复的递归调用,最终实现对整个序列的排序。设一趟快速排序的过程为函数Partition(data, low, high),则完整的快速排序算法描述如下:
| public void Quicksort(int[] Data, int low, int high){ if(low < high){ i = Partition(data, low, high); Quicksort(data, low, i-1) Quicksort(data, i+1, high) } } |
二、并行快速排序算法的分析
根据上一节对串行快速排序算法的简述,我们接下来将挖掘串行快速排序算法其程序和数据的内在并行性:
(1)在Quicksort(data, low, high)函数中每一次递归调用时,其左序列和右序列分别对应的递归函数Quicksort(data, low, i-1)和Quicksort(data, i+1, high)所处理的序列数据之间不存在依赖性,因此这两次函数递归是可以同时进行的,由此将其递归的过程并行化,设计出一种基于任务划分的并行快速排序算法。
(2)对于超大的待排序序列,可以考虑对其数据集进行分解,分解成一个个较小的子数据集,再通过并行的方式对每个子数据集进行相同的快速排序操作,最后再合并所有子数据集以得到最终的排序结果,以此为理论基础设计出一种基于数据分解的并行快速排序算法。
两种并行快速排序算法的并行方式如表2-1所示,这两种并行算法不管是基于任务划分还是数据分解,其并行化的本质都是采用了分治法的思想。
表2-1 快速排序算法并行方式说明表
| 并行方式 |
说明 |
| 任务划分 |
不同的程序段由多个不同的线程实现 |
| 数据分解 |
多个线程对不同的数据块进行相同的处理 |
三、并行快速排序算法的设计
(1)基于任务划分的并行快速排序算法的设计。算法概要:基于任务划分的并行快速排序算法的程序会从一个线程开始启动排序,随着程序中每一次进行递归调用都会生成原来程序段数量的2的指数倍个新的执行排序的程序段,由于这些程序段所处理的数据之间不存在依赖关系,所以这些新的程序段可以被绑定在新的线程上,然后由不同线程在不同内核上并行执行,从而达到加快排序时间的效果。

基于任务划分的并行快速排序算法描述如下:
①设待排序数据集的数组为data,两个指针low和high表示对数组data从第low个元素到第high个元素(包括data[low]和data[high])进行排序,再建立一个forkJoinPool线程池,线程池默认线程数量为CPU核心数(可以自定义调整)。
②建立一个启动排序的任务QuickSortRecursiveAction,将data数组和low、high的值传递给任务QuickSortRecursiveAction。将QuickSortRecursiveAction提交到forkJoinPool线程池中开始执行排序。
对排序任务QuickSortRecursiveAction,当其被开始执行时,执行步骤如下:
(A)先判断low是否大于等于high,如果成立,则说明当前的排序任务已经结束(这是递归结束的标志),如果不成立,则开始执行排序任务。
(B)排序任务先对传入的data数组中第low个元素到第high个元素进行一趟快速排序并得到基准数位置i = Partition(data, low, high),再将任务基于基准数划分为左右两个子任务leftQuickSortRecursiveAction(data, low, i-1)和rightQuickSortRecursiveAction(data, i+1, high),将两个子任务使用fork()操作提交到forkJoinPool线程池中,线程池中有空闲线程会自动绑定子任务进行执行。
(C)从线程池开始执行排序任务QuickSortRecursiveAction直到线程池中所有线程不在活跃,说明所有任务全部执行完成,则任务完成。
(2)基于数据分解的并行快速排序算法的设计。算法概要:通过分析待排序数据的依赖关系,对待排序数据集进行数据分解,将待排序数据集分解成若干个规模大小相似的数据块,再把分解后的每一个数据块分配给不同的线程,所有线程并行执行排序,最后再对所有数据块两两进行归并,得出一个完整的有序数据集。

基于数据分解的并行快速排序算法描述如下:
①设待排序数据集的数组为data,数据个数为length,创建一个forkJoinPool线程池,设置线程池默认线程数量VariableLibrary.ThreadCount,默认为CPU核心的数量;再为每两个线程创建一个同步栅栏Phaser,一个同步栅栏绑定一个或两个线程,最后创建归并任务MergeRecursiveTask。
②对data数组进行数据分解,各线程先获取自己的线程号i和总线程数量no = VariableLibrary.ThreadCount,然后根据线程数量对data数组进行切片,将待排序数据集平均分割为相同个数的短序列,这些短序列的长度len为data.length/no,第i个序列为data[(i-1)×len+1, (i-1)×len+2, …, i×len],其中i = 1, 2, …, no。每个线程传入参数(data, (i-1)*length/no+1, i*length/no)开始执行串行快速排序算法。
③任意一个线程执行结束调用其对应Phaser的awaitAdvance(0)方法,表示本线程的第0阶段(快速排序)任务已经结束,等待第1阶段(归并)任务开始,每个Phaser对应的所有线程都调用了awaitAdvance(0)方法时,表示相邻的两个数据块已经排序完成,可以直接进行归并任务。
④将相邻的两个数据块的参数信息(a, b)传入归并任务MergeRecursiveTask中,当其被开始执行时,执行步骤如下:
新建一个数组newData,长度newData.length = a.length+b.length,将两个数据块对应的数组中的元素以顺序的排序方式归并到newData中,以此类推,两两归并,直到只有一个数据块时,归并任务结束。
⑤归并任务结束时调用Phaser的awaitAdvance(1)方法,则排序完成,返回排序结果newData。
并行快速排序算法的实现
快速排序并行求解系统的三种快速排序算法(传统的串行快速排序算法oldSort()、基于任务划分的并行快速排序算法newSort1()、基于数据分解的并行快速排序算法newSort2())实现代码如下:
package test.quicksort;
import test.Global.VariableLibrary;
import test.util.Util;
import java.util.Arrays;
import java.util.concurrent.*;
/**
* @program: myDemo
* @description: 快速排序算法
* @author: YOUNG
* @create: 2021-03-06 01:59
*/
public class SortUtil {
//ForkJoinPool线程池
private static ForkJoinPool forkJoinPool = null;
//数据分解时所需要的辅助空间
private static int[][] dataSet = null;
//同步栅栏,用于显示同步
private static Phaser[] mergePhaser = null;
/**
* 初始化ForkJoinPool线程池
* 以及数据分解时需要用到的临时存储空间和同步栅栏
*
* @param i 线程池数量
*/
public static void init(int i) {
forkJoinPool = new ForkJoinPool(i);
dataSet = new int[i][];
mergePhaser = new Phaser[i];
}
/**
* 传统的串行快速排序算法
*
* @param arr 待排序的数组
* @return 已排序好的数组
*/
public static int[] oldSort(int[] arr) {
return QuickSort(arr, 0, arr.length - 1);
}
public static int[] QuickSort(int[] a, int left, int right) {
//左边索引大于或者等于右边的索引就代表已经整理完成一组数据,递归结束
if (left >= right) {
//解决一个bug,return null
return null;
}
int i = left;
int j = right;
int key = a[left];
//组内一次找寻
while (i < j) {
/*寻找结束的条件:
1,找到一个小于或者大于key的数
2,没有符合条件1的,并且i与j的大小没有反转*/
while (i < j && key <= a[j]) {
//向前寻找
j--;
}
//交换a[i]和a[j]的数值
/*找到一个这样的数后就把它赋给前面的被拿走的i的值
(如果第一次循环且key是a[left],那么就是给key)*/
Swap(a, i, j);
//i在当组内向前寻找
while (i < j && key >= a[i]) {
i++;
}
Swap(a, i, j);
}
//组内回归中间数key
a[i] = key;
//左边分组递归
QuickSort(a, left, i - 1);
//右边分组递归
QuickSort(a, i + 1, right);
//i=j结束
return a;
}
/**
* 交换方法,交换数组中两个元素的值
*
* @param a 被操作的数组
* @param i 需要交换的元素的下标
* @param j 需要交换的另一个元素的下标
*/
private static void Swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
/**
* 基于任务划分的并行快速排序算法
*
* @param arr 待排序的数组
*/
public static void newSort1(int[] arr) {
forkJoinPool.execute(new concurrentQuickSort(arr, 0, arr.length - 1));
//隐含同步
do {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while (!forkJoinPool.isQuiescent());
}
/**
* 基于数据分解的并行快速排序算法
*
* @param arr 待排序的数组
* @return 已排序好的数组
*/
public static int[] newSort2(int[] arr) {
int len = arr.length / VariableLibrary.ThreadCount;
if (len == 0) {
return SortUtil.oldSort(arr);
}
int i;
int[] result = null;
for (i = 0; i < VariableLibrary.ThreadCount; i++) {
mergePhaser[i] = new Phaser();
}
for (i = 0; i < VariableLibrary.ThreadCount - 1; i++) {
forkJoinPool.execute(new oldQuickSort(arr, len * i, len * (i + 1) - 1, len, mergePhaser[i]));
}
forkJoinPool.execute(new oldQuickSort(arr, len * i, arr.length - 1, len, mergePhaser[i]));
final ForkJoinTask<int[]> submit = forkJoinPool.submit(new MyMerge(dataSet, 0, VariableLibrary.ThreadCount - 1));
try {
result = submit.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
return result;
}
private static class oldQuickSort extends RecursiveAction {
int[] data;
int start;
int end;
int len;
Phaser phaser;
public oldQuickSort(int[] data, int start, int end, int len, Phaser phaser) {
this.data = data;
this.start = start;
this.end = end;
this.len = len;
this.phaser = phaser;
phaser.register();
}
private oldQuickSort() {
}
@Override
protected void compute() {
SortUtil.QuickSort(data, start, end);
dataSet[start / len] = Arrays.copyOfRange(data, start, end + 1);
phaser.arrive();
}
}
private static class MyMerge extends RecursiveTask<int[]> {
int[][] dataSet;
int start;
int end;
private MyMerge() {
}
public MyMerge(int[][] dataSet, int start, int end) {
this.dataSet = dataSet;
this.start = start;
this.end = end;
}
@Override
protected int[] compute() {
if (end - start > 1) {
MyMerge myMerge1 = new MyMerge(dataSet, start, (start + end) / 2);
myMerge1.fork();
MyMerge myMerge2 = new MyMerge(dataSet, (start + end) / 2 + 1, end);
myMerge2.fork();
return Util.mergeArray(myMerge1.join(), myMerge2.join());
} else if (end == start) {
mergePhaser[start].awaitAdvance(0);
return dataSet[start];
} else {
mergePhaser[start].awaitAdvance(0);
mergePhaser[end].awaitAdvance(0);
return Util.mergeArray(dataSet[start], dataSet[end]);
}
}
}
private static class concurrentQuickSort extends RecursiveAction {
int[] a;
int left;
int right;
public concurrentQuickSort(int[] a, int left, int right) {
this.a = a;
this.left = left;
this.right = right;
}
private concurrentQuickSort() {
}
@Override
protected void compute() {
if (left >= right) {
return;
}
int i = left;
int j = right;
int key = a[left];
while (i < j) {
while (i < j && key <= a[j]) {
j--;
}
Swap(a, i, j);
while (i < j && key >= a[i]) {
i++;
}
Swap(a, i, j);
}
a[i] = key;
concurrentQuickSort leftConcurrentQuickSort = new concurrentQuickSort(a, left, i - 1);
leftConcurrentQuickSort.fork();
concurrentQuickSort rightConcurrentQuickSort = new concurrentQuickSort(a, i + 1, right);
rightConcurrentQuickSort.fork();
}
}
}
快速排序实验设计与结果分析
使用求解系统进行排序实验,实验主要分为两组:第一组实验对50,000,000(5000万)、100,000,000(1亿)、200,000,000(2亿)的随机(随机整数组成)序列进行排序;第二组实验对100,000(10万)、200,000(20万)、400,000(40万)的逆序(由大到小排列的整数组成)序列进行排序。
在每一组实验中都分别使用三种快速排序算法(传统的串行快速排序算法、基于任务划分的并行快速排序算法、基于数据分解的并行快速排序算法)对所有序列进行排序,对于并行的快速排序算法再通过修改线程数量(2个线程、4个线程、8个线程)进行对比实验。
最终记录每一组实验中每一次对序列进行排序的时间,计算并行算法程序的加速比以及并行效率。系统成功排序的结果是序列中数据(整数)由小到大排列。
两组实验一共需要进行42次排序求解,对比实验结果表明,基于数据分解的并行快速排序算法无论是对随机序列还是逆序序列进行排序求解都比串行快速排序算法在效率上都有着明显提高;基于任务划分的并行快速排序算法在对随机序列进行排序求解时,其效率也比串行快速排序算法高很多,但在对逆序序列进行排序求解时,其效率要低于串行快速排序算法,而且随着线程数量的增加,其效率不仅不提高反而越来越低。
(第一组实验)快速排序算法效果分析表
| 线程数量P 数据规模 并行方式 |
排序时间(s) |
并行加速比 |
并行效率(%) |
|||||||
| P=2 |
P=4 |
P=8 |
P=2 |
P=4 |
P=8 |
P=2 |
P=4 |
P=8 |
||
| 5000万 |
串行 |
6.810 |
||||||||
| 5000万 |
并行(任务划分) |
3.596 |
2.366 |
1.656 |
1.89 |
2.88 |
4.11 |
94.69 |
71.96 |
51.40 |
| 5000万 |
并行(数据分解) |
3.461 |
2.125 |
1.590 |
1.97 |
3.20 |
4.28 |
98.38 |
80.12 |
53.54 |
| 1亿 |
串行 |
11.657 |
||||||||
| 1亿 |
并行(任务划分) |
7.124 |
4.696 |
3.281 |
1.64 |
2.48 |
3.55 |
81.81 |
62.06 |
44.41 |
| 1亿 |
并行(数据分解) |
6.194 |
4.271 |
3.307 |
1.88 |
2.73 |
3.52 |
94.10 |
68.23 |
44.06 |
| 2亿 |
串行 |
24.335 |
||||||||
| 2亿 |
并行(任务划分) |
15.939 |
9.596 |
6.773 |
1.53 |
2.54 |
3.59 |
76.34 |
63.40 |
44.91 |
| 2亿 |
并行(数据分解) |
13.633 |
9.064 |
7.595 |
1.79 |
2.68 |
3.20 |
89.25 |
67.12 |
40.05 |
(第二组实验)快速排序算法效果分
| 线程数量P 数据规模 并行方式 |
排序时间(s) |
并行加速比 |
并行效率(%) |
|||||||
| P=2 |
P=4 |
P=8 |
P=2 |
P=4 |
P=8 |
P=2 |
P=4 |
P=8 |
||
| 10万 |
串行 |
1.333 |
||||||||
| 10万 |
并行(任务划分) |
1.427 |
1.531 |
1.549 |
0.93 |
0.87 |
0.86 |
46.71 |
21.77 |
10.76 |
| 10万 |
并行(数据分解) |
0.343 |
0.140 |
0.062 |
3.89 |
9.52 |
21.50 |
194.31 |
238.04 |
268.75 |
| 20万 |
串行 |
4.761 |
||||||||
| 20万 |
并行(任务划分) |
5.454 |
5.666 |
6.100 |
0.87 |
0.84 |
0.78 |
43.65 |
21.01 |
9.76 |
| 20万 |
并行(数据分解) |
1.303 |
0.515 |
0.204 |
3.65 |
9.24 |
23.34 |
182.69 |
231.12 |
291.73 |
| 40万 |
串行 |
18.908 |
||||||||
| 40万 |
并行(任务划分) |
20.730 |
21.291 |
22.318 |
0.91 |
0.89 |
0.85 |
45.61 |
22.20 |
10.59 |
| 40万 |
并行(数据分解) |
5.173 |
1.932 |
0.828 |
3.66 |
9.79 |
22.84 |
182.76 |
244.67 |
285.45 |

(随机序列)排序时间图

(逆序序列)排序时间图
 (随机序列)并行加速比图
(随机序列)并行加速比图
 (随机序列)并行效率图
(随机序列)并行效率图
在多核CPU中,以任务划分的方式进行的并行快速排序的并行加速比会随着线程数的增加而增加,数据规模越大,加速比增加得越快,而以数据分解的方式进行的并行快速排序的并行加速比虽然也随着线程数的增加而增加,但是当数据规模变大时,加速比增加趋势明显下降,这是因为基于数据分解的并行快速排序算法在其并行排序的第二大阶段(归并操作)时,为了两两归并子数据集,必须开辟一个临时存储空间用于存放归并好的临时子数据集,每一次归并操作中都会开辟一个临时存储空间。设线程数量为N 个,原始数据集大小为L,在整个归并阶段一共会并行执行N-1 次归并操作,在这期间总共开辟⌈log2N⌉×L![]() 大小的临时存储空间,所以当数据规模巨大时,开辟临时存储空间的时间已不能被忽略,最终会影响排序的效率,这也是其加速比上升趋势下滑的主要原因。
大小的临时存储空间,所以当数据规模巨大时,开辟临时存储空间的时间已不能被忽略,最终会影响排序的效率,这也是其加速比上升趋势下滑的主要原因。
两种并快速排序算法的并行效率都会随着线程数的增加而降低。但在小规模数据时,基于数据分解的并行快速排序算法的并行效率要高于基于任务划分的并行快速排序算法,但当增大数据规模时,基于数据分解的并行快速排序算法的并行效率下降趋势更明显,在当数据规模到达2亿时,其效率已经低于基于任务划分的并行快速排序算法,主要原因还是因为当数据规模巨大时,基于数据分解的并行快速排序算法需要开辟辅助存储空间巨大,开辟时间非常耗时,最终导致效率下降趋势明显。
 (逆序序列)并行加速比图
(逆序序列)并行加速比图
 (逆序序列)并行效率图
(逆序序列)并行效率图
在处理逆序序列时,基于任务划分的并行快速排序算法的并行加速比不仅一直小于1,而且随着线程数量的增加,其并行加速比反而越来越小,再结合(逆序序列)并行加速比图和逆序序列)并行效率图可以看出,基于任务划分的并行快速排序算法在处理逆序序列的情况下,所消耗的时间比串行快速排序算法要多,效率也不如串行快速排序算法。出现这一现象的原因是:快速排序算法是不稳定的。在正常情况下,设数据规模为n ,快速排序算法的平均时间复杂度和最好时间复杂度都是![]() ,但现在是使用快速排序算法对逆序序列进行排序,这时快速排序算法会退化成类似于冒泡排序的算法,这时其算法的最坏时间复杂度为
,但现在是使用快速排序算法对逆序序列进行排序,这时快速排序算法会退化成类似于冒泡排序的算法,这时其算法的最坏时间复杂度为![]() ,也就意味着算法的每一次递归都不再需要移动元素,即每一次递归时进行的一趟快速排序Partition(data, low, high)几乎不耗时,此时基于任务划分的并行快速排序算法将不再具有优势,因为每个并行执行的任务都是不耗时任务,几乎与串行执行没有多大差别,而且由于多线程之间的相互调度需要花费额外的时空开销,导致其不仅排序所花费的时间比串行快速排序算法多,其效率也不如串行快速排序算法,而且在随着线程数量的增加还会导致其线程之间相互调度的时空开销也增大,最终导致基于任务划分的并行快速排序算法的效率越来越低。
,也就意味着算法的每一次递归都不再需要移动元素,即每一次递归时进行的一趟快速排序Partition(data, low, high)几乎不耗时,此时基于任务划分的并行快速排序算法将不再具有优势,因为每个并行执行的任务都是不耗时任务,几乎与串行执行没有多大差别,而且由于多线程之间的相互调度需要花费额外的时空开销,导致其不仅排序所花费的时间比串行快速排序算法多,其效率也不如串行快速排序算法,而且在随着线程数量的增加还会导致其线程之间相互调度的时空开销也增大,最终导致基于任务划分的并行快速排序算法的效率越来越低。

快速排序时间复杂度图
但是对于逆序序列,基于数据分解的并行快速排序算法与基于任务划分的并行快速排序算法呈完全相反的效果。结合各图可以得知,基于数据分解的并行快速排序算法对逆序序列排序所用的时间远远小于另外两种快速排序算法。从10万数据规模开始,基于数据分解的并行快速排序算法的加速比就远超设定的线程数量,甚至最后超过了CPU的最高线程数,而其并行效率从一开始就已经大于100%,并且随着线程数量的增加,其效率和加速比呈爆炸式的增长,增长的趋势随着数据规模的扩大也只是稍稍下滑。出现这一反常的现象的主要原因是:对于逆序序列,无论是快速排序算法的平均时间复杂度Onlog2n![]() 和最好时间复杂度Onlog2n
和最好时间复杂度Onlog2n![]() 都不在适用,处理逆序序列是快速排序的最坏情况,这时快速排序算法的最坏时间复杂度为On2
都不在适用,处理逆序序列是快速排序的最坏情况,这时快速排序算法的最坏时间复杂度为On2![]() 。根据快速排序时间复杂度图可以看出,随着需要排序数据规模的增长,在最坏情况下快速排序所花费的时间呈指数倍增加。正是因为这一原因,基于数据分解的并行快速排序算法在最坏情况下,因为其在并行执行快速排序之前会对待排序列(数据集)进行分解,将一个大的序列分解成若干的规模较小的子序列,在分解的过程中大大降低了数据规模,并且这些子序列快速排序又是并行执行的,虽然上文提到当待排序数据集的数据规模超大时,其归并操作时开辟内存空间的时空开销不可忽略,但这和指数级增长的排序时间相比是微不足道的,所以基于数据分解的并行快速排序算法在处理逆序序列时会比串行快速排序算法的排序时间要少很多,甚至其并行加速比远超线程数量。
。根据快速排序时间复杂度图可以看出,随着需要排序数据规模的增长,在最坏情况下快速排序所花费的时间呈指数倍增加。正是因为这一原因,基于数据分解的并行快速排序算法在最坏情况下,因为其在并行执行快速排序之前会对待排序列(数据集)进行分解,将一个大的序列分解成若干的规模较小的子序列,在分解的过程中大大降低了数据规模,并且这些子序列快速排序又是并行执行的,虽然上文提到当待排序数据集的数据规模超大时,其归并操作时开辟内存空间的时空开销不可忽略,但这和指数级增长的排序时间相比是微不足道的,所以基于数据分解的并行快速排序算法在处理逆序序列时会比串行快速排序算法的排序时间要少很多,甚至其并行加速比远超线程数量。
快速排序实验结果的性能分析
 基于任务划分的并行快速排序CPU资源利用率图
基于任务划分的并行快速排序CPU资源利用率图
 基于数据分解的并行快速排序CPU资源利用率图
基于数据分解的并行快速排序CPU资源利用率图
 传统的串行快速排序CPU资源利用率图
传统的串行快速排序CPU资源利用率图
由传统的串行快速排序CPU资源利用率图可以看出,传统的快速排序算法在运行期间CPU资源利用率并未达到100%,并且只有一两个CPU内核在交替运行,其余CPU内核均被闲置。再看图5-8和图5-9,使用两种并行快速排序算法可以充分利用CPU资源,在排序过程中CPU资源利用率均达到了100%,所有CPU内核都被充分利用,但两者有些许差异:
在基于任务划分的并行快速排序CPU资源利用率图中,CPU的资源利用率在随着排序开始的上升过程和随着排序结束的下降过程中都是渐进的,这是因为基于任务划分的并行快速排序刚开始是只有一个排序任务,随着不断的划分,子任务不断增多,最终多个子任务并行执行,充分利用CPU资源,所以CPU资源利用率呈渐进上升趋势。而基于任务划分的并行快速排序的结束也因为每个子任务都是根据基准数来划分的,基准数的选取是具有不确定性的(第一个基准数除外,这里指第一个基准数之后的基准数选取都是不确定的),从而导致每个子任务的规模也是不一样的,所以排序结束过程中的每个子任务结束的时间都是不一样的,所以CPU的资源利用率呈渐进下降的趋势。
在基于数据分解的并行快速排序CPU资源利用率图中,可以发现CPU资源利用率在排序过程中存在一次下降再重新上升的趋势,这是因为基于数据分解的并行快速排序有两个过程阶段,在第二阶段归并过程开始之前有一个显示同步的操作用于线程之间两两相互等待,最终才能两两归并,所以这就可能会导致CPU中部分内核因为等待而空闲,CPU整体资源利用率下降,但最终第一阶段并行排序过程会完全结束,任务进入第二阶段,所有归并任务仍然是并行执行的,这时CPU资源利用率又会重新上升。
综上所述:基于任务划分和基于任务分解的两种并行快速排序算法均能发挥计算机处理器的100%性能,符合设计要求。