This article introduces the commonly used data import tools of HBase, and combines the common import scenarios of cloud HBase to give suggested migration tools and reference materials.
Common tools for importing data between HBase
HBase provides several data migration tools, among which are CopyTable, Export&Import based on API calls. Based on writing HDFS, there are distcp and snapshot.
What I want to explain here is that as a general introduction, this article cannot ignore the commonly used tools distcp and snapshot, but because the cloud HBase does not open the HDFS port by default, the HDFS-based methods on the cloud HBase are not available. We recommend that users use CopyTable for migration. According to our test, the performance of CopyTable is sufficient to support the migration of data below 10T. If your data volume is relatively large (more than 10T), you can contact the cloud HBase staff to handle it for you separately.
CopyTable
CopyTable is a data synchronization tool provided by HBase, which can be used to synchronize some or all of the data in the table. CopyTable reads data from the source table and writes it to the target table by running a Map-Reduce task.
CopyTable only needs to run one command, command example:
./bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable -Dhbase.client.scanner.caching=200 -Dmapreduce.local.map.tasks.maximum=16 -Dmapred.map.tasks.speculative.execution=false --peer.adr=$ZK_IP1,$ZK_IP2,$ZK_IP3:/hbase $TABLE_NAME
This article describes how to use CopyTable to synchronize HBase data. For users who do not have a Hadoop cluster, the configuration and parameters of running CopyTable on a single machine are also introduced. According to our test, when the table is not compressed, the stand-alone CopyTable can reach an import speed of about 100G in 1 hour. Data below 10T can be imported using CopyTable.
Ready to work
1. Installing HBase
CopyTable depends on hadoop mapreduce. If mapreduce is enabled in the source HBase cluster, it can be run directly on the source cluster. Otherwise, you can install the HBase client on another hadoop cluster and point the zk address in the hbase-site.xml file to the source cluster.
It can also be run on a stand-alone machine. When running on a stand-alone machine, there is no need to install Hadoop. As long as HBase is installed, you can use Hadoop's local mode to run CopyTable.
For the process of installing and configuring HBase, refer to https://help.aliyun.com/document_detail/52056.html?spm=a2c4e.11153940.blogcont176546.17.333c5579bR1Adg.
2. Create the target table
before using CopyTable to synchronize data, you need to ensure that the target table exists. If it does not exist, you need to create the target table first. It is strongly recommended to pre-split the target table according to the data distribution, which can improve the writing speed.
3. Other preparations
The IP of the machine running CopyTable needs to be added to HBase's IP whitelist to ensure that HBase can be accessed.
You need to modify the zk address in the hbase-site.xml file to point to the source cluster.
After the preparation work is completed, you can run CopyTable to synchronize data.
Command example
./bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable -Dhbase.client.scanner.caching=200 -Dmapreduce.local.map.tasks.maximum=16 -Dmapred.map.tasks.speculative.execution=false --peer.adr=$ZK_IP1,$ZK_IP2,$ZK_IP3:/hbase $TABLE_NAME
Parameter Description
The common options of CopyTable are as follows:
startrow 开始行。
stoprow 停止行。
starttime 时间戳(版本号)的最小值。
endtime 时间戳的最大值。如果不指定starttime,endtime不起作用。
peer.adr 目标集群的地址。格式为:hbase.zookeeer.quorum:hbase.zookeeper.client.port:zookeeper.znode.parent
families 要同步的列族。多个列族用逗号分隔。
all.cells 删除标记也进行同步。
For more parameters, please refer to the official document: http://hbase.apache.org/book.html#copy.table
除copytable的参数外, 以下选项也建议在命令中进行设置:
(1)对于单机运行的情况,需要指定mapreduce.local.map.tasks.maximum参数,表示并行执行的最大map个数。不指定的话默认是1,所有任务都是串行执行的。(2)hbase.client.scanner.caching建议设置为大于100的数。这个数越大,使用的内存越多,但是会减少scan与服务端的交互次数,对提升读性能有帮助。
(3)mapred.map.tasks.speculative.execution建议设置为false,避免因预测执行机制导致数据写两次。
另外,如果是在E-mapreduce集群上执行CopyTable,需要注意E-mapreduce默认的hbase-site.xml文件中配置了phoenix,所以需要导入phoenix的jar包,否则运行时会报错:
-libjars $HBASE_HOME/lib/phoenix-$PhoenixVersion-HBase-$HBaseVersion-server.jar
性能数据
我们使用两个云HBase集群来进行导入数据的测试。两个集群配置一致:3台region-server,机器配置为4CPU 8GB,数据盘为SSD云盘。源数据使用hbase pe产生,共16亿条数据,表采用SNAPPY压缩,数据文件大小为71.9GB,共有32个region。数据为单行单列,rowkey长度26字节,列长度100字节。
使用一台4CPU 8GB的ECS执行CopyTable,测试结果如下表:
| 测试轮次 | 测试条件 | 导入时间 | 导入速度(rec/s) | 导入速度(MB/s) |
|---|---|---|---|---|
| 1 | -Dhbase.client.scanner.caching=100 -Dmapreduce.local.map.tasks.maximum=16 | 1h21min | 329218 | 15.15 |
| 2 | 在测试1的基础上修改-Dhbase.client.scanner.caching=500 | 1h14min | 360360 | 16.58 |
| 3 | 在测试2的基础上按照源表数据分布对目标表进行预分裂再进行导入 | 1h5min | 410256 | 18.88 |
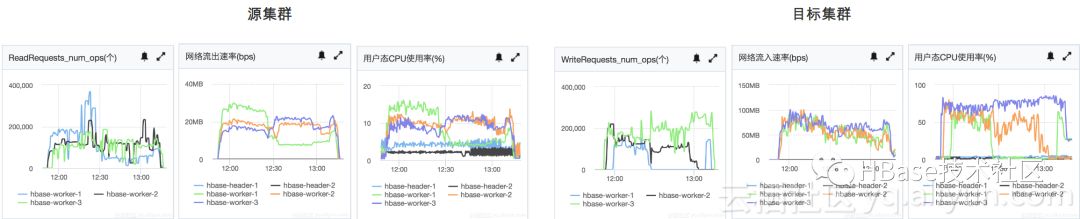
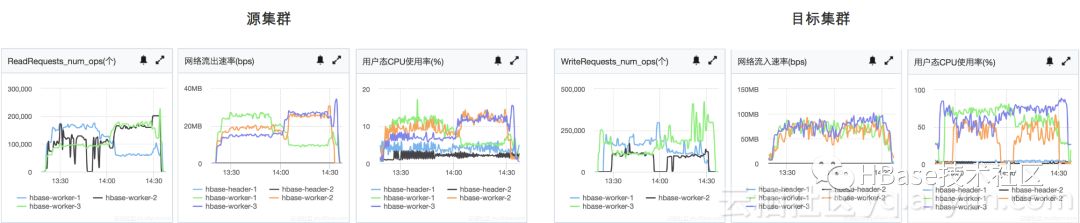
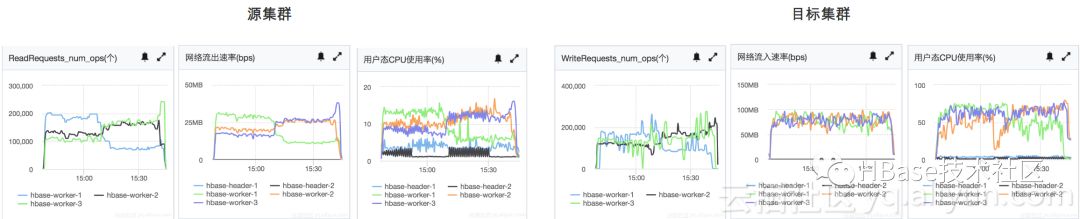
测试过程中的相关监控如下:
测试1
测试2
测试3
Export&Import
Export将HBase表内容dump到一个顺序文件(sequence)中。Import将Export得到的顺序文件内容写入HBase表。和CopyTable一样,Export和Import也是通过运行map-reduce任务来执行的。
Export和Import命令格式:
bin/hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]]
bin/hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
distcp
distcp是Hadoop提供的用于复制HDFS文件的工具,经常也被用来同步HBase数据。
使用distcp进行数据同步的步骤如下:
(1)源集群停止写入。
(2)将数据文件复制到目标集群上。运行
hadoop distcp $SrcFilePath $DstFilePath
(3)然后在目标集群上执行
hbase hbck -fixAssignments -fixMeta
snapshot
HBase snapshot可以在对region-server影响很小的情况下创建快照、将快照复制到另一个集群。
使用snapshot迁移数据的操作步骤如下:
(1)在源表上创建snapshot。
hbase snapshot create -n $SnapshotName -t $TableName
(2)将snapshot拷贝到目标集群的HDFS上。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot $SnapshotName -copy-from $SrcSnapshotPath -copy-to $DstSnapshotPath
(3)在目标集群恢复snapshot。在hbase shell中执行
restore_snapshot '$SnapshotName'
异构数据导入HBase常用工具
其他类型数据向HBase导入常见的工具有:
(1)关系数据库可以使用Sqoop导入。
(2)其他类型数据可以使用DataX。
(3)如果是周期性数据导入需求,可以使用数据集成。
Sqoop
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具。Sqoop的数据同步也是通过map-reduce实现的。
使用Sqoop同步数据只需要运行一个命令即可,命令示例:
sqoop import -Dmapreduce.local.map.tasks.maximum=8 --connect jdbc:mysql://$mysqlURL:3306/$database --table $table --hbase-table $hbaseTable --column-family $columnFamily --hbase-row-key $mysqlColumn --username $mysqlUser -m 8 -P
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具。本文介绍如何使用sqoop将数据从Mysql导入到HBase。从成本的角度考虑,针对没有hadoop集群的用户,重点介绍单机运行sqoop的配置和参数。
安装
要完成从MyDW向HBase导入数据的任务,需要安装和配置的软件包括hadoop,sqoop,mysql-connector和HBase。我们针对单机运行sqoop的情况提供了四合一的安装包简化安装流程。如果是在hadoop集群上运行sqoop,可以参考Sqoop官方文档进行配置。
以下介绍单机版的安装流程。
1.下载安装包。把文件放在~目录。
cd ~
wget http://public-hbase.oss-cn-hangzhou.aliyuncs.com/installpackage/sqoop-all.tar.gz
2.解压文件:解压,进入解压后的目录sqoop-all。
tar -xzvf sqoop-all.tar.gzcd scoop-all
3.设置环境变量。
cp sqoop-env.sh /etc/profile.d; source /etc/profile
4.修改hbase-1.1.9/conf/hbase-site.xml文件,添加集群的 ZK 地址。可参考云HBase帮助文档:https://help.aliyun.com/document_detail/52056.html?spm=a2c4e.11153940.blogcont176524.13.1c1ba954n0tDas
准备工作
1.设置ip白名单。需要把运行sqoop的机器ip添加到云HBase的ip白名单中。如果Mysql是云上的RDS,也需要修改RDS的ip白名单。总之就是保证这台机器能够访问mysql和HBase。
2.确保目标表存在。如果不存在需要先建表。
运行
安装完成并配置好ip白名单之后,就可以运行sqoop进行数据导入了。
命令示例
以下是单机运行sqoop的命令示例:
sqoop import -Dmapreduce.local.map.tasks.maximum=8 --connect jdbc:mysql://$mysqlURL:3306/$database --table $table --hbase-table $hbaseTable --column-family $columnFamily --hbase-row-key $mysqlColumn --username $mysqlUser -m 8 -P
常用参数说明
--connect JDBC连接字符串
--table 要导入的mysql表名
--columns 要导入的列
--where 过滤条件
--hbase-table hbase表名
--column-family hbase列族
--hbase-row-key 用来做HBase rowkey的mysql列名
--username mysql用户名
-m map个数,默认为4
此外,对于单机运行,还需要指定mapreduce.local.map.tasks.maximum参数,表示并行执行的最大map个数,否则默认为1,map就变成串行执行的了。也可以根据需要调整其他hadoop参数。
sqoop import的其他参数可参考[sqoop-import文档](
http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_literal_sqoop_import_literal)。
公网运行
一般来说,我们不建议在公网执行数据同步任务,因为可能会有潜在的安全隐患以及绕行公网带来的延时增大、性能问题等。但是考虑到开发测试阶段的便利,HBase也提供了公网访问的功能,我们可以通过配置HBase公网访问实现在公网运行数据同步任务。
开通公网访问
开通公网访问的方法参见公网访问方案。
公网访问需要使用阿里云定制的客户端,具体的下载和配置参见使用 Shell 访问。
完成后,如果能通过hbase shell访问,就说明这一步的配置已经成功了。
修改sqoop环境变量
sqoop环境变量中和HBase相关的环境变量主要是HBASE_HOME,需要把这个变量改成阿里云定制客户端所在的目录。运行vi sqoop-en.sh,修改如下内容:
#export HBASE_HOME=~/sqoop-all/hbase-1.1.9 注释这一行,替换成:
export HBASE_HOME=~/sqoop-all/alihbase-1.1.4 #改成阿里云客户端所在的目录
然后
cp sqoop-env.sh /etc/profile.d; source /etc/profile
环境变量生效之后,就可以在公网执行导入操作了。
DataX
DataX 是广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
使用DataX进行数据同步的步骤如下:
(1)编写作业的配置文件。配置文件为json格式,具体格式可参考这里:
https://github.com/alibaba/DataX
(2)运行DataX。执行命令
python datax.py $config.json
DataX的使用参考官方文档:https://github.com/alibaba/DataX/wiki/Quick-Start?spm=a2c4e.11153940.blogcont178446.21.dacd1078SCL03L
数据集成
数据集成是阿里集团对外提供的的数据同步平台,其底层也基于DataX。由于数据集成提供了调度的功能,所以很适合用于周期性导入数据或是与其他任务有依赖关系的情况。
使用数据集成同步数据的步骤较复杂,具体请参考这里:
https://yq.aliyun.com/articles/165981?spm=a2c4e.11153940.blogcont178446.22.dacd1078SCL03L
云HBase数据迁移指南
| 场景 | 建议迁移工具 | 参考资料 |
|---|---|---|
| HBase->HBase,数据量<10T | CopyTable | 使用CopyTable同步HBase数据: https://yq.aliyun.com/articles/176546?spm=a2c4e.11153940.blogcont178446.23.dacd1078SCL03L |
| HBase->HBase,数据量>10T | 联系云HBase工作人员处理 | |
| HBase经典网络集群迁移到vpc网络 | 使用ClassicLink打通网络。迁移工具参考具体场景 | HBase经典网络集群迁移到vpc网络: https://yq.aliyun.com/articles/328405?spm=a2c4e.11153940.blogcont178446.24.dacd1078SCL03L |
| 关系型数据库->HBase | Sqoop | 使用Sqoop从MySQL向云HBase同步数据: https://yq.aliyun.com/articles/176524?spm=a2c4e.11153940.blogcont178446.25.dacd1078SCL03L |
| 其他类型数据源一次性导入HBase | DataX | DataX官方文档: https://github.com/alibaba/DataX/wiki/Quick-Start?spm=a2c4e.11153940.blogcont178446.26.dacd1078SCL03L |
| 导入Phoenix表 | Datax | HBase11xsqlwriter插件文档: https://github.com/alibaba/DataX/blob/master/hbase11xsqlwriter/doc/hbase11xsqlwriter.md?spm=a2c4e.11153940.blogcont178446.27.dacd1078SCL03L&file=hbase11xsqlwriter.md |
| 其他类型数据源周期性导入HBase | 数据集成 | step-by-step通过数据集成同步数据到HBase 数据集成概述: https://yq.aliyun.com/articles/165981?spm=a2c4e.11153940.blogcont178446.28.dacd1078SCL03L |
